详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
更新时间:2021年1月25日 10:00 点击:1960
获取要爬取的URL
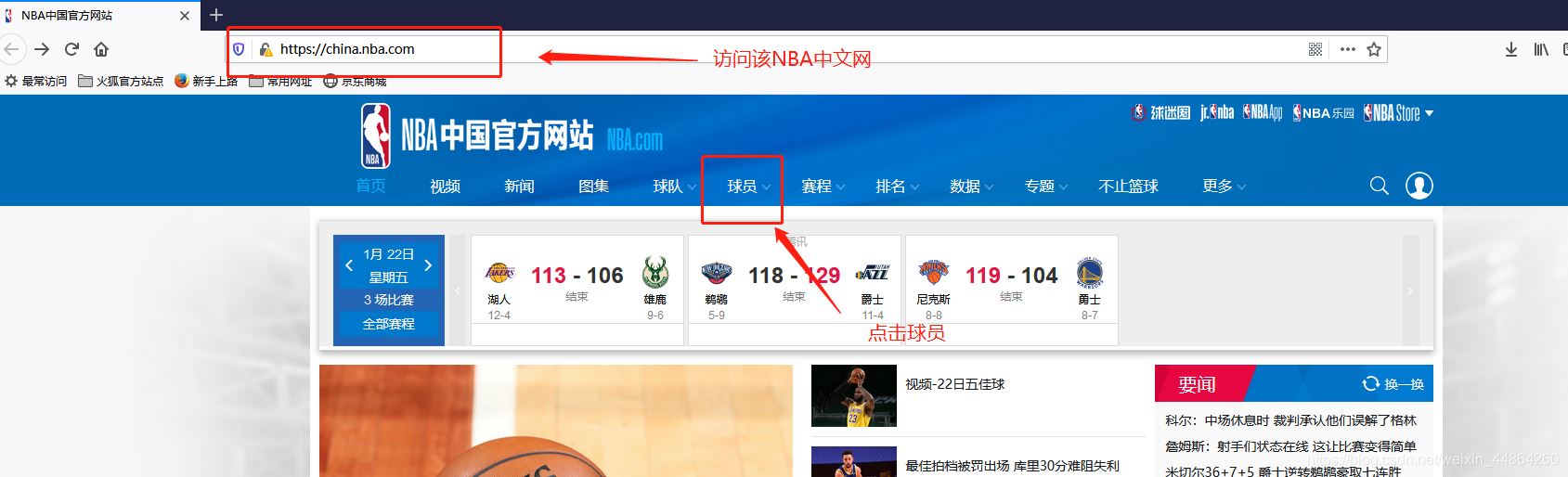
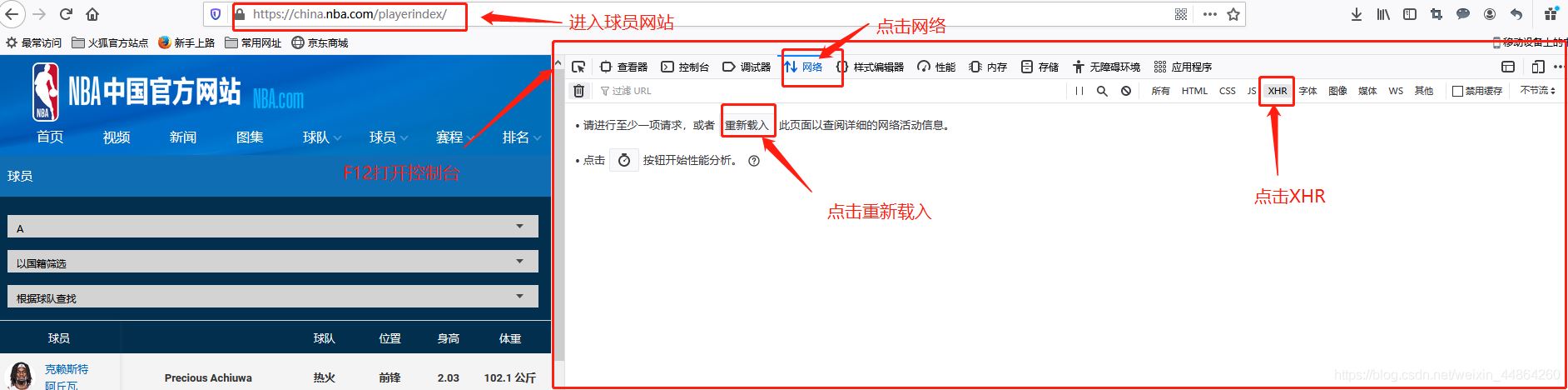
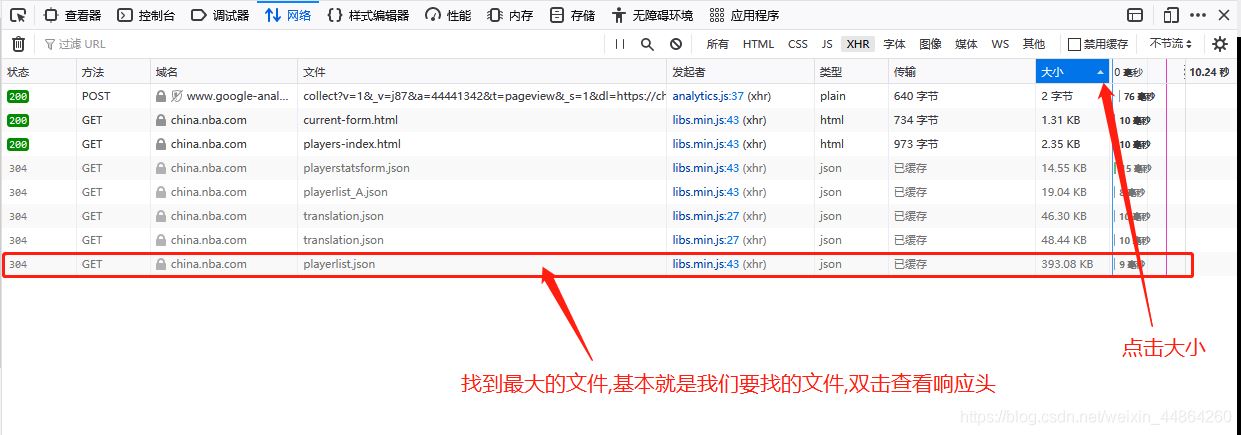
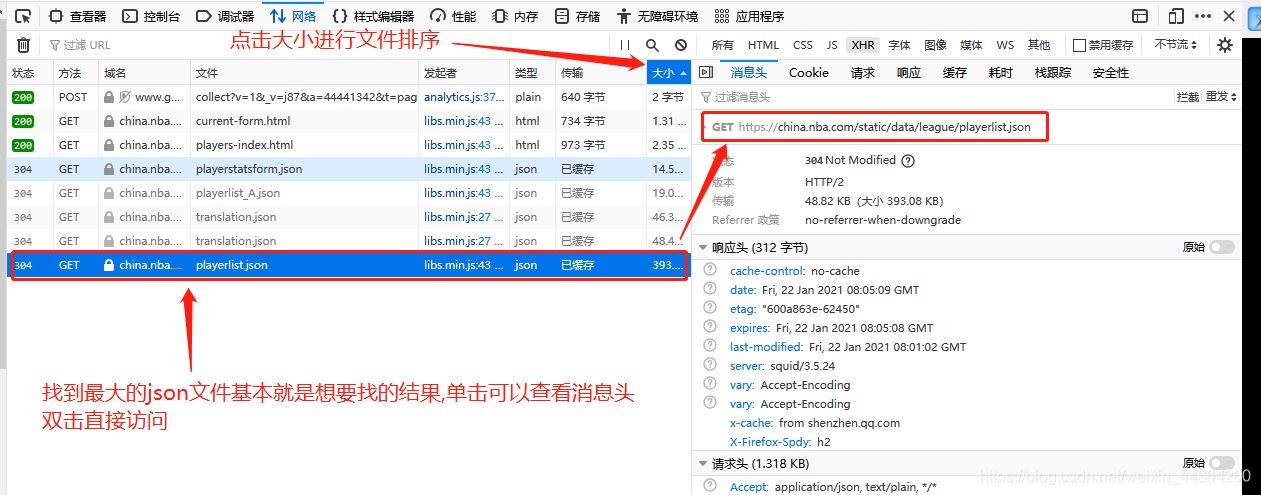
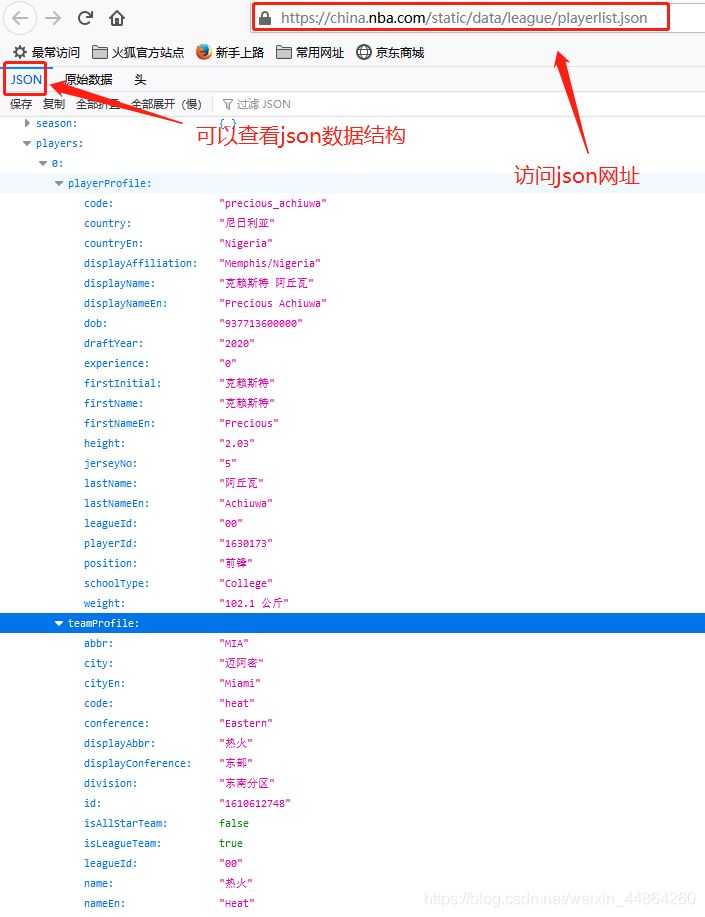
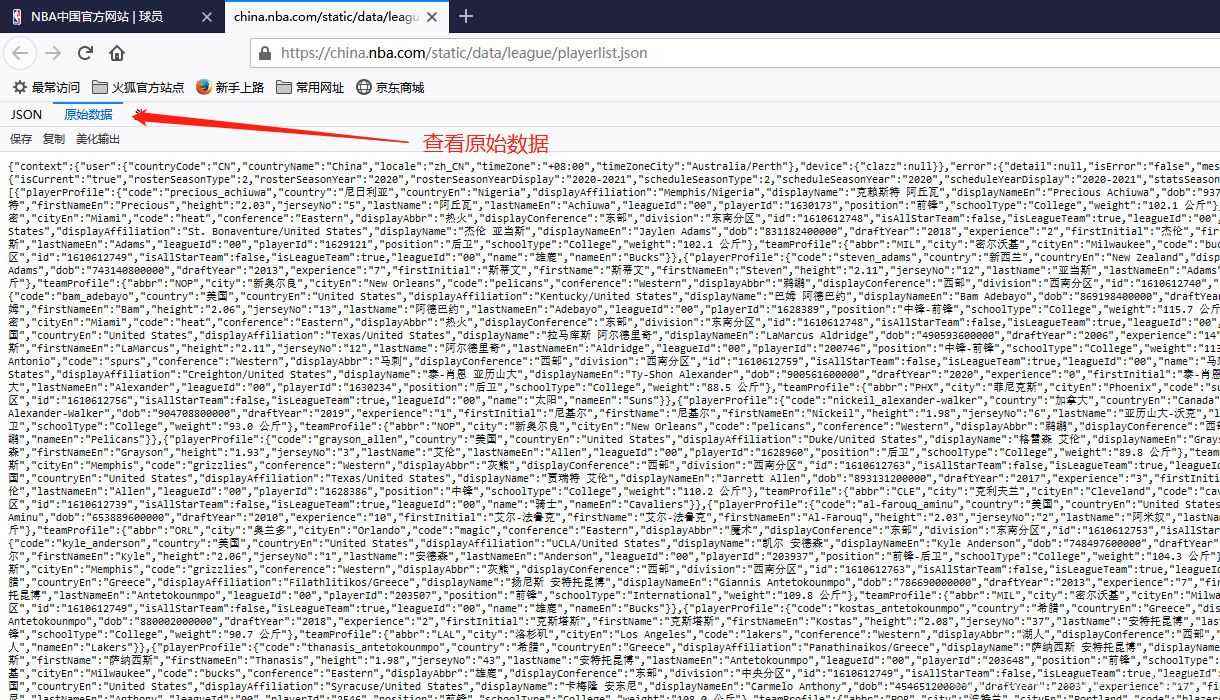
爬虫前期工作
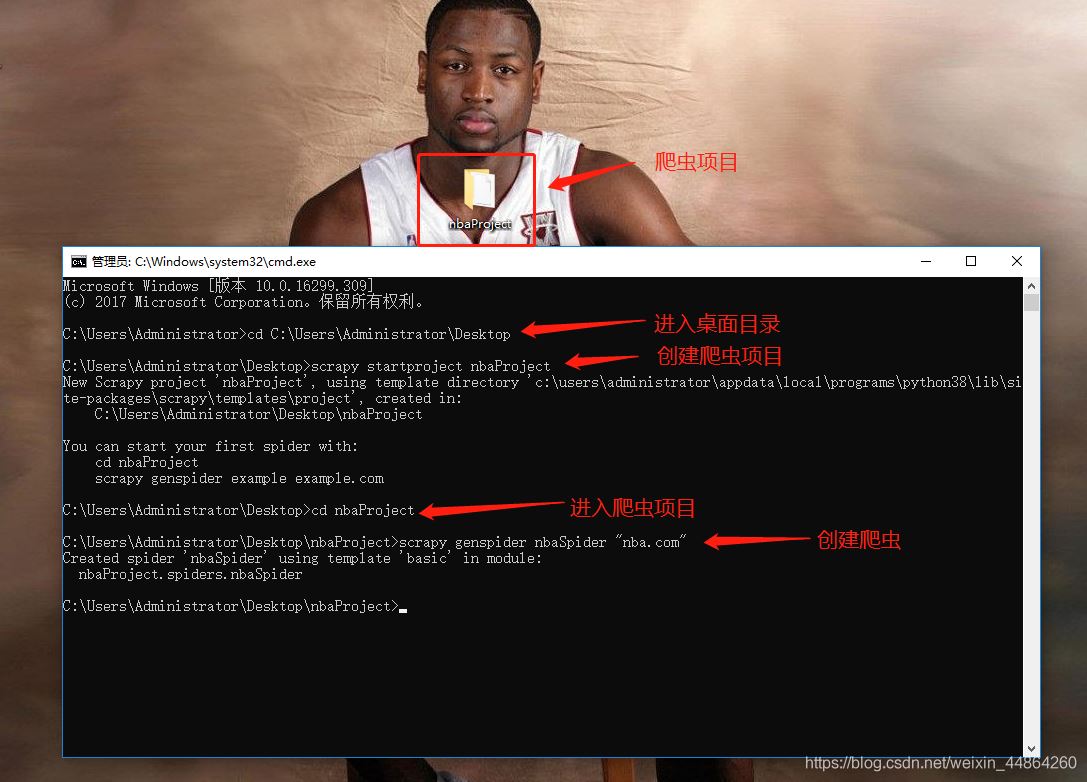
用Pycharm打开项目开始写爬虫文件
字段文件items
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class NbaprojectItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # pass # 创建字段的固定格式-->scrapy.Field() # 英文名 engName = scrapy.Field() # 中文名 chName = scrapy.Field() # 身高 height = scrapy.Field() # 体重 weight = scrapy.Field() # 国家英文名 contryEn = scrapy.Field() # 国家中文名 contryCh = scrapy.Field() # NBA球龄 experience = scrapy.Field() # 球衣号码 jerseyNo = scrapy.Field() # 入选年 draftYear = scrapy.Field() # 队伍英文名 engTeam = scrapy.Field() # 队伍中文名 chTeam = scrapy.Field() # 位置 position = scrapy.Field() # 东南部 displayConference = scrapy.Field() # 分区 division = scrapy.Field()
爬虫文件
import scrapy
import json
from nbaProject.items import NbaprojectItem
class NbaspiderSpider(scrapy.Spider):
name = 'nbaSpider'
allowed_domains = ['nba.com']
