版本控制CVS转到分布式Git并和Github上Fork的项目合并
在捣鼓我的 Gregarius 时,发现无法读取 HTTPS 的 RSS , 追查发现是他所使用的 HTTP 客户端类 Snoopy 的原因。 想升级新版 Snoopy 却发现原作者已经几年都不更新了, Github 上倒是有人弄了几个镜像, 其中 hurrycaner 的这个 还对 README 进行了一些改进。 但所有镜像都没有 SourceForge 上的修改历史。
所以,我想作的是,基于 hurrycaner 的镜像进行 Fork, 但是要把 SourceForge 上的修改历史也弄进来。
CVS –> Git
现在应该没有人用 CVS 了把,SourceForge 也支持 Git 了, 但上面有些古老项目依然只有 CVS 。
把 CVS 转换成 Git 的工具还是有一些的,但从 一些讨论看来 似乎都做不到完美。 也难怪,CVS 的存储格式实在是有些奇怪, 代码、修改记录、修改注释都堆在一个文件中,解析起来肯定头疼。
由于害怕 cvs2git 会像 svn2git 那样转换时把作者缀上 UUID, 我先试了试 parsecvs , 但这货连使用说明都没有,放弃了。 然后用的是 StackOverflow 上最后一个人推荐的 crap 。 和上面的一样,都是简单 make 一下就有可执行文件用, 但比上面的帮助全,还有一个非常简单的例子。
这就可以开始了,先把 SourceForge 上的仓库下载下来:
$ mkdir Snoopy.cvs
$ rsync -av rsync://snoopy.cvs.sourceforge.net/cvsroot/snoopy/ Snoopy.cvs
receiving incremental file list
./
CVSROOT/
CVSROOT/.#checkoutlist
CVSROOT/.#commitinfo
CVSROOT/.#config
CVSROOT/.#cvswrappers
CVSROOT/.#editinfo
CVSROOT/.#loginfo
CVSROOT/.#modules
CVSROOT/.#notify
CVSROOT/.#rcsinfo
CVSROOT/.#taginfo
CVSROOT/.#verifymsg
CVSROOT/checkoutlist
CVSROOT/checkoutlist,v
CVSROOT/commitinfo
CVSROOT/commitinfo,v
CVSROOT/config
CVSROOT/config,v
CVSROOT/cvswrappers
CVSROOT/cvswrappers,v
CVSROOT/editinfo
CVSROOT/editinfo,v
CVSROOT/history
CVSROOT/loginfo
CVSROOT/loginfo,v
CVSROOT/modules
CVSROOT/modules,v
CVSROOT/notify
CVSROOT/notify,v
CVSROOT/passwd
CVSROOT/rcsinfo
CVSROOT/rcsinfo,v
CVSROOT/readers
CVSROOT/taginfo
CVSROOT/taginfo,v
CVSROOT/val-tags
CVSROOT/verifymsg
CVSROOT/verifymsg,v
CVSROOT/writers
CVSROOT/Emptydir/
Snoopy/
Snoopy/AUTHORS,v
Snoopy/COPYING.lib,v
Snoopy/ChangeLog,v
Snoopy/FAQ,v
Snoopy/INSTALL,v
Snoopy/Makefile.am,v
Snoopy/NEWS,v
Snoopy/README,v
Snoopy/Snoopy.class.php,v
Snoopy/TODO,v
Snoopy/autogen.sh,v
Snoopy/configure.in,v
Snoopy/Attic/
Snoopy/Attic/.cvsignore,v
Snoopy/Attic/COPYING,v
Snoopy/Attic/Snoopy.class.inc,v
sent 1,066 bytes received 229,013 bytes 17,042.89 bytes/sec
total size is 225,573 speedup is 0.98
注意这和下载 CVS 代码是不一样的,这里下载的是 CVSROOT,仓库的原始码。
然后初始化一个 Git 仓库目录,用 crap 开始转换:
$ mkdir Snoopy.git
$ cd Snoopy.git
$ git init
$ ../crap/crap-clone /home/fwolf/dev/Snoopy.cvs Snoopy
