php 中require和include引用url和 php的文件编码转换函数问题
PHP配置中“allow_url_fopen”这个选项是打开了的话,可以使用url作为include或者require的参数。
以及 allow_url 相关的参数,具体可以参考php.ini中说明
对整个页面进行转换
该方法适用所有编码环境。这样把前128个字符以外(显示字符)的字符集都用 NCR(Numeric character reference,如“汉字”将转换成“汉字”这种形式)来表示,这样的编码在任意编码环境下页面都能正常显示。
另一个问题:
该方法适用所有编码环境。这样把前128个字符以外(显示字符)的字符集都用 NCR(Numeric character reference,如“汉字”将转换成“汉字”这种形式)来表示,这样的编码在任意编码环境下页面都能正常显示。
在php文件的头部加上下面三行代码:
| 代码如下 | 复制代码 |
| mb_internal_encoding("gb2312"); // 这里的gb2312是你网站原来的编码 mb_http_output("HTML-ENTITIES"); ob_start('mb_output_handler'); |
|
使用mb_convert_encoding 函数需启用PHP 的mbstring (multi-byte string)扩展。
如果没有没有开启php的mbstring扩展,则需要做如下设置
PHP基础篇详解ASCII码对照表与字符转换,讨论ASCII码对照表图与字符转换为十进制、八进制、十六进制和HTML的方法通用的ASCII码对照表
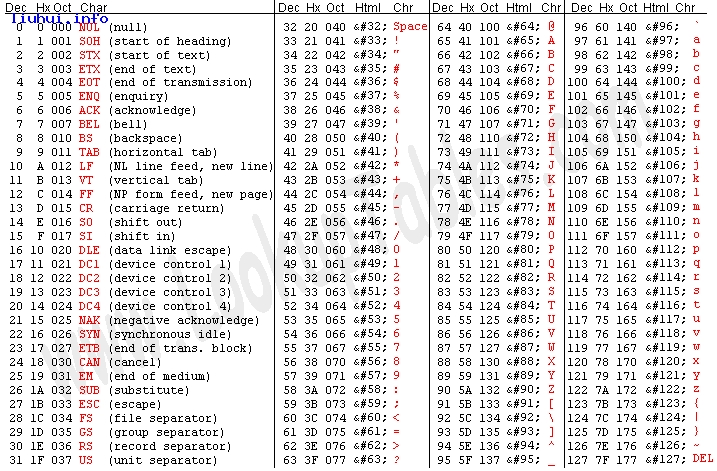
图解ASCII码对照表图,以字符A为例
Dec表示十进制,如65
Hx表示十六进制,如41
Oct表示八进制,如101
Char表示显示字符,如A
ASCII码对照表图分为两个单元
1,控制字符 0-31和127
2,可显示字符 32-126
(1)48~57为0到9十个阿拉伯数字;
(2)65~90为26个大写英文字母;
(3)97~122号为26个小写英文字母;
(4)其它标点符号、运算符号等;
二,ASCII扩展码对照表
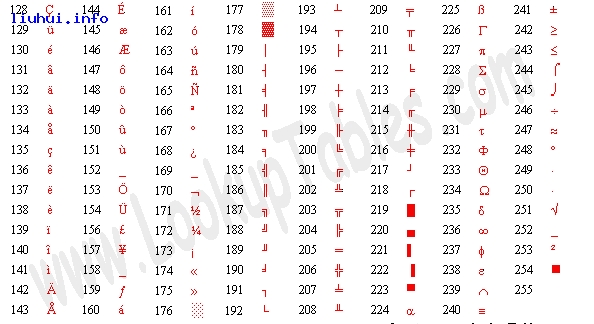
三,PHP字符转换函数说明
具体字符转换函数说明请参考[PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明]
十进制转二进制 decbin() 函数
十进制转八进制 decoct() 函数
十进制转十六进制 dechex() 函数
二进制转十六制进 bin2hex() 函数
二进制转十制进 bindec() 函数
八进制转十进制 octdec() 函数
十六进制转十进制 hexdec()函数
任意进制转换 base_convert() 函数
字符转换实例
实例一,如何把一个字符转换为二进制、八进制或十六进制,可以使用ord()函数先把字符转换为ASCII值,然后使用相应的进制转换函数进行转换,如下
a 这个字符转换为其二进制/八进制/十六进制,如下
a字符的十进制:ord('a'); //输出97
二进制:decbin(ord('a')); //输出1100001
八进制:decoct(ord('a')); //输出141
十六进制:dechex(ord('a')); //输出61
然后可以通过把各进制输出的结果对应上面ASCII码对照表图进行核对。
实例二,如何把一个二进制转换为十六进制或十进制,如a的二进制,如下
采用实例一的方法获取a字符的二进制
decbin(ord('a'));
然后把二进制转换为十六进制或十进制
十六进制:bin2hex(decbin(ord('a')));//输出31313030303031
二进制J:bindec(decbin(ord('a'))); //输出97
上面讨论的ord()函数,将在下一期中文字符编码研究系列中详细讨论。
四,参考资料
PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
asciitable对照表图
维基百科ASCII
百度百科ASCII
在 PHP 众多预定义服务器变量中,$_SERVER["REQUEST_URI"] 算是经常用到的,但是这个变量只有 apache 才支持,因此,我们需要一个更加通用的方式来获取 REQUEST_URI 的值
| 代码如下 | 复制代码 |
|
<?php |
|
PHP中文乱码有时发生在网页本身,有些产生在于MySQL交互的过程中,有时与操作系统有关。下面进行一番总结。
一.首先是PHP网页的编码
最好最快的解决办法就是,页面申明的编码与数据库内部编码一致,如果页面申请的页码与数据库内部编码不一致时,就设定连接编码 ,
| 代码如下 | 复制代码 |
| mysql_query("SET NAMES XXX "); | |
XXX为连接编码.一定可以解决乱码的问题.