# 第一次爬取的网址,可以写多个网址
# start_urls = ['http://nba.com/']
start_urls = ['https://china.nba.com/static/data/league/playerlist.json']
# 处理网址的response
def parse(self, response):
# 因为访问的网站返回的是json格式,首先用第三方包处理json数据
data = json.loads(response.text)['payload']['players']
# 以下列表用来存放不同的字段
# 英文名
engName = []
# 中文名
chName = []
# 身高
height = []
# 体重
weight = []
# 国家英文名
contryEn = []
# 国家中文名
contryCh = []
# NBA球龄
experience = []
# 球衣号码
jerseyNo = []
# 入选年
draftYear = []
# 队伍英文名
engTeam = []
# 队伍中文名
chTeam = []
# 位置
position = []
# 东南部
displayConference = []
# 分区
division = []
# 计数
count = 1
for i in data:
# 英文名
engName.append(str(i['playerProfile']['firstNameEn'] + i['playerProfile']['lastNameEn']))
# 中文名
chName.append(str(i['playerProfile']['firstName'] + i['playerProfile']['lastName']))
# 国家英文名
contryEn.append(str(i['playerProfile']['countryEn']))
# 国家中文
contryCh.append(str(i['playerProfile']['country']))
# 身高
height.append(str(i['playerProfile']['height']))
# 体重
weight.append(str(i['playerProfile']['weight']))
# NBA球龄
experience.append(str(i['playerProfile']['experience']))
# 球衣号码
jerseyNo.append(str(i['playerProfile']['jerseyNo']))
# 入选年
draftYear.append(str(i['playerProfile']['draftYear']))
# 队伍英文名
engTeam.append(str(i['teamProfile']['code']))
# 队伍中文名
chTeam.append(str(i['teamProfile']['displayAbbr']))