Valid-requests Root Valid-responses valid-requests Repository Directory Max-dotdot Static-directory Sticky Entry Kopt Checkin-time Modified Is-modified Empty-conflicts UseUnchanged Unchanged Notify Questionable Argument Argumentx Global_option Gzip-stream wrapper-sendme-rcsOptions Set Gssapi-authenticate expand-modules ci co update diff log rlog add remove update-patches gzip-file-contents status rdiff tag rtag import admin export history release watch-on watch-off watch-add watch-remove watchers editors init annotate rannotate noop version
*********** CYCLE **********
Changeset andrei
*** empty log message ***
INSTALL:1.1
Makefile.am:1.1
NEWS:1.1
autogen.sh:1.1
configure.in:1.1
.cvsignore:1.1
Deferring:
autogen.sh:1.2
Tag 'Snoopy' placing on branch ''
Tag 'start' placing on branch 'Snoopy'
opening version cache failed: No such file or directory
1970-01-01 08:00:00 CST BRANCH
2000-02-03 23:40:59 CST COMMIT
2000-02-03 23:40:59 CST BRANCH Snoopy
2000-02-03 23:40:59 CST COMMIT
2000-02-03 23:40:59 CST COMMIT
2000-02-03 23:40:59 CST TAG start
2000-02-04 00:10:54 CST COMMIT
2000-02-04 00:10:54 CST COMMIT
2000-02-04 00:28:59 CST COMMIT
2000-02-22 23:44:57 CST COMMIT
2000-03-10 04:52:59 CST COMMIT
2000-03-10 04:54:47 CST COMMIT
2000-05-18 22:50:14 CST COMMIT
2000-05-18 23:36:34 CST COMMIT
2000-05-18 23:44:00 CST COMMIT
2000-06-30 02:37:25 CST COMMIT
2000-08-23 04:36:52 CST COMMIT
2000-09-14 04:52:04 CST COMMIT
2000-09-14 22:09:58 CST COMMIT
2000-09-15 21:11:11 CST COMMIT
2000-09-16 05:57:37 CST COMMIT
2000-09-27 03:34:38 CST COMMIT
2000-09-27 04:28:45 CST COMMIT
2000-10-09 21:13:52 CST COMMIT
2001-03-25 04:15:18 CST COMMIT
2001-07-07 05:24:11 CST COMMIT
2001-08-22 23:43:24 CST COMMIT
2001-11-21 04:23:02 CST COMMIT
2002-10-03 22:38:49 CST COMMIT
2002-10-03 22:55:06 CST COMMIT
2002-10-03 22:57:39 CST COMMIT
2002-10-10 04:25:50 CST COMMITMissed first time round: ChangeLog 1.11
Missed first time round: Snoopy.class.inc 1.21
2002-10-10 04:41:24 CST COMMITcvs checkout ChangeLog 1.14 - version is duplicate
cvs checkout Snoopy.class.inc 1.24 - version is duplicate
Missed first time round: ChangeLog 1.12
Missed first time round: Snoopy.class.inc 1.22
2002-10-10 04:51:57 CST COMMITcvs checkout ChangeLog 1.14 - version is duplicate
cvs checkout Snoopy.class.inc 1.24 - version is duplicate
Missed first time round: ChangeLog 1.13
Missed first time round: Snoopy.class.inc 1.23
2002-10-10 04:56:14 CST COMMIT
2003-03-12 22:40:55 CST COMMIT
2003-09-15 21:58:28 CST COMMIT
2003-10-22 03:18:39 CST COMMIT
2003-11-08 03:52:58 CST COMMIT