1. php文件本身的编码与网页的编码应匹配 a. 如果欲使用gb2312编码,那么php要输出头:
| 代码如下 | 复制代码 |
| header(“Content-Type: text/html; charset=gb2312"), | |
静态页面添加
| 代码如下 | 复制代码 |
| <meta http-equiv="Content-Type" content="text/html; charset=gb2312">, | |
所有文件的编码格式为ANSI,可用记事本打开,另存为选择编码为ANSI,覆盖源文件。 b. 如果欲使用utf-8编码,那么php要输出头 :
| 代码如下 | 复制代码 |
| header(“Content-Type: text/html; charset=utf-8"), | |
静态页面添加
| 代码如下 | 复制代码 |
| <meta http-equiv="Content-Type" content="text/html; charset=utf-8">, | |
所有文件的编码格式为utf-8。保存为utf-8可能会有点麻烦,一般utf-8文件开头会有BOM,如果使用 session就会出问题,可用editplus来保存,在editplus中,工具->参数选择->文件->UTF-8签名,选择总 是删除,再保存就可以去掉BOM信息了。
2. php本身不是Unicode的,所有substr之类的函数得改成mb_substr(需要装mbstring扩展);或者用iconv转码。
二.PHP与Mysql的数据交互
PHP与数据库的编码应一致
1. 修改mysql配置文件my.ini或my.cnf,mysql最好用utf8编码
| 代码如下 | 复制代码 |
| [mysql] default-character-set=utf8 [mysqld] default-character-set=utf8 default-storage-engine=MyISAM | |
在[mysqld]下加入:
| 代码如下 | 复制代码 |
| default-collation=utf8_bin init_connect='SET NAMES utf8' | |
2. 在需要做数据库操作的php程序前加mysql_query("set names '编码'");,编码和php编码一致,如果php编码是gb2312那mysql编码就是gb2312,如果是utf-8那mysql编码就是 utf8,这样插入或检索数据时就不会出现乱码了
三.PHP与操作系统相关 Windows和Linux的编码是不一样的,在Windows环境下,调用PHP的函数时参数如果是utf-8编码会出现错误,比如 move_uploaded_file()、filesize()、readfile()等,这些函数在处理上传、下载时经常会用到,调用时可能会出现下 面的错误: Warning: move_uploaded_file()[function.move-uploaded-file]:failed to open stream: Invalid argument in ... Warning: move_uploaded_file()[function.move-uploaded-file]:Unable to move '' to '' in ... Warning: filesize() [function.filesize]: stat failed for ... in ... Warning: readfile() [function.readfile]: failed to open stream: Invalid argument in .. 在Linux环境下用gb2312编码虽然不会出现这些错误,但保存后的文件名出现乱码导致无法读取文件,这时可先将参数转换成操作系统识别的编码,编码 转换可用mb_convert_encoding(字符串,新编码,原编码)或iconv(原编码,新编码,字符串),这样处理后保存的文件名就不会出现 乱码,也可以正常读取文件,实现中文名称文件的上传、下载。 其实还有更好的解决方法,彻底与系统脱离,也就不用考虑系统是何编码。可以生成一个只有字母和数字的序列作为文件名,而将原来带有中文的名字保存在数据库 中,这样调用move_uploaded_file()就不会出现问题,下载的时候只需将文件名改为原来带有中文的名字。
实现下载的代码如下
| 代码如下 | 复制代码 |
|