# 位置
position.append(str(i['playerProfile']['position']))
# 东南部
displayConference.append(str(i['teamProfile']['displayConference']))
# 分区
division.append(str(i['teamProfile']['division']))
# 创建item字段对象,用来存储信息 这里的item就是对应上面导的NbaprojectItem
item = NbaprojectItem()
item['engName'] = str(i['playerProfile']['firstNameEn'] + i['playerProfile']['lastNameEn'])
item['chName'] = str(i['playerProfile']['firstName'] + i['playerProfile']['lastName'])
item['contryEn'] = str(i['playerProfile']['countryEn'])
item['contryCh'] = str(i['playerProfile']['country'])
item['height'] = str(i['playerProfile']['height'])
item['weight'] = str(i['playerProfile']['weight'])
item['experience'] = str(i['playerProfile']['experience'])
item['jerseyNo'] = str(i['playerProfile']['jerseyNo'])
item['draftYear'] = str(i['playerProfile']['draftYear'])
item['engTeam'] = str(i['teamProfile']['code'])
item['chTeam'] = str(i['teamProfile']['displayAbbr'])
item['position'] = str(i['playerProfile']['position'])
item['displayConference'] = str(i['teamProfile']['displayConference'])
item['division'] = str(i['teamProfile']['division'])
# 打印爬取信息
print("传输了",count,"条字段")
count += 1
# 将字段交回给引擎 -> 管道文件
yield item
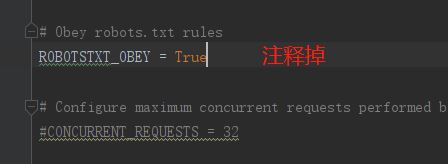
配置文件->开启管道文件