2003-12-24 03:34:35 CST COMMIT
2004-01-08 03:16:10 CST COMMIT
2004-07-25 02:23:27 CST COMMITMissed first time round: ChangeLog 1.19
Missed first time round: Snoopy.class.php 1.5
2004-07-25 02:34:28 CST COMMITcvs checkout ChangeLog 1.22 - version is duplicate
cvs checkout Snoopy.class.php 1.8 - version is duplicate
Missed first time round: ChangeLog 1.20
Missed first time round: Snoopy.class.php 1.6
2004-07-25 08:49:02 CST COMMIT
2004-07-25 10:42:48 CST COMMIT
2004-07-25 10:46:34 CST COMMIT
2004-07-25 10:46:59 CST COMMIT
2004-07-25 11:18:32 CST COMMIT
2004-10-16 13:14:11 CST COMMIT
2004-10-16 13:17:41 CST COMMIT
2004-10-16 13:44:51 CST COMMIT
2004-10-16 14:27:09 CST COMMIT
2004-10-16 14:28:30 CST COMMIT
2004-10-16 14:40:42 CST COMMIT
2004-10-17 00:33:58 CST COMMIT
2004-10-17 00:36:18 CST COMMIT
2004-10-18 13:12:55 CST COMMIT
2004-10-18 13:18:27 CST COMMIT
2004-10-18 13:19:04 CST COMMIT
2004-10-18 13:19:28 CST COMMIT
2004-10-18 13:19:51 CST COMMIT
2004-11-18 13:51:32 CST COMMIT
2004-11-18 13:52:28 CST COMMIT
2004-11-18 14:37:05 CST COMMIT
2005-02-03 12:43:26 CST COMMIT
2005-02-03 12:57:05 CST COMMIT
2005-10-23 10:08:40 CST COMMIT
2005-10-23 10:16:26 CST COMMIT
2005-10-24 00:30:34 CST COMMIT
2005-10-24 23:34:50 CST COMMIT
2005-10-24 23:44:12 CST COMMIT
2005-10-24 23:44:59 CST COMMIT
2005-10-24 23:46:10 CST COMMIT
2005-10-30 13:33:15 CST COMMIT
2005-10-30 13:45:09 CST COMMIT
2005-10-31 02:32:42 CST COMMIT
2005-10-31 02:51:35 CST COMMIT
2005-11-08 14:53:56 CST COMMIT
2005-11-08 15:01:47 CST COMMIT
2008-10-22 23:30:41 CST COMMIT
2008-10-22 23:53:14 CST COMMIT
2008-11-09 05:09:09 CST COMMIT
Emitted 79 commits (= total 79).
Exact 2 + 1 = 3 branches + tags.
Fixup 0 + 0 = 0 branches + tags.
Download 147 cvs versions in 84 transactions.
String cache: 141 items, 132/1024 buckets used, mean search 1.06383
git-fast-import statistics:
---------------------------------------------------------------------
Alloc'd objects: 5000
Total objects: 289 ( 8 duplicates )
blobs : 134 ( 7 duplicates 46 deltas of 133 attempts)
trees : 77 ( 0 duplicates 70 deltas of 71 attempts)
commits: 78 ( 1 duplicates 0 deltas of 0 attempts)
tags : 0 ( 0 duplicates 0 deltas of 0 attempts)
Total branches: 3 ( 2 loads )
marks: 1024 ( 220 unique )
atoms: 15
Memory total: 2294 KiB
pools: 2098 KiB
objects: 195 KiB
