利用pandas进行数据清洗的方法
我们有下面的一个数据,利用其做简单的数据分析。
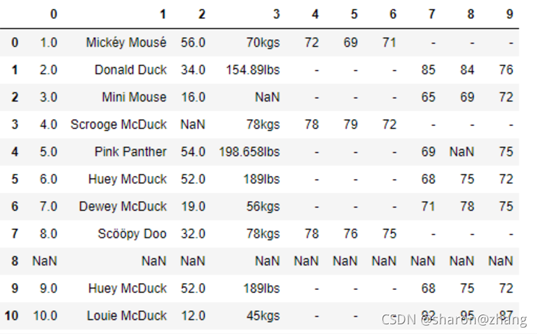
这是一家服装店统计的会员数据。最上面的一行是列坐标,最左侧一列是行坐标。列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸。
数据清洗规则总结为以下 4 个关键点,统一起来叫“完全合一”,下面来解释下:
- 完整性:单条数据是否存在空值,统计的字段是否完善。
- 全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
- 合法性:数据的类型、内容、大小的合法性。比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。
- 唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
1、完整性
1.1 缺失值
一般情况下,由于数据量巨大,在采集数据的过程中,会出现有些数据单元没有被采集到,也就是数据存在缺失。通常面对这种情况,我们可以采用以下三种方法:
- 删除:删除数据缺失的记录
- 均值:使用当前列的均值填充
- 高频:使用当前列出现频率最高的数据
比如我们相对data[‘Age']中缺失的数值使用平均年龄进行填充,可以写:
df['Age'].fillna(df['Age'].mean(), inplace=True)
如果我们用最高频的数据进行填充,可以先通过 value_counts 获取 Age 字段最高频次 age_maxf,然后再对 Age 字段中缺失的数据用 age_maxf 进行填充:
age_maxf = train_features['Age'].value_counts().index[0] train_features['Age'].fillna(age_maxf, inplace=True)
1.2 空行
我们发现数据中有一个空行,除了 index 之外,全部的值都是 NaN。Pandas 的 read_csv() 并没有可选参数来忽略空行,这样,我们就需要在数据被读入之后再使用 dropna() 进行处理,删除空行。
# 删除全空的行 df.dropna(how='all',inplace=True)
2、全面性
列数据的单位不统一
如果某一列数据其单位并不统一,比如weight列,有的单位为千克(Kgs),有的单位是磅(Lbs)。
这里我们使用千克作为统一的度量单位,将磅转化为千克:
# 获取 weight 数据列中单位为 lbs 的数据
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
print df[rows_with_lbs]
# 将 lbs转换为 kgs, 2.2lbs=1kgs
for i,lbs_row in df[rows_with_lbs].iterrows():
# 截取从头开始到倒数第三个字符之前,即去掉lbs。
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
3、合理性
非ASCII字符
假设在数据集中 Firstname 和 Lastname 有一些非 ASCII 的字符。我们可以采用删除或者替换的方式来解决非 ASCII 问题,这里我们使用删除方法,也就是用replace方法:
# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
4、唯一性
4.1 一列有多个参数
假设姓名(Name)包含了两个参数 Firstname和Lastname。为了达到数据整洁的目的,我们将 Name 列拆分成 Firstname 和 Lastname 两个字段。我们使用 Python 的 split 方法,str.split(expand=True),将列表拆成新的列,再将原来的 Name 列删除。
# 切分名字,删除源数据列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
4.2 重复数据
我们校验一下数据中是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据。
# 删除重复数据行 df.drop_duplicates(['first_name','last_name'],inplace=True)
这样,我们就将上面案例中中的会员数据进行了清理,来看看清理之后的数据结果。

到此这篇关于利用pandas进行数据清洗的方法的文章就介绍到这了,更多相关pandas 数据清洗内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
pandas pd.read_csv()函数中parse_dates()参数的用法说明
这篇文章主要介绍了pandas pd.read_csv()函数中parse_dates()参数的用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-05- 今天小编就为大家分享一篇Pandas实现DataFrame按行求百分数(比例数),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-05-09
- 本文主要介绍了python使用pandas按照行数分割表格,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-08-13
- 这篇文章主要介绍了解决python3安装pandas出错的问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-05-20
- 比较操作是很简单的基础知识,不过Pandas中的比较操作有一些特殊的点,本文介绍的非常详细,对正在学习python的小伙伴们很有帮助.需要的朋友可以参考下...2021-05-20
- 这篇文章主要介绍了用pandas划分数据集实现训练集和测试集,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-07-20
- 这篇文章主要介绍了pandas 实现将两列中的较大值组成新的一列,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-26
- pandas 读取excel文件使用的是 read_excel方法。本文将详细解析read_excel方法的常用参数,以及实际的使用示例,感兴趣的朋友跟随小编一起看看吧...2021-11-01
解决python pandas读取excel中多个不同sheet表格存在的问题
这篇文章主要介绍了解决python pandas读取excel中多个不同sheet表格存在的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-07-14- 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章。本节主要记录Pandas中使用stack和pivot实现数据透视。感兴趣的小伙伴们可以参考一下...2021-09-05
Pandas.DataFrame转置的实现 <font color=red>原创</font>
这篇文章主要介绍了Pandas.DataFrame转置的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-09- 这篇文章主要介绍了对python pandas中 inplace 参数的理解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-06-28
- 这篇文章主要介绍了pandas 实现某一列分组,其他列合并成list的案例。具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-26
- 今天给大家带来的是关于Python的相关知识,文章围绕着Pandas常用函数方法展开,文中有非常详细的介绍及代码示例,需要的朋友可以参考下...2021-06-16
- 这篇文章主要介绍了python 用pandas实现数据透视表功能的方法,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下...2020-12-21
- 今天小编就为大家分享一篇Pandas 解决dataframe的一列进行向下顺移问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-05-09
- 这篇文章主要介绍了基于pandas向csv添加新的行和列,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-05-26
- 这篇文章主要介绍了快速解释如何使用pandas的inplace参数的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-07-23
- 时间偏移就是在指定时间往前推或者往后推一段时间,即加减一段时间之后的时间,本文使用Python实现,感兴趣的可以了解一下...2021-08-08
pandas中DataFrame数据合并连接(merge、join、concat)
这篇文章主要给大家介绍了关于pandas中DataFrame 数据合并连接(merge、join、concat)的相关资料,文中介绍的非常详细,需要的朋友可以参考下...2021-05-30