# Scrapy settings for nbaProject project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# ----------不做修改部分---------
BOT_NAME = 'nbaProject'
SPIDER_MODULES = ['nbaProject.spiders']
NEWSPIDER_MODULE = 'nbaProject.spiders'
# ----------不做修改部分---------
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'nbaProject (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ----------修改部分(可以自行查这是啥东西)---------
# ROBOTSTXT_OBEY = True
# ----------修改部分---------
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'nbaProject.middlewares.NbaprojectSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'nbaProject.middlewares.NbaprojectDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
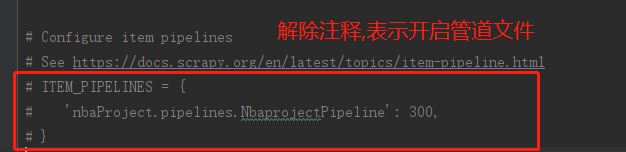
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 开启管道文件
# ----------修改部分---------
ITEM_PIPELINES = {
'nbaProject.pipelines.NbaprojectPipeline': 300,
}
# ----------修改部分---------
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
管道文件 -> 将字段写进mysql
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class NbaprojectPipeline:
# 初始化函数
def __init__(self):
# 连接数据库 注意修改数据库信息
self.connect = pymysql.connect(host='域名', user='用户名', passwd='密码',
db='数据库', port=端口号)
# 获取游标
self.cursor = self.connect.cursor()
# 创建一个表用于存放item字段的数据
createTableSql = """