---------------------------------------------------------------------
pack_report: getpagesize() = 4096
pack_report: core.packedGitWindowSize = 33554432
pack_report: core.packedGitLimit = 268435456
pack_report: pack_used_ctr = 7
pack_report: pack_mmap_calls = 3
pack_report: pack_open_windows = 1 / 1
pack_report: pack_mapped = 350104 / 350104
---------------------------------------------------------------------
这样这个 Git 仓库就包含了已经转换过了的 CVS 历史记录, 如果看不到文件可以 reset 一下。
按说后续的操作理论上可以在这个仓库目录中操作,但为了更好的和 Fork 的项目合并, 我使用导出 Patch 的方法,后面再 am:
$ git log --pretty=oneline |wc -l
78
$ git format-patch -78
其实在这里,也可以在目标 repo 里面,通过添加 Snoopy.git 为 Git remote, 然后 merge remote 的方式进行,效果更好,还不用修改提交时间。
Fork 项目,移花接木
在 Github 上 Fork https://github.com/hurrycaner/snoopy , 得到 https://github.com/fwolf/snoopy , 但先不下载到本地,后面的操作方法和正常 Fork 项目是 不一样 的。
在本地再新建一个 Git 仓库,这个仓库是我们今后维护 Snoopy 的主仓库:
$ mkdir Snoopy
$ cd Snoopy
$ git init
$ git remote add origin git@github.com:fwolf/snoopy.git
$ touch .gitignore
$ git add .gitignore
$ git commit -a -m "Initial commit"
$ git push -f origin master
和新建项目的方法基本一样,不同点是我们的 origin 是 Fork 后的项目, 并且进行了 push -f 操作,覆盖掉了 hurrycaner 的所有提交。
接下来新建一个 sourceforge 分支,保留 SourceForge 上 CVS 代码的最终状态, 提交是通过 am 导入的, --committer-date-is-author-date 参数是将作者的时间作为提交时间, 也可以不要。Patch 0002 是空的,会导致 am 失败,所以删除掉:
$ git branch sourceforge
$ git checkout sourceforge
$ rm ../Snoopy.git/0002-Initial-check-in.patch
$ git am ../Snoopy.git/00* --committer-date-is-author-date
$ git checkout master
$ git merge sourceforge
$ git push
现在,master 分支上是我作的一个初始提交,加上 CVS 上导过来的提交内容, 相当于是 CVS 被完整的导入了 Git。
添加只有一个空 .gitignore 文件的初始提交是 Git 的一个习惯, 因为 Git 的初始提交可以视为是“不可以操作”的, 所以最好是空或者只包含最少内容。
接下来,我们要将 hurrycaner 所作的修改合并进来。 由于他是基于 Snoopy 1.2.4 代码修改的, 和我导入的最终代码差距不大,所以合并还比较顺利,只有几处冲突而已:
$ git branch hurrycaner
$ git checkout hurrycaner
$ git remote add upstream git@github.com:hurrycaner/snoopy.git
$ git fetch upstream
$ git merge upstream/master # 手工解决冲突
$ git checkout master
$ git merge hurrycaner
$ git push
这就基本上完成了,保留了从 CVS 到 hurrycaner 的完整修改记录, 并且还能像正常 Fork 的项目那样继续工作。
修改记录看起来是这个样子的:
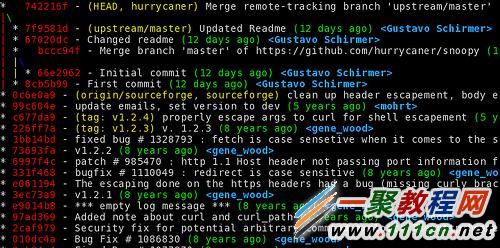
我已经向原项目作者推送 Pull Request 了。 hurrycaner 在 Github 上并不活跃,不知道能不能看到、会不会收啊。
尾声
Git 的使用是比较灵活的,我相信其他分布式 SCM 也能做到,没研究过,不对比。 话说回来,本文中的做法,是不是有点鸠占鹊巢的感觉?
@link https://github.com/fwolf/snoopy
为何NAT里面的主机可以访问NAT外的WEB服务器,但不能获取RTSP流媒体服务器码流?
