PHP 正则表达式入门篇
参考效果图
介绍
正则表达式,大家在开发中应该是经常用到,现在很多开发语言都有正则表达式的应用,比如javascript,java,.net,php等等,我今天就把我对正则表达式的理解跟大家唠唠,不当之处,请多多指教!
需要知道的术语——下面的术语你知道多少?
Δ 定界符
Δ 字符域
Δ 修饰符
Δ 限定符
Δ 脱字符
Δ 通配符(正向预查,反向预查)
Δ 反向引用
Δ 惰性匹配
Δ 注释
Δ 零字符宽
定位
我们什么时候使用正则表达式呢?不是所有的字符操作都用正则就好了,php在某些方面用正则反而影响效率。当我们遇到复杂文本数据的解析时候,用正则是比较好的选择。
优点
正则表达式在处理复杂字符操作的时候,可以提高工作效率,也在一定程度节省你的代码量。
缺点
我们在使用正则表达式的时候,复杂的正则表达式会加大代码的复杂度,让人很难理解。所以我们有的时候需要在正则表达式内部添加注释。
通用模式
¤ 定界符,通常使用 "/"做为定界符开始和结束,也可以使用"#"。
什么时候使用"#"呢?一般是在你的字符串中有很多"/"字符的时候,因为正则的时候这种字符需要转义,比如uri。
使用"/"定界符的代码如下.
| 代码如下 | 复制代码 |
|
$regex = '/^http://([w.]+)/([w]+)/([w]+).html$/i'; if(preg_match($regex, $str, $matches)){ echo "n"; |
|
preg_match中的$matches[0]将包含与整个模式匹配的字符串。
使用"#"定界符的代码如下.这个时候对"/"就不转义!
| 代码如下 | 复制代码 |
|
$regex = '#^http://([w.]+)/([w]+)/([w]+).html$#i'; if(preg_match($regex, $str, $matches)){ echo "n"; |
|
¤ 修饰符:用于改变正则表达式的行为。
我们看到的('/^http://([w.]+)/([w]+)/([w]+).html/i')中的最后一个"i"就是修饰符,表示忽略大小写,还有一个我们经常用到的是"x"表示忽略空格。
贡献代码:
| 代码如下 | 复制代码 |
|
$regex = '/HELLO/'; if(preg_match($regex, $str, $matches)){ if(preg_match($regex.'i', $str, $matches)){
|
|
¤ 字符域:[w]用方括号扩起来的部分就是字符域。
¤ 限定符:如[w]{3,5}或者[w]*或者[w]+这些[w]后面的符号都表示限定符。现介绍具体意义。
{3,5}表示3到5个字符。{3,}超过3个字符,{,5}最多5个,{3}三个字符。
* 表示0到多个
+ 表示1到多个。
¤ 脱字符号
^:
> 放在字符域(如:[^w])中表示否定(不包括的意思)——“反向选择”
> 放在表达式之前,表示以当前这个字符开始。(/^n/i,表示以n开头)。
注意,我们经常管""叫"跳脱字符"。用于转义一些特殊符号,如".","/"
通配符(lookarounds):断言某些字符串中某些字符的存在与否!
lookarounds分两种:lookaheads(正向预查 ?=)和lookbehinds(反向预查?<=)。
> 格式:
正向预查:(?=) 相对应的 (?!)表示否定意思
反向预查:(?<=) 相对应的 (?<!)表示否定意思
前后紧跟字符
| 代码如下 | 复制代码 |
|
$regex = '/(?<=c)d(?=e)/'; /* d 前面紧跟c, d 后面紧跟e*/ if(preg_match($regex, $str, $matches)){ echo "n"; |
|
否定意义:
| 代码如下 | 复制代码 |
|
$regex = '/(?<!c)d(?!e)/'; /* d 前面不紧跟c, d 后面不紧跟e*/ if(preg_match($regex, $str, $matches)){ echo "n"; |
|
>字符宽度:零
验证零字符代码
| 代码如下 | 复制代码 |
|
$regex = '/HE(?=L)LO/i'; if(preg_match($regex, $str, $matches)){ echo "n"; |
|
打印不出结果!
| 代码如下 | 复制代码 |
|
$regex = '/HE(?=L)LLO/i'; if(preg_match($regex, $str, $matches)){ echo "n"; |
|
能打印出结果!