create table if not exists `nbaPlayer`(
playerId INT UNSIGNED AUTO_INCREMENT,
engName varchar(80),
chName varchar(20),
height varchar(20),
weight varchar(20),
contryEn varchar(50),
contryCh varchar(20),
experience int,
jerseyNo int,
draftYear int,
engTeam varchar(50),
chTeam varchar(50),
position varchar(50),
displayConference varchar(50),
division varchar(50),
primary key(playerId)
)charset=utf8;
"""
# 执行sql语句
self.cursor.execute(createTableSql)
self.connect.commit()
print("完成了创建表的工作")
#每次yield回来的字段会在这里做处理
def process_item(self, item, spider):
# 打印item增加观赏性
print(item)
# sql语句
insert_sql = """
insert into nbaPlayer(
playerId, engName,
chName,height,
weight,contryEn,
contryCh,experience,
jerseyNo,draftYear
,engTeam,chTeam,
position,displayConference,
division
) VALUES (null,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
# 执行插入数据到数据库操作
# 参数(sql语句,用item字段里的内容替换sql语句的占位符)
self.cursor.execute(insert_sql, (item['engName'], item['chName'], item['height'], item['weight']
, item['contryEn'], item['contryCh'], item['experience'], item['jerseyNo'],
item['draftYear'], item['engTeam'], item['chTeam'], item['position'],
item['displayConference'], item['division']))
# 提交,不进行提交无法保存到数据库
self.connect.commit()
print("数据提交成功!")