原因:
对于 HTTP 这样的协议,客户端与 WEB 服务器建立 socket 连接, 是由 WEB 服务器绑定一个固定的 TCP 端口,在这个端口监听。 位于 NAT 后面的客户端随机选择一个 TCP 端口 connect(2) WEB SERVER。
而对于 RTSP 流媒体服务器,采用 RTP 封装多媒体荷载的话,一般的实现是位于客户端这边的播放器看 UDP 5000 这个端口(也可定义为其他端口, 不过主流的播放器大多是这个端口)是否占用, 未占用则绑定这个端口;如果 UDP 5000 这个端口已经被占用了,则向上检查 UDP 5002(习惯上RTP使用偶数号端口,紧挨着的奇数号端口给RTCP使用)等,直到找到一个未使用的端口。然后请求流媒体码流前通过 RTSP 数据包交互告诉服务器播放器这边接收 RTP 数据包的端口, 流媒体服务器随机选择一个端口发送 RTP 包,并把即将启动的会话信息通过 SDP 格式以 RTSP 封装通知播放器。因此,对于 RTP 通信来说, 真正的服务端是在播放器这边,被动地接收 RTSP 服务器那边发送过来的 RTP 码流。
一般类型的 NAT 允许一个数据包通过的条件是:
如果这个数据包是从 NAT 里面的设备向外网发送的, 允许通过。NAT 设备会查看这个数据包的源ip地址与端口及目的地址与端口信息,如果没有建立过映射关系就新建一个NAT映射关系: 把源ip与端口映射为NAT地址与一个新分配的端口,根据NAT设备类型的不同,映射关系不同:
完全锥型、地址受限锥型和端口受限锥型是根据(源IP:源端口)建立一个(NAT地址:端口)的映射,
对称型NAT把(源IP:源端口,目的IP:目的端口)映射为(NAT IP:NAT 端口)。
如果这个数据包是从 NAT 外面发送给里面的,看这个数据包的信息能否在NAT映射表里找到对应的映射,找不到则禁止通过;若找的到,不同类型的 NAT 有不同的处理:
完全锥型: 允许通过。
地址受限锥型: 如果这个映射对应的NAT内部主机之前发送过数据包给这个外网主机,则允许通过,否则不允许。
端口受限锥型: 如果这个映射对应的NAT内部主机之前发送过数据包给这个外网主机的端口,则允许通过,否则不允许。
对称型: 因为映射就包含了源IP、源端口、目的IP、目的端口的所有信息,找到这个映射说明之前NAT里面对应的主机发过包给对应的外网主机,所以允许通过。
因此,位于 NAT 里面的主机可以这样正常的访问外网的 HTTP WEB服务器:发起HTTP请求时, NAT 会为这个会话建立一个映射关系,这样 WEB 服务器回应的包正好匹配这个映射,于是可以被客户端浏览器接收。
但是NAT里面的主机要请求流媒体就不行了:对于 RTSP 来说, 和 HTTP 一样可以正常通信, 关键是对于 RTP 包, 服务端是在 NAT 里面的播放器的,即使 RTSP 知道NAT里面播放器主机的地址以及NAT地址, RTP 包到达 NAT 时,属于上述的2的情况,由于之前没有建立映射关系,这个包将被 NAT 丢弃。
有的流媒体服务器会使用 HTTP 来封装流媒体,可以获取较好的穿透性, 不过需要实现自己的播放器才能解码了。
RTP 丢包的一个原因
用 UDP 封装的 RTP 传输视频码流, 播放出现花屏、马赛克的一个可能原因是丢包严重。UDP 在局域网 丢包不太可能是物理传输中的干扰(一般表现为 UDP 校验出错,可用 netstat -su 查看). 这里说说一个较常见的原因以及表现方式, 从Linux内核的角度来看, 就是 socket 缓存区满, 在播放器读取缓存区之前, 又一个视频码流数据过来, 那么, 这个udp数据包将丢失。
为什么会造成这个socket内核缓存区满呢? 有可能是下面的原因:
播放器的平均处理数据速度小于流媒体服务器端发包速度;
播放器平均处理速度大于对端发包速度, 但是发包速度抖动大, 而且内核socket读缓存区设置过小。
$str="hello world"; //定义字符串
$result=str_pad($str,20); //在原字符串右边填空白
echo $result; //输出转换后的结果
$result=str_pad($str,20,'*'); //在原字符串右边填被"*"
echo $result; //输出结果
$result=str_pad($str,20,'*',str_pad_both); //两边填补
echo $result;
/*
定义和用法
str_ireplace() 函数使用一个字符串替换字符串中的另一些字符。
语法
str_ireplace(find,replace,string,count)参数 描述
find 必需。规定要查找的值。
replace 必需。规定替换 find 中的值的值。
string 必需。规定被搜索的字符串。
count 可选。一个变量,对替换数进行计数。
*/
$number=12345678; //定义一个数字
$result=number_format($number); //执行转换操作
