图文详解Java中的序列化机制
概述
java中的序列化可能大家像我一样都停留在实现Serializable接口上,对于它里面的一些核心机制没有深入了解过。直到最近在项目中踩了一个坑,就是序列化对象添加一个字段以后,使用方系统报了反序列化失败,原因是我们双方的序列化对象没有加上serialVersionUID,那你们知道下面几个问题吗:
- 序列化对象中的
serialVersionUID是干嘛用的? - 如何修改默认的序列化机制?
- 如何使用序列化的方式克隆对象?
对象序列化和反序列化机制
序列化: 将对象转成二进制写到输出流的过程。
反序列化: 通过输入流读回二进制转成对象的过程。
通过对象的序列化和反序列化机制可以实现对象在网络之间传输。
在Java中,如果一个对象要想实现序列化,必须要实现下面两个接口之一:
- Serializable 接口
- Externalizable 接口
这里我们先讲解常用的Serializable 接口。
writeObject序列化过程栗子:
@Test
public void testSerializable() throws FileNotFoundException {
User user = new User("alvin", 19);
// 文件输出流
FileOutputStream bout = new FileOutputStream("user.dat");
try (ObjectOutputStream out = new ObjectOutputStream(bout)) {
// 序列化
out.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private String username;
private Integer age;
}
结果:
readObject反序列化栗子:
现在模拟另外一个系统需要反序列化user.dat
@Test
public void testDeSerializable() throws FileNotFoundException {
User user = null;
// 写到内存中,当然也可以写到文件中
FileInputStream fis = new FileInputStream("user.dat");
try (ObjectInputStream in = new ObjectInputStream(fis)) {
// 反序列化 readObject
user = (User) in.readObject();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
Assert.assertEquals("alvin", user.getUsername());
}
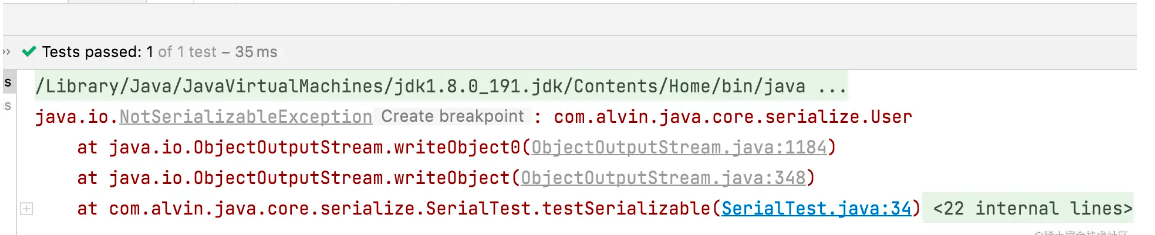
如果User类不实现Serializable接口, 那会怎么样?
当然是报错了,如下图:
小结:
一个对象想要被序列化,那么它的类就要实现此接口或者它的子接口。
修改默认的序列化机制
默认的情况下,如果实现了Serializable接口的对象进行序列化的时候,默认会将全部的数据域,也就是成员变量进行序列化输出,那往往有时候并不需要这样,有什么方法可以修改序列化机制呢?下面提供3中方式。
使用transient关键字
将成员变量标记成transient,那么在序列化的过程中这些数据域会被跳过,如下图所示:

这是一种最简单的方式,但是不够灵活。
自定义readObject、writeObject方法
序列化类中可以通过定义下面签名的方法:
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundExceptionprivate void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException
只要类中有这两个签名的方法,那么就不会调用默认的序列化,取而代之调用这些方法。
本例我们举个jdk中的例子,ArrayList就实现了这两个方法,重写了序列化机制。
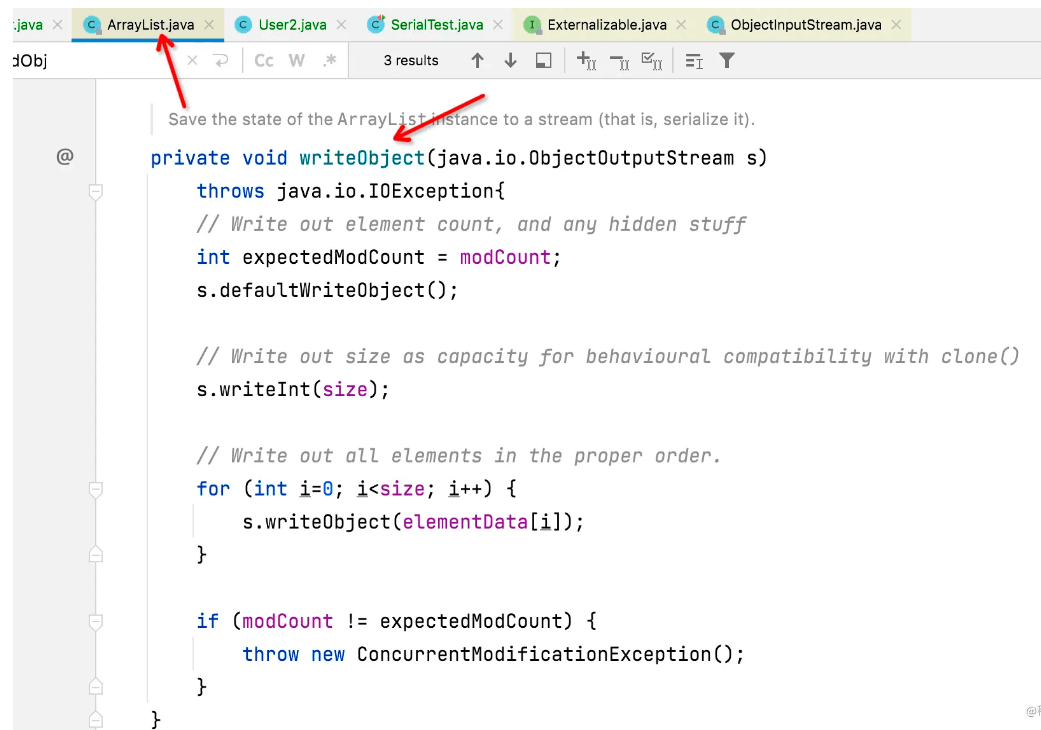
主要原因ArrayList底层的数组通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用自定义方式实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
实现Externalizable接口
Externalizable接口想必大家很少用到,它是Serializable接口的子类,用户要实现的writeExternal()和readExternal() 方法,用来决定如何序列化和反序列化。
因为序列化和反序列化方法需要自己实现,因此可以指定序列化哪些属性,而transient在这里无效。
对Externalizable对象反序列化时,会先调用类的无参构造方法,这是有别于默认反序列方式的。如果把类的不带参数的构造方法删除,或者把该构造方法的访问权限设置为private、默认或protected级别,会抛出java.io.InvalidException: no valid constructor异常,因此Externalizable对象必须有默认构造函数,而且必需是public的。
举例说明:
public class User2 implements Externalizable {
private String username;
private Integer age;
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeUTF(username);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
username = in.readUTF();
age = in.readInt();
}
}
serialVersionUID的作用
这就回到概述中提到的项目中遇到的问题,现在简要描述下:
A系统中的序列化对象User用的最新版本如下:

B系统中反序列化的对象,还是老的User版本如下:

这时候A系统生成的序列化文件,交给B系统反序列化时,出错了, 如下图:

原因:
类定义发生了变化,比如添加、删除、修改类中的数据域后,它的唯一标记符或者称为SHA指纹、或者理解为serialVersionUID都会发生变化,这个值会保存在序列化二进制中,如果反序列化过程发现对不上,就会报错,如上图所示。
那么如何处理呢?
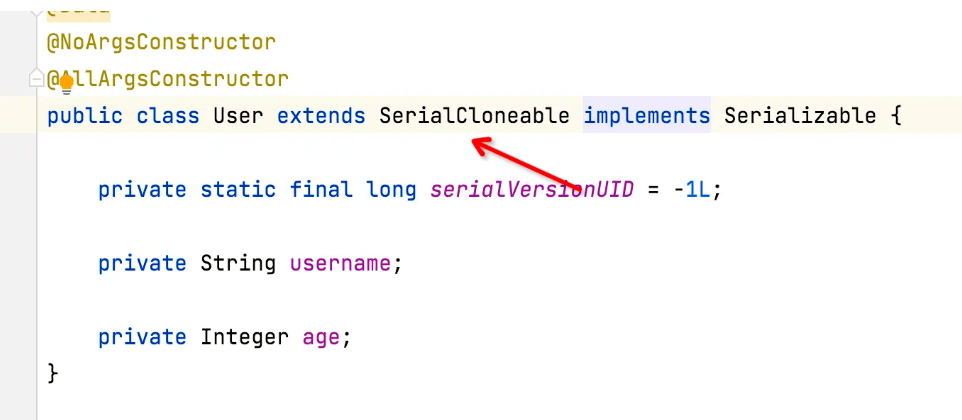
这时候,我们如果觉得这个序列化对象是可以兼容的,那么可以自定义一个serialVersionUID的静态成员变量,它就不会自动生成,而是直接用这个值,如下图:

使用序列化clone
clone大家都知道吧,在深拷贝的时候编码还是很麻烦的,借用序列化机制可以实现深拷贝。做法很简单,就是将对象序列化到输出流中,然后读回。
public class SerialCloneable implements Cloneable, Serializable {
@Override
public Object clone() throws CloneNotSupportedException {
try {
// 保存到字节数组流
ByteArrayOutputStream bout = new ByteArrayOutputStream();
try(ObjectOutputStream out = new ObjectOutputStream(bout)) {
out.writeObject(this);
}
// 读取
try(InputStream bin = new ByteArrayInputStream(bout.toByteArray())) {
ObjectInputStream in = new ObjectInputStream(bin);
return in.readObject();
}
} catch (IOException | ClassNotFoundException e) {
CloneNotSupportedException e2 = new CloneNotSupportedException();
e2.initCause(e);
throw e2;
}
}
}
注意一点,这种方式性能不高,通常比显示构建、复制数据要慢不少。
到此这篇关于图文详解Java中的序列化机制的文章就介绍到这了,更多相关Java序列化机制内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
原文出处:https://juejin.cn/post/7149696534035038222
相关文章
- 这篇文章主要介绍了如何利用java语言实现经典《复杂迷宫》游戏,文中采用了swing技术进行了界面化处理,感兴趣的小伙伴可以动手试一试...2022-02-01
java 运行报错has been compiled by a more recent version of the Java Runtime
java 运行报错has been compiled by a more recent version of the Java Runtime (class file version 54.0)...2021-04-01- 这篇文章主要介绍了在java中获取List集合中最大的日期时间操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-15
- 这篇文章主要介绍了教你怎么用Java获取国家法定节假日,文中有非常详细的代码示例,对正在学习java的小伙伴们有非常好的帮助,需要的朋友可以参考下...2021-04-23
- 这篇文章主要介绍了Java如何发起http请求的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-31
- 说起C#和Java这两门语言(语法,数据类型 等),个人以为,大概有90%以上的相似,甚至可以认为几乎一样。但是在工作中,我也发现了一些细微的差别...2020-06-25
- 这篇文章主要介绍了解决Java处理HTTP请求超时的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-29
- 这篇文章主要介绍了java 判断两个时间段是否重叠的案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-15
- 这篇文章主要介绍了超简洁java实现双色球若干注随机号码生成(实例代码),本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-04-02
- 这篇文章主要介绍了Java生成随机姓名、性别和年龄的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-10-01
java 画pdf用itext调整表格宽度、自定义各个列宽的方法
这篇文章主要介绍了java 画pdf用itext调整表格宽度、自定义各个列宽的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-31Jackson反序列化@JsonFormat 不生效的解决方案
这篇文章主要介绍了Jackson反序列化@JsonFormat 不生效的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-08-10- 这篇文章主要介绍了java正则表达式判断前端参数修改表中另一个字段的值,需要的朋友可以参考下...2021-05-07
Java使用ScriptEngine动态执行代码(附Java几种动态执行代码比较)
这篇文章主要介绍了Java使用ScriptEngine动态执行代码,并且分享Java几种动态执行代码比较,需要的朋友可以参考下...2021-04-15- 这篇文章主要介绍了Java开发实现人机猜拳游戏,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-08-03
- 这篇文章主要介绍了Java List集合返回值去掉中括号('[ ]')的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-29
Java中lombok的@Builder注解的解析与简单使用详解
这篇文章主要介绍了Java中lombok的@Builder注解的解析与简单使用,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-01-06- 下面小编就为大家带来一篇java中String类型变量的赋值问题介绍。小编觉得挺不错的。现在分享给大家,给大家一个参考。...2016-03-28
Java 8 Stream 的终极技巧——Collectors 功能与操作方法详解
这篇文章主要介绍了Java 8 Stream Collectors 功能与操作方法,结合实例形式详细分析了Java 8 Stream Collectors 功能、操作方法及相关注意事项,需要的朋友可以参考下...2020-05-20- 这篇文章主要介绍了Java线程池中的各个参数如何合理设置操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-06-19