说明:(?=L)意思是HE后面紧跟一个L字符。但是(?=L)本身不占字符,要与(L)区分,(L)本身占一个字符。
捕获数据
没有指明类型而进行的分组,将会被获取,供以后使用。
> 指明类型指的是通配符。所以只有圆括号起始位置没有问号的才能被捕捉。
> 在同一个表达式内的引用叫做反向引用。
> 调用格式: 编号(如1)。
| 代码如下 | 复制代码 |
|
$regex = '/^(Chuanshanjia)[ws!]+1$/'; if(preg_match($regex, $str, $matches)){ echo "n";
|
|
> 避免捕获数据
格式:(?:pattern)
优点:将使有效反向引用数量保持在最小,代码更加、清楚。
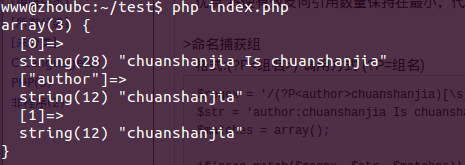
>命名捕获组
格式:(?P<组名>) 调用方式 (?P=组名)
| 代码如下 | 复制代码 |
|
$regex = '/(?P<author>chuanshanjia)[s]Is[s](?P=author)/i'; if(preg_match($regex, $str, $matches)){ echo "n"; |
|
运行结果
惰性匹配(记住:会进行两部操作,请看下面的原理部分)
格式:限定符?
原理:先匹配"?"前面的部分,然后再匹配右侧表达式,右侧表达式匹配成功则整个匹配结束。
先看下面的两个代码:
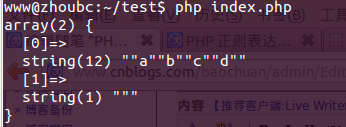
代码1.
| 代码如下 | 复制代码 |
|
$regex = '/(")[^1]+1/i'; if(preg_match($regex, $str, $matches)){ echo "n";
|
|
结果1.
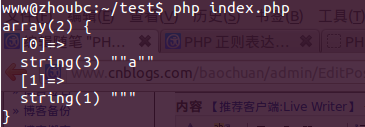
代码2
| 代码如下 | 复制代码 |
|
$regex = '/(")[^1]+?1/i'; if(preg_match($regex, $str, $matches)){ echo "n"; |
|
结果2
分析:
比较两个正则表达式:第一个加了"?",第二个没有。
结果:主要看第一个参数:第一个把所有字符打印了出来,第二个只打印了个""a"".
结论:
>> 首先满足(")[^1]+1条件的有
"a", "a""b","a""b""c", "a""b""c""d", "b","b""c","b""c""d", "c","c""d", "d"
而第一个正则表达式却选择了最大的"a""b""c""d",说明非惰性匹配会把最大的匹配结果拿出来做比较。
>> 第二个正则表达式:先匹配(")[^1]+,如果匹配成功,那么我们在匹配“?”右边的1,如果匹配成功,则整个匹配结束。
其他案例:
| 代码如下 | 复制代码 |
| "Oh, "my" God" =====> /(")([^1] | \1)*?(?<!\)1/i |
|
正则表达式的注释
格式:(?# 注释内容)
用途:主要用于复杂的注释
贡献代码:是一个用于连接MYSQL数据库的正则表达式
| 代码如下 | 复制代码 |
|
$regex = '/ $str = 'host=192.168.10.221|root|123456'; if(preg_match($regex, $str, $matches)){ echo "n"; |
|
| 特殊字符 | 解释 |
| * | 0到多次 |
| + | 1到多次还可以写成{1,} |
| ? | 0或1次 |
| . | 匹配除换行符外的所有单个的字符 |
| w | [a-zA-Z0-9_] |
| s | 空白字符(空格,换行符,回车符)[tnr] |
| d | [0-9] |
这是最简单的了
| 代码如下 | 复制代码 |
|
<?php $tx=’表头’; |
|
如果你一定要输入xls标准的excel文件可参考下面方法
/**
* 输出XLS的头信息
* 注:使用此函数前后都不应有任何数据输出
* @param $data Array 下载的数据
* @param $file_name String 下载的文件名
*/
| 代码如下 | 复制代码 |
|
function outputXlsHeader($data,$file_name = 'export') foreach ($data as $line)
|
|
下面还推荐一下第三方的做法
引用google code中推荐的小类库(大体同方法一,比较复杂点)
http://code.google.com/p/php-excel/downloads/list
PHPEXCEL 类库,功能强大,支持win Excel2003 ,Win Excel2007
本文章介绍一正则表达式的基础与在asp,php,javascript中这些常用到一些如何电话,手机,邮箱,正数,字母,用户名等正则,有需要的同学可以参考一下。一些常用的正则表达式
“^d+$” //非负整数(正整数 + 0)
“^[0-9]*[1-9][0-9]*$” //正整数
“^((-d+)|(0+))$” //非正整数(负整数 + 0)
“^-[0-9]*[1-9][0-9]*$” //负整数
“^-?d+$” //整数
“^d+(.d+)?$” //非负浮点数(正浮点数 + 0)