echo $result; //输出转换后的结果
echo "<br>";
$result=number_format($number,2); //带有小数点的结果
echo $result; //输出结果
echo "<br>";
$result=number_format($number,2,'.','.'); //设置小数点符号
echo $result; //输出结果
/*
定义和用法
number_format() 函数通过千位分组来格式化数字。
语法
number_format(number,decimals,decimalpoint,separator)
*/
$str="abcde,abc,abc"; //定义字符串
$result=str_ireplace("ab","zz",$str); //执行转换操作
echo $result; //输出转换后的结果
?>
PHP是一个什么原因出现的呢?它是一个技术人员希望能用一个快速的方面来完成他自己的个人主页中的一个小应用。而在他一发不可收时出现了php,它使一个人能在多种操作系统下迅速的完成一个轻型的Web应用。所以在短短的几年里,php迅速的升级了它的版本,同时在GNU的世界里找到了一个青梅竹马的伙伴----Apache。这终于让php有了基础,能在一个最佳的环境中运行,同时由于两个产品都是公开源代码的产品,所以大家可以使用它们的源代码将这两个产品用最完美的方式结合到一起,使用起来就如一个产品一样。个人认为php是自由软件在web应用平台上一个决胜的工具,假如没有php的出现,还会有许多人认为自由软件就代表了对开发人员的高技术要求、难记的代码、复杂的工具.....php使一个会使用basic的人员在极短的时间里快迅学习并完成用户需要的应用。
怎么说php呢?假如说ASP是一个COM,哪么php说的更精确了可以说php是一个纯粹的Script翻译器。这也是php由3升级为4的一个重大原因,在4这个版本里它重写了语法分析器,从而加快了php整体的效能。而且从中你也就会明白为什么php需要支持这种或是那种扩充功能时它一定要与相应系统的lib库进行再编绎的原因。正因为它是正宗的“翻译器”,所以它是将script翻译成为需要执行的函数,再去执行它们,外部扩充不能由一些“动态加载”的方式进行,所以只能静态的编绎进php中(这只能在windows中除外)。
强势:
1、一种能快速学习、跨平台、有良好数据库交互能力的开发语言。ASP比不上它的就是这种跨平台能力了,而正是它的这种能力让Unix/Linux有了一种与ASP媲美的开发语言。语法简单、书写轻易、现在市面上也有了大量的书,同时Internet上也有大量的代码可以共享,对于一个初学者想学些“高深的Unix”下的开发来说是一个决好的入手点。
2、与Apache及其它扩展库结合紧密。php与Apache可以以静态编绎的方式结合起来,而与其它的扩展库也可以用这样的方式结合(除外的就是Windows平台了)。这样的方式的最大的好处就是最大化的利用了cpu时和内存,同时极为有效的利用了apache的高性能的吞吐能力。同时外部的扩展也是静态连编,从而达到了最快的运行速度。由于与数据库的接口也使用了这样的方式,所以使用的是本地化的调用,这也让数据库发挥了最佳效能。
3、良好的安全性。由于php本身的代码开放所以它的代码在许多工程师手中进行了检测,同时它与apache编绎在一起的方式也可以让它具有灵活的安全设定。所以到现在为止,php具有了公认的安全性能。
弱势:
1、数据库支持的极大变化。由于php的所有的扩展接口都是独立团队开发完成的,同时在开发时为了形成相应数据的个性化操作,所以php虽然支持许多数据库,可是针对每种数据库的开发语言都完全不同。这样形成针对一种数据库的工发工作,在数据库进行升级后需要开发人员进行几乎全部的代码更改工作。而为了让应用支持更多种的数据库,就需要开发人员将同样的数据库操作使用不同的代码写出n种代码库出来,让程序员的工作量大大增大。
2、安装复杂。由于php的每一种扩充模块并不是完全由php本身来完成,需要许多外部的应用库,如图形需要gd库、LDAP需要LDAP库.……这样在安装完成相应的应用后,再联编进php中来。这也就是我以前在代码联盟新闻组中对网友所说的一定要在FreeBSD/Linux/Unix下运行php的原因。只有在这些环境下才能方便的编绎对应的扩展库。这些都是一般开发人员在使用php前所先要面对的问题,正是这样的问题让许多开发人员转而使用其它的开发语言,必竟Unix没有那么多的用户。
3、缺少企业级的支持。没有组件的支持,哪么所有的扩充就只能依靠php开发组所给出的接口,事实上这样的接口还不够多。同时难以将集群、应用服务器这样的特性加入到系统中去。而一个大型的站点或是一个企业级的应用一定需要这样的支持的。注:在php的4.0版本以后加入了对servlet/javabean的支持,也许这样的支持会在以后的版本中更加增强,也许这样的支持会是php以后的企业级支持的起点。