启动爬虫
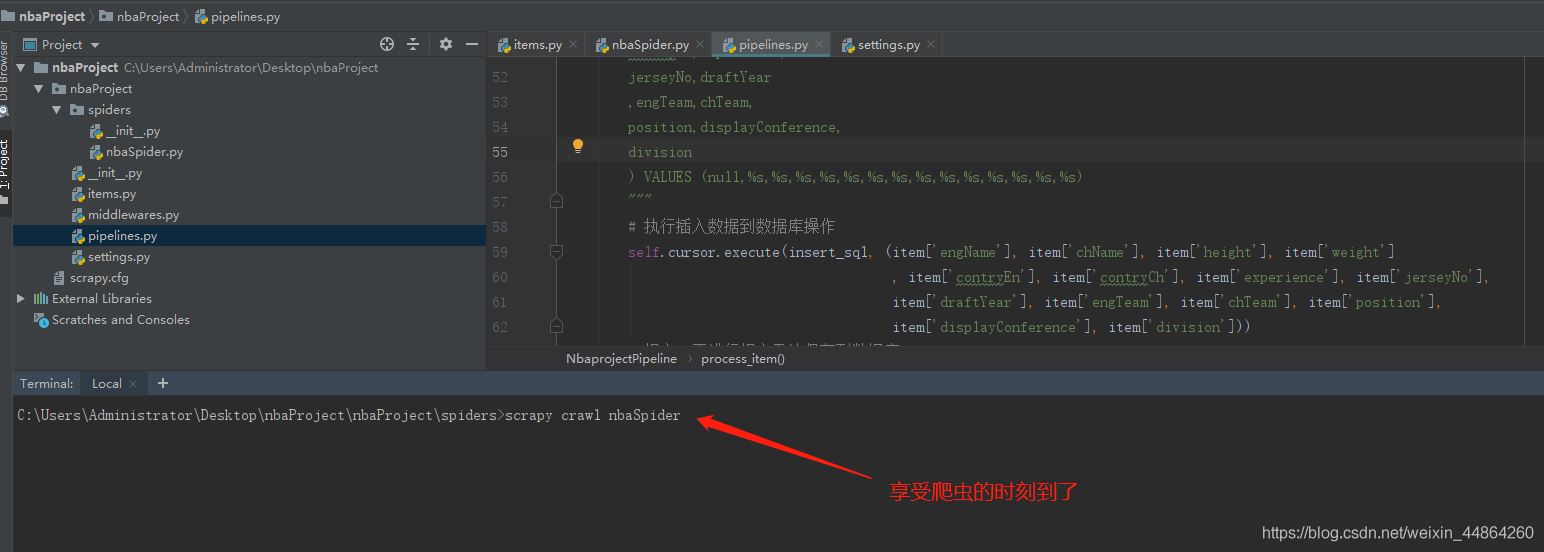
屏幕上滚动的数据
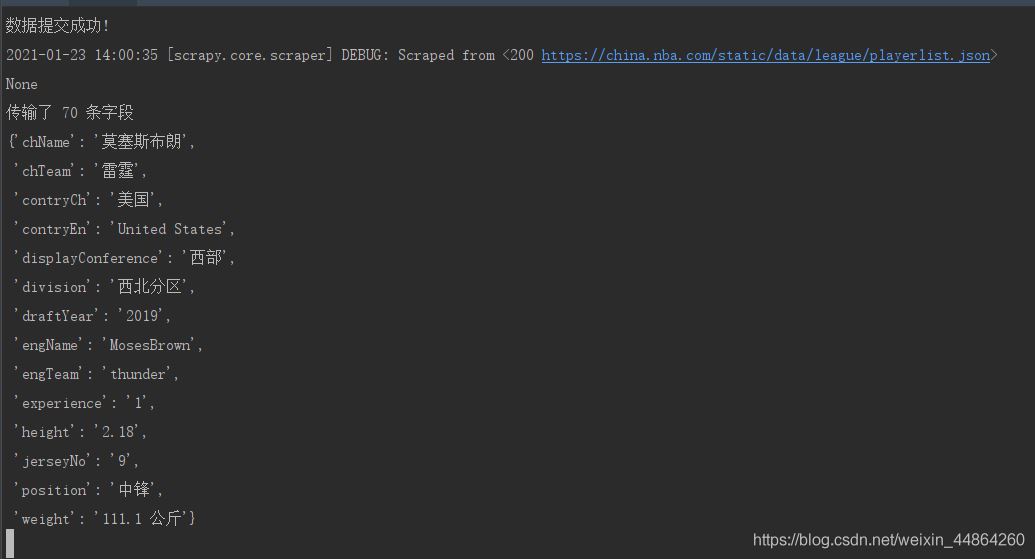
去数据库查看数据
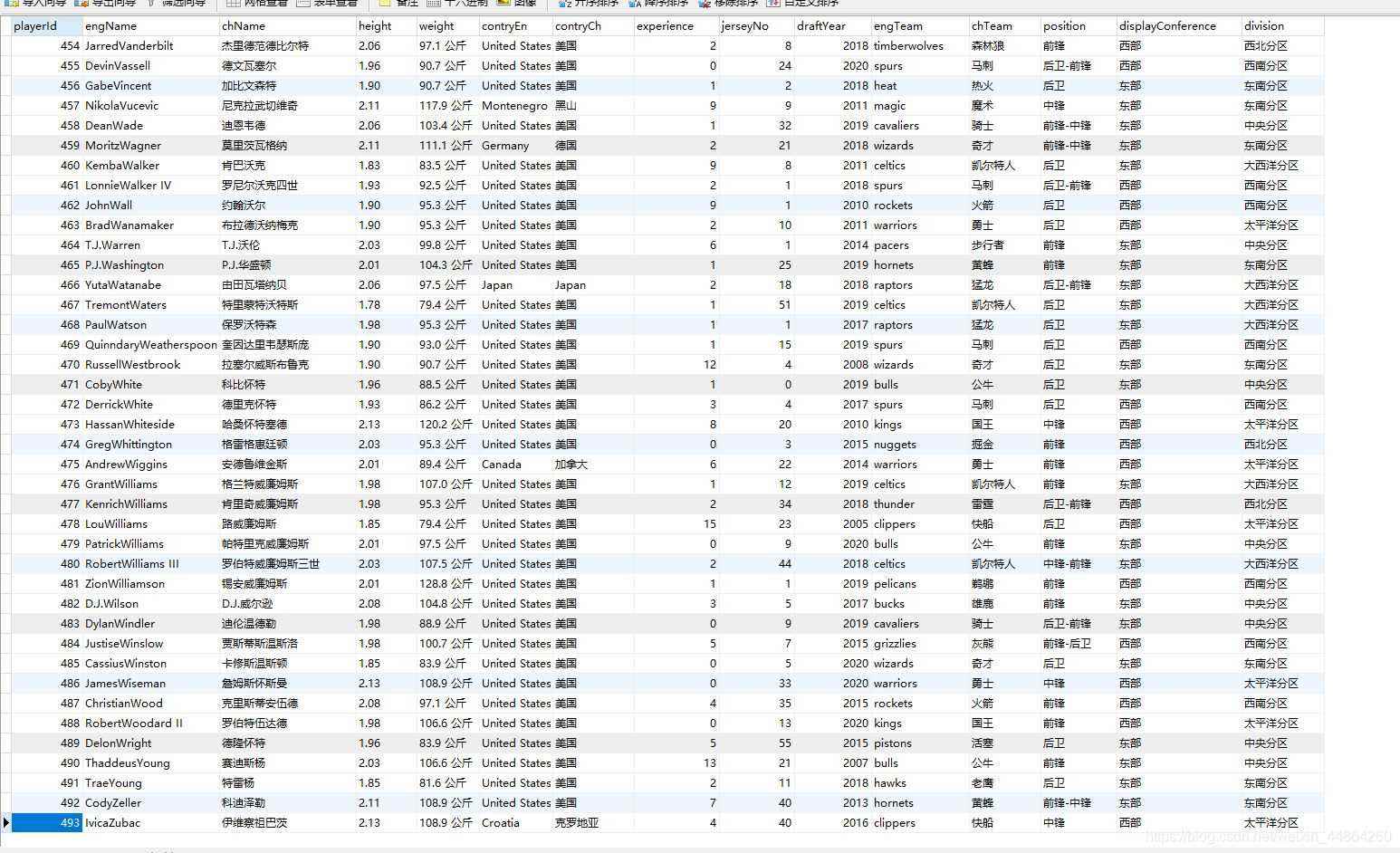
简简单单就把球员数据爬回来啦~
到此这篇关于详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库的文章就介绍到这了,更多相关Scrapy爬虫员数据存放到Mysql内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 这篇文章主要介绍了MySQL性能监控软件Nagios的安装及配置教程,这里以CentOS操作系统为环境进行演示,需要的朋友可以参考下...2015-12-14
- 新版 Mysql 中加入了对 JSON Document 的支持,可以创建 JSON 类型的字段,并有一套函数支持对JSON的查询、修改等操作,下面就实际体验一下...2016-08-23
深入研究mysql中的varchar和limit(容易被忽略的知识)
为什么标题要起这个名字呢?commen sence指的是那些大家都应该知道的事情,但往往大家又会会略这些东西,或者对这些东西一知半解,今天我总结下自己在mysql中遇到的一些commen sense类型的问题。 ...2015-03-15- 这篇文章主要介绍了MySQL 字符串拆分操作(含分隔符的字符串截取),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-22
- 一、先说一下为什么要分表:当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。根据个人经验,mysql执行一个sql的过程如下:1...2014-05-31
