Python爬虫实战之用selenium爬取某旅游网站
一、selenium实战
这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的
二、打开艺龙网
可以直接点击这里进入:艺龙网
这里是主页
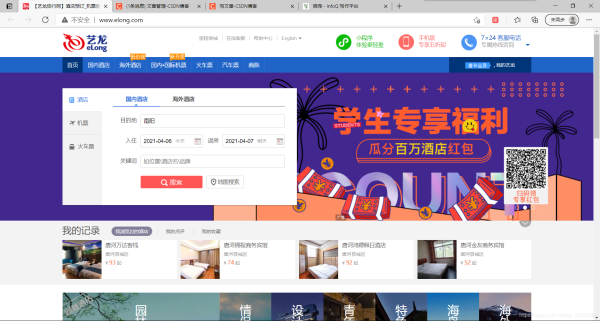
三、精确目标
我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢?
打开pycharm,新建一个叫做艺龙网的py文件,先导包:
from selenium import webdriver
import time # 导包
driver = webdriver.Chrome() # 创建一个selenium的对象
driver.get("http://www.elong.com/")
time.sleep(1) # 打开网站,并让它睡1s,避免渲染未完成就进行下一步操作
driver.maximize_window() # 将浏览器最大化
怎么找到搜索框呢,有很多方法,xpath,css,JavaScript,jQuery,,,因为xpath简单,所以我们只使用xpath,因为这个网站也是可以用xpath的,具体步骤是:
1.F12,小箭头,点击搜索框
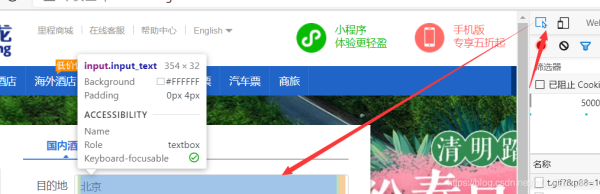
2.点击后,找到元素中的位置,右键,复制,复制xpath
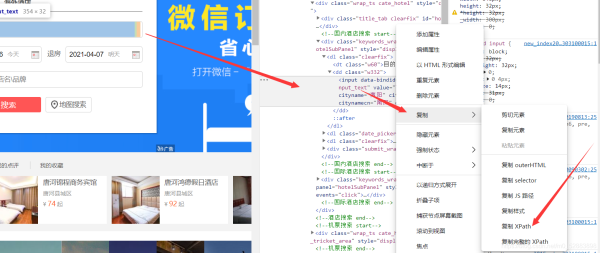
3.进入pycharm中,在之前创建的py文件中添加如下代码
driver.find_element_by_xpath('//*[@id="domesticDiv"]/dl[1]/dd/input').clear()
# 将搜索框中的内容清理
4.在搜索框添加“鹤壁市”
driver.find_element_by_xpath('//*[@id="domesticDiv"]/dl[1]/dd/input').send_keys('鹤壁市')
5.点击搜索,进入下一页
time.sleep(1)
driver.find_element_by_xpath('//*[@id="hotel_sub_tabs"]/span[1]/b').click() # 点击无关
time.sleep(1) # 避免渲染不及时导致报错
driver.find_element_by_xpath('//*[@id="domesticDiv"]/div/span[1]').click() # 点击搜索
6.下一页
此时我们绝望的发现,这些操作都是没用的(对这个网站没用,但是至少我们学到了点知识?)她还是北京
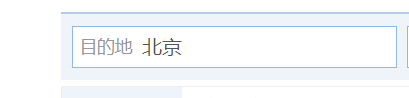
所以我们只能这样做了
直接点击搜索,进入这个页面后再输入鹤壁(那干嘛不直接访问这个网页呢?为了我这该死的仪式感!!)这样做,再那样做,就行了
from selenium import webdriver
import time # 导包
driver = webdriver.Chrome() # 创建一个selenium的对象
driver.get("http://www.elong.com/")
time.sleep(1) # 打开网站,并让它睡1s,避免渲染未完成就进行下一步操作
driver.maximize_window() # 将浏览器最大化
driver.find_element_by_xpath('//*[@id="domesticDiv"]/div/span[1]').click() # 点击搜索
driver.find_element_by_xpath('//*[@id="m_searchBox"]/div[1]/label/input').clear() # 清空搜索框内容
driver.find_element_by_xpath('//*[@id="m_searchBox"]/div[1]/label/input').send_keys('鹤壁市') # 在搜索框输入 鹤壁市
time.sleep(1)
driver.find_element_by_xpath('//*[@id="sugContent"]/ul/li[1]/div/div[1]/div[1]/span/b').click() # 鹤壁市
time.sleep(1)
# 只是改变了顺序,并更换了xpath语法
然后就成功的定位到了鹤壁市
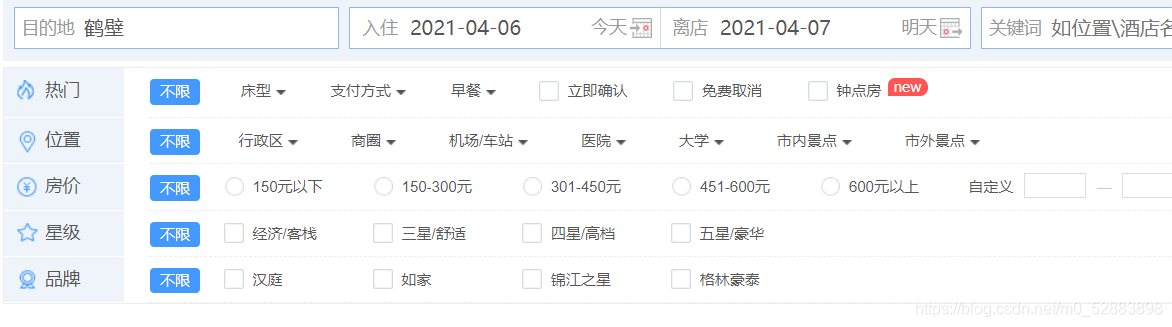
8.分析网页,找到详情页的url
我们可以这样做
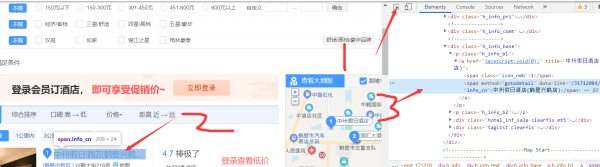
我们发现,这个详情页每个的xpath都不相同,怎么做到把所有详情页都“照顾”得到呢?看来只能请出我们的requests来了,然后我们发现,这个只是一段URL,那怎么办?拼接咯!
9.通过查看响应,我们知道响应和元素是一样的,那么说明什么?我们可以通过xpath提取到我们的元素,直接请出我们的xpath选手。