header("Pragma: public");
|
|
四. 再来总结一下为什么会乱码 一般来说,乱码的出现有2种原因,首先是由于编码(charset) 设置错误,导致浏览器以错误的编码来解析,从而出现了满屏乱七八糟的“天书”,其次是文件被以错误的编码打开,然后保存,比如一个文本文件原先是 GB2312 编码的,却以UTF-8 编码打开再保存。要解决上述乱码问题,首先需要知道开发中哪些环节涉及到了编码:
1、文件编码:指的是页面文件(.html,.php等)本身是以何种编码来保存的。记事本和Dreamweaver 在打开页面时候会自动识别文件编码因而不太会出问题。而ZendStudio却不会自动识别编码,它只会根据首选项的配置固定以某种编码打开文件,如果工 作时候一不注意,用错误编码打开文件,做了修改之后一保存,乱码就出现了(我深有体会)。
2、页面申明编码:在 HTML代码HEAD里面,可以用
| 代码如下 | 复制代码 |
| <meta http-equiv="Content-Type" content="text/html; charset="XXX" /> | |
来告诉浏览器网页采用了什么编码,目前中文网站开发中XXX主要用的是GB2312和UTF-8 两种编码。 3、数据库连接编码:指的是进行数据库操作时候以哪种编码与数据库传输数据,这里需要注意的是不要与数据库本身的编码混淆,比如MySQL内部默认是 latin1编码,也就是说Mysql是以latin1编码来存储数据,以其他编码传输给Mysql的数据会被转换成latin1编码。 知道了WEB开发中哪些地方涉及到了编码,也就知道了乱码产生的原因:上述3项编码设置不一致,由于各种编码绝大部分是兼容ASCII的,所以英文符号不 会出现,中文就倒霉了。
五.决战一些常见的错误情况与解决:
1、数据库采用UTF8 编码,而页面申明编码是GB2312 ,这是最常见的产生乱码的原因。这时候在PHP脚本里面直接SELECT数据出来的就是乱码,需要在查询前先使用:
| 代码如下 | 复制代码 |
| mysql_query("SET NAMES GBK"); | |
来设定MYSQL连接编码,保证页面申明编码与这里设定的连接编码一致(GBK是GB2312的扩展 )。如果页面是UTF-8 编码的话,可以用:
| 代码如下 | 复制代码 |
| mysql_query("SET NAMES UTF8"); | |
注意是UTF8而不是一般用的UTF-8。假如页面申明的编码与数据库内部编码一致可以不设定连接编码。 注:事实上MYSQL的数据输入输出比上面讲的更复杂一些,MYSQL配置文件my.ini中定义了2个默认编码,分别是[client]里的 default -character-set和[mysqld] 里的default-character-set 来分别设定默认时候客户端连接和数据库内部所采用的编码。我们上面指定的编码其实是MYSQL客户端连接服务器时候的命令行参数 character_set_client,来告诉MYSQL服务器接受到的客户端数据是什么编码的,而不是采用默认编码。
2、页面申明编码与文件本身编码不一致,这种情况很少发生,因为如果编码不一致美工做页面时候在浏览器看到的就是乱码了。更多时候是发布以后修改一些小 BUG,以错误编码打开页面然后保存导致的。或者是用某些FTP软件直接在线修改文件,比如CuteFTP,由于软件编码配置错误而导致转换错了编码。 3、一些租用虚拟主机的朋友,明明上述3项编码都设置正确了还是有乱码。比方说网页是GB2312 编码的,IE等浏览器打开却总是识别成UTF-8 ,网页HEAD里面已经申明是GB2312 了,手动修改浏览器编码为GB2312 后页面显示正常。产生原因是服务器Apache设定了服务器全局的默认编码,在httpd.conf里面加了AddDefaultCharset UTF-8 。这时候服务器会首先发送HTTP头给浏览器,其优先级比页面里申明编码高,自然浏览器就识别错了。解决办法有2个,请管理员在配置文件自己的虚机里加上 一条AddDefaultCharset GB2312 来覆盖全局配置,或者在自己目录的.htaccess里配置。 总结:总之一句话,要解决要解决最PHP中文乱码好最快的解决办法就是,页面申明的编码与数据库内部编码一致,如果页面申请的页码与数据库内部编码不一致时,就设定连接编码 ,
| 代码如下 | 复制代码 |
| mysql_query("SET NAMES XXX "); | |
XXX为连接编码.一定可以解决乱码的问题.