- 我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B。...2015-03-15
- 这几天在centos下装mysql,这里记录一下安装的过程,方便以后查阅Mysql5.5.37安装需要cmake,5.6版本开始都需要cmake来编译,5.5以后的版本应该也要装这个。安装cmake复制代码 代码如下: [root@local ~]# wget http://www.cm...2015-03-15
- 宿主机使用网线的时候,客户机在Bridged Adapter模式下,使用Atheros AR8131 PCI-E Gigabit Ethernet Controller上网没问题。 宿主机使用无线的时候,客户机在Bridged Adapter模式下,使用可选项里唯一一个WIFI选项,Microsoft Virtual Wifi Miniport Adapter也无法上网,故弃之。...2013-09-19
- 首先要声明一点,大部分情况下,修改MySQL密码是需要有mysql里的root权限的...2013-09-11
- 在本篇内容里小编给大家分享的是关于用C#做网络爬虫的步骤和方法,需要的朋友们可以参考下。...2020-06-25
- MySQL命令行导出数据库: 1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录 如我输入的命令行:cd C:/Program Files/MySQL/MySQL Server 4.1/bin (或者直接将windows的环境变量path中添加该目录) ...2013-09-26
- 今天带大家来学习selenium库的使用方法及相关知识总结,文中非常详细的介绍了selenium库,对正在学习python的小伙伴很有帮助,需要的朋友可以参考下...2021-05-25
- 一、连接Mysql格式: mysql -h主机地址 -u用户名 -p用户密码1、连接到本机上的MYSQL。首先打开DOS窗口,然后进入目录mysql/bin,再键入命令mysql -u root -p,回车后提示你输密码.注意用户名前可以有空格也可以没有空格,但是密...2015-11-08
- Navicat for MySQL注册码用来激活 Navicat for MySQL 软件,只要拥有 Navicat 注册码就能激活相应的 Navicat 产品。这篇文章主要介绍了Navicat for MySQL 11注册码\激活码汇总,需要的朋友可以参考下...2020-11-23
- 这篇文章主要介绍了mysql IS NULL使用索引案例讲解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下...2021-08-14
- 这篇文章主要介绍了selenium 反爬虫之跳过淘宝滑块验证功能,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-08-27
- 这篇文章主要介绍了node.js如何操作MySQL数据库,帮助大家更好的进行web开发,感兴趣的朋友可以了解下...2020-10-29
- 这篇文章主要介绍了基于PostgreSQL和mysql数据类型对比兼容,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-12-25
- 一、准备编译环境,安装所需依赖包yum groupinstall 'Development' -y yum install openssl openssl-devel zlib zlib-devel -y yum install readline-devel pcre-devel ncurses-devel bison-devel cmake -y二、编译安...2015-10-21
Mysql中 show table status 获取表信息的方法
这篇文章主要介绍了Mysql中 show table status 获取表信息的方法的相关资料,需要的朋友可以参考下...2016-03-12