4、缺少正规的商业支持。这也是自由软件一向的缺点,我想在国内php的开发人员正在快速增加,相信在不久的将来,这样的支持能多起来。
5、无法实现商品化应用的开发。由于php没有任何编绎性的开发工作,所有的开发都是基于脚本技术来完成的。所以所有的源代码都无法编译,所以做完成的应用只能是自己或是内部使用,无法实现商品化。
总结:
适用人群:熟悉Unix环境,需要在最少的投入下完成快速的应用开发。
适用平台:FreeBSD/Linux/Unix操作系统、Apache服务器适用应用:Internet高访问量、快速数据库开发的应用。
学习方式:Internet上国内丰富的资源Internet上丰富的源代码资源,完全可以参考这样的例程来完成自己的应用。市场上最近出版的好几本php手册。
推荐开发工具:Home Site/PHPEd
推荐开发环境:FreeBSD 4.1/RedHat 6.1操作系统/Apache 1.3.12/MySQL 3.22/P 200/64M RAM/9G HD
推荐应用环境(最少):FreeBSD 3.5/MySQL 3.22/Apache 1.3.12/P 200/128M RAM/9G HD
推荐应用环境(最佳):FreeBSD 3.5/Sybase 11/Apache 1.3.12/P III 500/512M RAM/18G HD
我们浏览一些网站的时候,往往看到一些新闻是刚刚更新不久的,假如要是人工维护的话,那会是一项非常繁琐的工作。然而,我们可以通过程序来控制实现更新操作,事情就会变得很方便了(我可不是要偷懒)。
在这里,我使用PHP来实现这一功能。其原理就是根据新闻发布的时间逆序排列好,然后在一页面显示新闻连接列表,每一个连接都对应一条新闻内容网页。具体操作如下:
一、首先,在你的站点下建立一个目录,将编辑好的新闻页都保存在此目录下,将来所有的新闻页都放入这里,方便维护。新闻页格式为超文本方式(可别说你还不会HTML),首行为“<HTML><HEAD><TITLE>新闻标题</TITLE></HEAD>”(原因随后解释,一定要在同一行啊!)。
二、编写程序,实现新闻自动更新功能(假设文件名为paixu.php)
源程序如下:
<?php
$fp=array("filename"=>"","filetime"=>"","firstline"=>"");//建立数组,保存文件名、文件首行
$dd=dir('新闻保存目录');//读取新闻文件的保存目录
$i=0;
clearstatcache();
while ($file=$dd->read())//循环读出目录中的文件
{
if(is_file($dd->path."/".$file))
{
$fp[$i]["filename"]=$dd->path."/".$file;//保存文件名
$fr=fopen($dd->path."/".$file,"r");
$fp[$i]["firstline"]=fgetss($fr,60);//去除HTML标记后保存文件首行(也就是为什么我们要把新闻页首行写成要求的格式)
fclose($fr);
if($time=date("Y m d H:i",filemtime($dd->path."/".$file)))//保存文件时间,以此作为排序条件
{
$fp[$i]["filetime"]=$time;
}
$i ;
}
}
$i=count($fp);//保存文件数
$i-=4;
for($j=0;$j<$i;$j )//按照冒泡算法排序
for($k=$i;$k>$j;$k--)
if($fp[$j]["filetime"]<=$fp[$k]["filetime"])
{
$c=$fp[$j]["filetime"];
$fname=$fp[$j]["filename"];
$fcontent=$fp["$j"]["firstline"];
$fp[$j]["filetime"]=$fp[$k]["filetime"];
$fp[$j]["filename"]=$fp[$k]["filename"];
$fp[$j]["firstline"]=$fp[$k]["firstline"];
$fp[$k]["filetime"]=$c;//line30
$fp[$k]["filename"]=$fname;
$fp[$k]["firstline"]=$fcontent;
}
for($i=0;$i<=(count($fp)-4);$i )//读取保存的文件信息,做好相应连接
{
echo "<tr><td>";
echo "<a href=".$fp[$i]["filename"].">".$fp[$i]["firstline"]."</a>";
echo "</td><td class=font1>";
echo "(".$fp[$i]["filetime"].")<br> ";
echo"</td></tr>";
}
$dd->close();
?>
三、将程序和目录放到你的网站上,然后在浏览器敲入HTTP://网站名/目录/panxu.php,能看到吗?