在php中默认换代码换行有\\n还有一个就是回车换行了/r/n以及我们的ascii编辑的chr(32) chr(13)分别是回车和空格哦,下面是简单介绍不同系统之间的换行符在php中的用法。
| 代码如下 | 复制代码 |
|
//1、使用str_replace 来替换换行 //2、使用正则替换 //3、使用php定义好的变量 (建议使用) |
|
相关文章
- 这篇文章主要介绍了JavaScript实现Base64编码转换的相关资料,非常简单实用,需要的朋友可以参考下...2016-04-25
PHP编码转换函数mb_convert_encoding与iconv用法
文章来实现一个PHP编码转换函数mb_convert_encoding与iconv用法,希望例子能帮助到各位。 将一个短信接口代码从apache迁移到nginx+php-fpm后,发现无法发出短信了,查...2016-11-25- 用到iconv函数把抓取来过的utf-8编码的页面转成gb2312, 发现只有用iconv函数把抓取过来的数据一转码数据就会无缘无故的少一些 代码如下 复制代码 ...2016-11-25
VS Code C/C++环境配置教程(无法打开源文件“xxxxxx.h”或者检测到 #include 错误,请更新includePath)(POSIX API)
这篇文章主要介绍了VS Code C/C++环境配置教程(无法打开源文件“xxxxxx.h” 或者 检测到 #include 错误。请更新includePath) (POSIX API),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-08-13- 这篇文章主要为大家详细介绍了require、backbone等重构手机图片查看器的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2016-11-22
- 这篇文章主要介绍了基于mybatis中<include>标签的作用说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-20
include包含头文件的语句中,双引号和尖括号的区别(详解)
下面小编就为大家带来一篇include包含头文件的语句中,双引号和尖括号的区别(详解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2020-04-25Lua中的loadfile、dofile、require详解
这篇文章主要介绍了Lua中的loadfile、dofile、require详解,本文分别用实例讲解它的用法和特点等内容,需要的朋友可以参考下...2020-06-30- Perl中的文件包含,有三种方法:do, require, 以及use,这里简单的介绍下方便需要的朋友...2020-06-29
php include提示failed to open stream: Permission denied in错误
出现failed to open stream: Permission denied in是apache运行用户没用权限去访问指定的文件了,所以导致目录文件打不开了。 在打开浏览器时提示 Warning: includ...2016-11-25php中set_include_path和require,include介绍
在php中set_include_path会导致require,include用法不一样了,对于这个问题我们来看一个简单的例子,具体如下。 在PHP中经常使用include,require来引用其他文件,使用相...2016-11-25- php教程中文目录 include错误解决访求 include_path='.;c:php5pear'的错误 warning: unknown: failed to open stream: no such file or directory in unknown on line...2016-11-25
- 在C++中,所有的文件操作,都是以流(stream)的方式进行的,fstream也就是文件流file stream。这篇文章主要介绍了C++中#include头文件,需要的朋友可以参考下...2020-06-25
- include()和require()的区别 这相信是PHP中最基本的问题了,也是很多公司面试时必考的题呵呵。 给大家复习一下: require() :如果文件不存在,会报出一个fatal error.脚本...2016-11-25
- 本文主要对handlebars+require基本使用方法进行详细介绍,文章尾部会附上完整代码供大家参考。需要的朋友一起来看下吧...2017-01-09
- 如果你做过各种大小的Web站点,一定会对重用代码段的重要性深有体会,不管是HTML还是PHP代码块。比如需要一年修改一次包含版权信息的页脚,而你有1000个Web页(就算是10...2016-11-25
- 我们来看看用php写的一款编码转换程序代码哦,把gbk,utf-8之间互转等。 function phpUnescape_no($source) { $decodedStr = ""; $pos = 0; $len...2016-11-25
php 中require和include引用url和 php的文件编码转换函数问题
本文章同时解决两个问题就是php 中require和include引用url和 php的文件编码转换函数问题,有需要的朋友可以看看哈,参考一下。 PHP配置中“allow_url_fopen&rd...2016-11-25php中include require utf-8文件时顶部产生空行的
本文章来介绍关于php中include require utf-8文件时顶部产生空行的解决办法有需要学习的朋友可参考。 include()产生一个警告而require()则导致一个致命错误。换...2016-11-25再讲php中require(),include(),require_once()和include_once()他们的区别
本文章介绍了php四种调用外部文件函数用法和区别,有需要了解的朋友可以参考一下。 引用文件的方法有两种:require 及 include。两种方式提供不同的使用弹性。 requi...2016-11-25