from lxml import etree
import re
html_data = driver.page_source # 将数据存入html_data
ht = ht_ht.xpath('//div[@class="to_detail"]/a/@data-link') # 提取到url的后半段
10.拼接字符串形成新URL
点进去一个详情页查看URL,发现是这样的

研究发现,将?issugtrace=2删去也可以运行,而我们通过xpath取到的正是后面的 /31712004/,所以:
for ur in ht:
new_ul = 'http://www.elong.com' + ur
11.取到详情页URL后,就要点进去,然后再分析网页,再提取数据,然后存数据,找xpath的我就先不说了,也不难。
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
}
for ur in ht:
new_ul = 'http://www.elong.com' + ur
xiangqing_ht = requests.get(new_ul, headers=head).content.decode()
# 使用requests
time.sleep(1) # 睡1s
ht_data = etree.HTML(xiangqing_ht) # 转为可使用xpath的HTML格式
tingche = ht_data.xpath('//*[@id="hotelContent"]/div/dl[4]/dd/text()') # 停车位
if tingche == []:
tingche = '无停车位'
name = ht_data.xpath('/html/body/div[3]/div/div[1]/div[1]/div/h1/text()')[0] # 酒店名字
phine_num = ht_data.xpath('//*[@id="hotelContent"]/div/dl[1]/dd/span/text()') # 电话
photo_li = ht_data.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/ul[1]/li/img/@src') # 照片
weizhi = ht_data.xpath('//*[@id="map"]/div[1]/div[2]/div[1]/div/div[9]/div[2]/div/p[2]/text()') # 位置
miaoshu = ht_data.xpath('//*[@id="hotelContent"]/div/dl[1]/dd/ul/li[2]/div/p/span[1]/text()')
然后我们就拿到了数据,接下来,这些数据怎么保存呢?可以使用字典保存到json中。我就接着上面的写了
dic = {} # 使用字典进行json存储
ic[f"{name}"] = {}
dic[f"{name}"][f"{name}停车场"] = tingche
dic[f"{name}"][f"{name}电话"] = phine_num
dic[f"{name}"][f"{name}位置"] = weizhi
dic[f"{name}"][f"{name}描述"] = miaoshu
path = f"酒店数据//{name}"
if not os.path.exists(path):
os.mkdir(path)
# 创建酒店文件夹
for num, photo in zip(range(len(photo_li)), photo_li):
if num > 4:
break
else:
with open(f'酒店数据//{name}//{name, num + 1}.jpg', 'wb') as f:
f.write(requests.get(photo).content) # 将照片存进本地
with open(f"酒店数据//{name}//酒店数据.json", 'w') as f:
f.write(str(dic)) # 将json存入文件
dic = {} # 将字典内的数据清楚,留待下一次循环使用
12.数据拿到之后,还没完,我们还要爬下一页,首先需要把主页滑倒最底部
for i in range(4): # 0 1
time.sleep(0.5)
j = (i + 1) * 1000 # 1000 2000
js_ = f'document.documentElement.scrollTop={j}'
driver.execute_script(js_)
time.sleep(5)
13.回到主页面,找到下一页的xpath,点击
driver.find_element_by_xpath('//*[@id="pageContainer"]/a[9]').click()
然后,我们就进入了 下一页,然后下面就没有代码了,怎么办,怎么让代码一直运行将很多页的数据爬下来呢?有两种方法:
封装函数,并发爬取使用循环进行爬取
