Python爬虫获取数据保存到数据库中的超详细教程(一看就会)
更新时间:2022年6月11日 19:39 点击:231 作者:hippoDocker
1.简介介绍
-网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
-一般在浏览器上可以获取到的,通过爬虫也可以获取到,常见的爬虫语言有PHP,JAVA,C#,C++,Python,为啥我们经常听到说的都是Python爬虫,这是因为python爬虫比较简单,功能比较齐全。
2.Xpath获取页面信息
通过Xpath进行爬虫就是获取到页面html后通过路径的表达式来选取标签节点,沿着路径选取需要爬取的数据。
Xpath常用表达式:
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取(取子节点) |
| // | 选择的当前节点选择文档中的节点 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性 |
| * | 表示任意内容(通配符) |
| | | 运算符可以选取多个路径 |
Xpath常用函数:
| 函数 | 用法 | 解释 |
|---|---|---|
| startswith() | xpath(‘//div[starts-with(@id,”celent”)]‘) | #选取id值以celent开头的div节点 |
| contains() | xpath(‘//div[contains(@id,”celent”)]‘) | #选取id值包含celent的div节点 |
| and() | xpath(‘//div[contains(@id,”celent”) and contains(@id,”in”)]‘) | #选取id值包含celent的div节点 |
| text() | _.xpath(’./div/div[4]/a/em/text()’) | #选取em标签下文本内容 |
Xpath实操解析:
# 案例1
# //为从当前html中选取节点;[@class="c1text1"]为获取所有的class为c1text1的节点;/h1[1]为选取的节点下的第一个h1节点,如果没有[1]则是获取所有的,可以通过循环进行获取数据
etreeHtml.xpath('//*[@class="c1text1"]/h1[1]/text()')
# 案例2
#//为从当前html中选取节点;[@class="c1text1"]为获取所有的class为c1text1的节点;/a为获取当前节点下的所有a标签节点,得到一个ObjectList;通过for循环获取里面每个标签数据,./@src为获取当前节点的src属性值
etreeHtml2 = etreeHtml.xpath('//*[@class="c1text1"]/a')
for _ in etreeHtml2:
etreeHtml.xpath(./@src)
3.通过Xpath爬虫实操
本次实例以爬取我的CSDN文章列表信息保存到数据库为案列
3-1.获取xpath
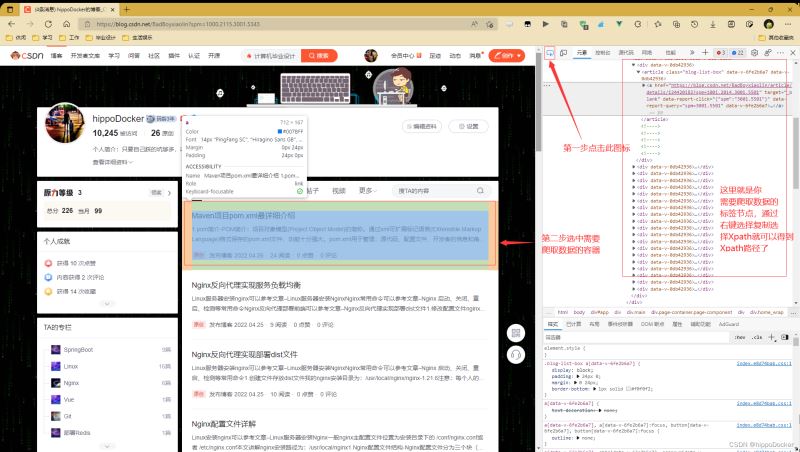
通过F12打开开发者模式,点击左上角图标可参考下图,选择需要爬取数据的容器,在右边选择复制选择xpath就可以得到xpath路径了(//*[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div);
完整代码展示:
# 导入需要的库
import requests
from lxml import etree
import pymysql
# 文章详情信息类
class articleData():
def __init__(self, title, abstract, path,date):
self.title = title #文章名称
self.abstract = abstract #文章摘要
self.path = path #文章路径
self.date = date #发布时间
def to_string(self):
print("文章名称:"+self.title
+";文章摘要:"+self.abstract
+";文章路径:"+self.path
+";发布时间:"+self.date)
#保存狗狗详情数据
#保存数据
def saveData(DataObject):
count = pymysql.connect(
host='xx.xx.xx.xx', # 数据库地址
port=3306, # 数据库端口
user='xxxxx', # 数据库账号
password='xxxxxx', # 数据库密码
db='xxxxxxx' # 数据库名
)
# 创建数据库对象
db = count.cursor()
# 写入sql
# print("写入数据:"+DataObject.to_string())
sql = f"insert into article_detail(title,abstract,alias,path,date) " \
f"values ('{DataObject.title}','{DataObject.abstract}','{DataObject.path}','{DataObject.date}')"
# 执行sql
print(sql)
db.execute(sql)
# 保存修改内容
count.commit()
db.close()
# 爬取数据的方向
def getWebData():
# 网站页面路径
url = "https://blog.csdn.net/BadBoyxiaolin?spm=1000.2115.3001.5343"
# 请求头,模拟浏览器请求
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
# 获取页面所有节点代码
html = requests.get(url=url, headers=header)
# 打印页面代码查看
# print(html.text)
# 如果乱码可以设置编码格式
# html.encoding = 'gb2312'
# 通过xpath获取数据对应节点
etreeHtml = etree.HTML(html.text)
dataHtml = etreeHtml.xpath('//*[@class="mainContent"]/div/div/div')
# 循环获取数据
for _ in dataHtml:
# ''.join()是将内容转换为字符串可以后面接replace数据进行处理
title = ''.join(_.xpath('./article/a/div[1]/h4/text()'))#文章标题
abstract = ''.join(_.xpath('./article/a/div[2]/text()'))#文章摘要
path = ''.join(_.xpath('./article/a/@href'))#文章路径
date = ''.join(_.xpath('./article/a/div[3]/div/div[2]/text()')).replace(' ','').replace('·','').replace('发布博客','')#发布时间
#初始化文章类数据
article_data = articleData(title,abstract,path,date)
article_data.to_string() #打印数据看看是否对
#保存数据到数据库
# saveData(article_data)
if __name__ == "__main__":
getWebData()
总结
到此这篇关于Python爬虫获取数据保存到数据库中的文章就介绍到这了,更多相关Python爬虫数据保存到数据库内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
原文出处:https://blog.csdn.net/BadBoyxiaolin/article/details/12448776
上一篇: python中文分词+词频统计的实现步骤
下一篇: 基于Python实现微信自动回复功能
相关文章
- 这篇文章主要介绍了python-opencv-画外接矩形框的实例代码,代码简单易懂,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-09-04
- 操作类就是把一些常用的一系列的数据库或相关操作写在一个类中,这样调用时我们只要调用类文件,如果要执行相关操作就直接调用类文件中的方法函数就可以实现了,下面整理了...2016-11-25
Python astype(np.float)函数使用方法解析
这篇文章主要介绍了Python astype(np.float)函数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-06-08- 本文给大家分享C#连接SQL数据库和查询数据功能的操作技巧,本文通过图文并茂的形式给大家介绍的非常详细,需要的朋友参考下吧...2021-05-17
- 2022虎年新年即将来临,小编为大家带来了一个利用Python编写的虎年烟花特效,堪称全网最绚烂,文中的示例代码简洁易懂,感兴趣的同学可以动手试一试...2022-02-14
- 在本篇文章里小编给大家分享的是一篇关于python中numpy.empty()函数实例讲解内容,对此有兴趣的朋友们可以学习下。...2021-02-06
- 这篇文章主要介绍了C#从数据库读取图片并保存的方法,帮助大家更好的理解和使用c#,感兴趣的朋友可以了解下...2021-01-16
python-for x in range的用法(注意要点、细节)
这篇文章主要介绍了python-for x in range的用法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-10- 这篇文章主要介绍了Python 图片转数组,二进制互转操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-09
- 这篇文章主要介绍了Python中的imread()函数用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-16
- 这篇文章主要介绍了python如何实现b站直播自动发送弹幕,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下...2021-02-20
- 这篇文章主要介绍了Intellij IDEA连接Navicat数据库的方法,本文通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借价值,需要的朋友可以参考下...2021-03-25
- 在开发过程中,我们经常会将日期时间的毫秒数存放到数据库,但是它对应的时间看起来就十分不方便,我们可以使用一些函数将毫秒转换成date格式。 一、 在MySQL中,有内置的函数from_unixtime()来做相应的转换,使用如下: 复制...2014-05-31
python Matplotlib基础--如何添加文本和标注
这篇文章主要介绍了python Matplotlib基础--如何添加文本和标注,帮助大家更好的利用Matplotlib绘制图表,感兴趣的朋友可以了解下...2021-01-26- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- C#使用System.IO中的文件操作方法在Windows系统中处理本地文件相当顺手,这里我们还总结了在Oracle中保存文件的方法,嗯,接下来就来看看整理的C#操作本地文件及保存文件到数据库的基本方法总结...2020-06-25
- 通过内网连另外一台机器的mysql服务, 确发现速度N慢! 等了大约几十秒才等到提示输入密码。 但是ping mysql所在服务器却很快! 想到很久之前有过类似的经验, telnet等一些服务在连接请求的时候,会做一些反向域名解析(如果...2015-10-21
- 今天小编就为大家分享一篇python 计算方位角实例(根据两点的坐标计算),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 某些时候,例如为了搭建一个测试环境,或者克隆一个网站,需要复制一个已存在的mysql数据库。使用以下方法,可以非常简单地实现。假设已经存在的数据库名字叫db1,想要复制一份,命名为newdb。步骤如下:1. 首先创建新的数据库newd...2015-10-21
- mysqldump命令的用法1、导出所有库系统命令行mysqldump -uusername -ppassword --all-databases > all.sql 2、导入所有库mysql命令行mysql>source all.sql; 3、导出某些库系统命令行mysqldump -uusername -ppassword...2015-10-21