本程序仅仅提供了基本的功能,你可以增加更多的控制功能,还有页面的修饰和美化等工作,就要靠你自己了。
相关文章
- 本篇文章主要分享了通过window.navigator来判断浏览器及其版本信息的实例代码。具有一定的参考价值,下面跟着小编一起来看下吧...2017-01-23
- 支付接口现在有第三方的支付接口也有银行的支付接口了,今天我们来介绍php版本银联支付接口开发实例了,这个我估计可以帮助到不少的朋友的哦。 银联支付,首先要注意二...2016-11-25
- 使用 conditional comment 来判断 IE 的版本。嗯,是早早有人提出,但没有认真看代码。昨天刚好在看 CSS3 PIE 的时候看到,觉得是不是不靠谱。今天看到 Paul Irish 也提起,那么,推荐一下吧。这是作者博客上写的:复制代码 代码...2014-05-31
- 这篇文章介绍的是一个小技巧来获取node.js项目根目录,这个技巧非常实用。有需要的朋友们可以参考借鉴,下面来一起看看吧。...2016-10-02
- 这篇文章主要介绍了基于Pycharm加载多个项目过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-04-22
intellij idea如何将web项目打成war包的实现
这篇文章主要介绍了intellij idea如何将web项目打成war包的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-07-04- 这篇文章主要为大家详细介绍了C#如何检测操作系统版本的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-06-25
Idea打包springboot项目没有.original文件解决方案
这篇文章主要介绍了Idea打包springboot项目没有.original文件解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-07-26SpringBoot高版本修改为低版本时测试类报错的解决方案
这篇文章主要介绍了SpringBoot高版本修改为低版本时测试类报错的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-09-18- 这篇文章主要介绍了Tomcat首次部署web项目流程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-12-11
- 在jquery.1.9以前的版本,可以使用$.browser很轻松的判断浏览器的类型和版本,但是在1.9中和以后的版本中,$.browser已经被删除,下面就介绍一下如何实现此功能,希望能够给需要的朋友带来帮助...2016-01-14
- 如果说是JQuery是手工作坊,那么Vue.js就像是一座工厂,虽然Vue.js做的任何事情JQuery都可以做,但无论是代码量还是流程规范性都是前者较优,下面这篇文章主要给大家介绍了关于Vue项目中如何运用vuex的相关资料,需要的朋友可以参考下...2021-09-29
- 这篇文章主要介绍了react+ts实现简单jira项目,本文通过图文实例相结合给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-07-30
永久解决 Intellij idea 报错:Error :java 不支持发行版本5的问题
这篇文章主要介绍了永久解决 Intellij idea 报错:Error :java 不支持发行版本5的问题,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-02-20- 下面小编就为大家带来一篇Angularjs---项目搭建图文教程。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2016-07-25
- 大家使用idea开发工具时经常会需要导入项目框架,纠结该怎么操作呢,今天小编给大家分享一篇图文教程,帮助大家解决idea导入项目框架的问题,感兴趣的朋友一起看看吧...2021-05-11
- 这篇文章主要介绍了idea导入项目不显示maven侧边栏的问题及解决方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-07-22
- 这篇文章主要介绍了Springcloud实现服务多版本控制的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-05-15
- 这篇文章主要为大家详细介绍了C#获取系统当前IE版本号,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-06-25
- 这篇文章主要介绍了.Net Core库类项目跨项目读取配置文件的方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2021-09-22