然后,就没有然后了…
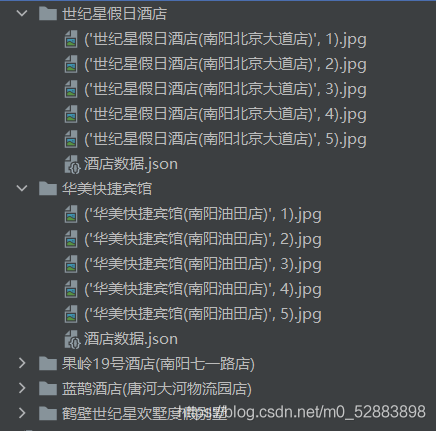
四、成功
成功拿到数据
结语
希望大家能够通过实战了解各种语法的功能,而不是死记硬背各种语法,那样你很容易忘记,其实很多学习都可以通过这种方式来学习
到此这篇关于Python爬虫实战之用selenium爬取某旅游网站的文章就介绍到这了,更多相关Python selenium爬取网站内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 今天我来给大家介绍在php中跨网站请求伪造的实现方法与最后我们些常用的防止伪造的具体操作方法,有需要了解的朋友可进入参考。 伪造跨站请求介绍 伪造跨站请求...2016-11-25
- 这篇文章主要介绍了python-opencv-画外接矩形框的实例代码,代码简单易懂,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-09-04
Python astype(np.float)函数使用方法解析
这篇文章主要介绍了Python astype(np.float)函数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-06-08- 2022虎年新年即将来临,小编为大家带来了一个利用Python编写的虎年烟花特效,堪称全网最绚烂,文中的示例代码简洁易懂,感兴趣的同学可以动手试一试...2022-02-14
- 在本篇文章里小编给大家分享的是一篇关于python中numpy.empty()函数实例讲解内容,对此有兴趣的朋友们可以学习下。...2021-02-06
python-for x in range的用法(注意要点、细节)
这篇文章主要介绍了python-for x in range的用法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-10- 这篇文章主要介绍了Python 图片转数组,二进制互转操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-09
- 这篇文章主要介绍了Python中的imread()函数用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-16
- 这篇文章主要介绍了python如何实现b站直播自动发送弹幕,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下...2021-02-20
- 获取网站icon,常用最简单的方法就是通过website/favicon.ico来获取,不过由于很多网站都是在页面里面设置favicon,所以此方法很多情况都不可用。 更好的办法是通过google提供的服务来实现:http://www.google.com/s2/favi...2014-06-07
python Matplotlib基础--如何添加文本和标注
这篇文章主要介绍了python Matplotlib基础--如何添加文本和标注,帮助大家更好的利用Matplotlib绘制图表,感兴趣的朋友可以了解下...2021-01-26- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- 今天小编就为大家分享一篇python 计算方位角实例(根据两点的坐标计算),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 在本篇文章里小编给大家整理的是一篇关于python中使用np.delete()的实例方法,对此有兴趣的朋友们可以学习参考下。...2021-02-01
- 这篇文章主要为大家详细介绍了python实现双色球随机选号,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-05-02
- 这篇文章主要介绍了使用Python的pencolor函数实现渐变色功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-09
Python getsizeof()和getsize()区分详解
这篇文章主要介绍了Python getsizeof()和getsize()区分详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-20- 这篇文章主要介绍了python自动化办公操作PPT的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-05
- 这篇文章主要介绍了解决python 两个时间戳相减出现结果错误的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-12
- 这篇文章主要为大家详细介绍了python实现学生通讯录管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-25