Python中scrapy下载保存图片的示例
在日常爬虫练习中,我们爬取到的数据需要进行保存操作,在scrapy中我们可以使用ImagesPipeline这个类来进行相关操作,这个类是scrapy已经封装好的了,我们直接拿来用即可。

在使用ImagesPipeline下载图片数据时,我们需要对其中的三个管道类方法进行重写,其中 — get_media_request 是对图片地址发起请求
— file path 是返回图片名称
— item_completed 返回item,将其返回给下一个即将被执行的管道类

那具体代码是什么样的呢,首先我们需要在pipelines.py文件中,导入ImagesPipeline类,然后重写上述所说的3个方法:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
import os
class ImgsPipLine(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(url = item['img_src'],meta={'item':item})
#返回图片名称即可
def file_path(self, request, response=None, info=None):
item = request.meta['item']
print('########',item)
filePath = item['img_name']
return filePath
def item_completed(self, results, item, info):
return item
方法定义好后,我们需要在settings.py配置文件中进行设置,一个是指定图片保存的位置IMAGES_STORE = 'D:\\ImgPro',然后就是启用“ImgsPipLine”管道,
ITEM_PIPELINES = {
'imgPro.pipelines.ImgsPipLine': 300, #300代表优先级,数字越小优先级越高
}
设置完成后,我们运行程序后就可以看到“D:\\ImgPro”下保存成功的图片。
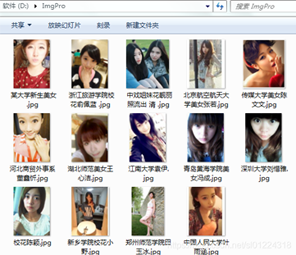
完整代码如下:
spider文件代码:
# -*- coding: utf-8 -*-
import scrapy
from imgPro.items import ImgproItem
class ImgSpider(scrapy.Spider):
name = 'img'
allowed_domains = ['www.521609.com']
start_urls = ['http://www.521609.com/daxuemeinv/']
def parse(self, response):
#解析图片地址和图片名称
li_list = response.xpath('//div[@class="index_img list_center"]/ul/li')
for li in li_list:
item = ImgproItem()
item['img_src'] = 'http://www.521609.com/' + li.xpath('./a[1]/img/@src').extract_first()
item['img_name'] = li.xpath('./a[1]/img/@alt').extract_first() + '.jpg'
# print('***********')
# print(item)
yield item
items.py文件
import scrapy
class ImgproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_src = scrapy.Field()
img_name = scrapy.Field()
pipelines.py文件
from scrapy.pipelines.images import ImagesPipeline
import scrapy
import os
from imgPro.settings import IMAGES_STORE as IMGS
class ImgsPipLine(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(url = item['img_src'],meta={'item':item})
#返回图片名称即可
def file_path(self, request, response=None, info=None):
item = request.meta['item']
print('########',item)
filePath = item['img_name']
return filePath
def item_completed(self, results, item, info):
return item
settings.py文件
import random
BOT_NAME = 'imgPro'
SPIDER_MODULES = ['imgPro.spiders']
NEWSPIDER_MODULE = 'imgPro.spiders'
IMAGES_STORE = 'D:\\ImgPro' #文件保存路径
LOG_LEVEL = "WARNING"
ROBOTSTXT_OBEY = False
#设置user-agent
USER_AGENTS_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
USER_AGENT = random.choice(USER_AGENTS_LIST)
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
# 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
'User-Agent':USER_AGENT
}
#启动pipeline管道
ITEM_PIPELINES = {
'imgPro.pipelines.ImgsPipLine': 300,
}
以上即是使用ImagesPipeline下载保存图片的方法,今天突生一个疑惑,爬虫爬的好,真的是牢饭吃的饱吗?还请各位大佬解答!更多相关Python scrapy下载保存内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 这篇文章主要介绍了python-opencv-画外接矩形框的实例代码,代码简单易懂,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-09-04
Python astype(np.float)函数使用方法解析
这篇文章主要介绍了Python astype(np.float)函数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-06-08- 2022虎年新年即将来临,小编为大家带来了一个利用Python编写的虎年烟花特效,堪称全网最绚烂,文中的示例代码简洁易懂,感兴趣的同学可以动手试一试...2022-02-14
- 在本篇文章里小编给大家分享的是一篇关于python中numpy.empty()函数实例讲解内容,对此有兴趣的朋友们可以学习下。...2021-02-06
- 这篇文章主要介绍了C#从数据库读取图片并保存的方法,帮助大家更好的理解和使用c#,感兴趣的朋友可以了解下...2021-01-16
python-for x in range的用法(注意要点、细节)
这篇文章主要介绍了python-for x in range的用法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-10- 这篇文章主要介绍了Python 图片转数组,二进制互转操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-09
- 这篇文章主要介绍了Python中的imread()函数用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-16
- 这篇文章主要介绍了python如何实现b站直播自动发送弹幕,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下...2021-02-20
python Matplotlib基础--如何添加文本和标注
这篇文章主要介绍了python Matplotlib基础--如何添加文本和标注,帮助大家更好的利用Matplotlib绘制图表,感兴趣的朋友可以了解下...2021-01-26- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- 这篇文章主要介绍了C#实现HTTP下载文件的方法,包括了HTTP通信的创建、本地文件的写入等,非常具有实用价值,需要的朋友可以参考下...2020-06-25
- 今天小编就为大家分享一篇python 计算方位角实例(根据两点的坐标计算),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 这篇文章主要为大家详细介绍了python实现双色球随机选号,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-05-02
- 在本篇文章里小编给大家整理的是一篇关于python中使用np.delete()的实例方法,对此有兴趣的朋友们可以学习参考下。...2021-02-01
- 这篇文章主要介绍了使用Python的pencolor函数实现渐变色功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-09
- 这篇文章主要介绍了python自动化办公操作PPT的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-05
Python getsizeof()和getsize()区分详解
这篇文章主要介绍了Python getsizeof()和getsize()区分详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-20- 这篇文章主要介绍了解决python 两个时间戳相减出现结果错误的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-12
- 这篇文章主要为大家详细介绍了python实现学生通讯录管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-25