“^(([0-9]+.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*.[0-9]+)|([0-9]*[1-9][0-9]*))$” //正浮点数
“^((-d+(.d+)?)|(0+(.0+)?))$” //非正浮点数(负浮点数 + 0)
“^(-(([0-9]+.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*.[0-9]+)|([0-9]*[1-9][0-9]*)))$” //负浮点数
“^(-?d+)(.d+)?$” //浮点数
“^[A-Za-z]+$” //由26个英文字母组成的字符串
“^[A-Z]+$” //由26个英文字母的大写组成的字符串
“^[a-z]+$” //由26个英文字母的小写组成的字符串
“^[A-Za-z0-9]+$” //由数字和26个英文字母组成的字符串
“^w+$” //由数字、26个英文字母或者下划线组成的字符串
“^[w-]+(.[w-]+)*@[w-]+(.[w-]+)+$” //email地址
“^[a-zA-z]+://(w+(-w+)*)(.(w+(-w+)*))*(?S*)?$” //url
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
“^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$” //Emil
“(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?” //电话号码
“^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$” //IP地址
匹配中文字符的正则表达式: [u4e00-u9fa5]
匹配双字节字符(包括汉字在内):[^x00-xff]
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/<(.*)>.*</1>|<(.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
匹配国内电话号码:(d{3}-|d{4}-)?(d{8}|d{7})?
匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$
javascript中应用
计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
| 代码如下 | 复制代码 |
|
String.prototype.len=function(){return this.replace([^x00-xff]/g,”aa”).length;} |
|
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/<(.*)>.*</1>|<(.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:
| 代码如下 | 复制代码 |
|
String.prototype.trim = function() |
|
利用正则表达式分解和转换IP地址:
下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
| 代码如下 | 复制代码 |
|
function IP2V(ip) |
|
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
| 代码如下 | 复制代码 |
|
var ip=”10.100.20.168″ |
|
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
利用正则表达式去除字串中重复的字符的算法程序:[注:此程序不正确,原因见本贴回复]
| 代码如下 | 复制代码 |
|
var s=”abacabefgeeii” |
|
我原来在CSDN上发贴寻求一个表达式来实现去除重复字符的方法,最终没有找到,这是我能想到的最简单的实现方法。思路是使用后向引用取出包括重复的字符,再以重复的字符建立第二个表达式,取到不重复的字符,两者串连。这个方法对于字符顺序有要求的字符串可能不适用。
得用正则表达式从URL地址中提取文件名的javascript程序,如下结果为page1
| 代码如下 | 复制代码 |
|
s=”http://www.111cn.net/nokia/5230/” |
|
php中正则函数和用法
preg_match()和preg_match_all()
preg_quote()
preg_split()
preg_grep()
preg_replace()
函数的具体使用,我们可以通过PHP手册来找到,下面分享一些平时积累的正则表达式:
匹配action属性
以下为引用的内容:
| 代码如下 | 复制代码 |
| $str = ''; $match = ''; preg_match_all('/s+action="(?!http:)(.*?)"s/', $str, $match); print_r($match); |
|
在正则中使用回调函数
| 代码如下 | 复制代码 |
|
/**
|
|
一些正则基本语法
x|y 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。
[xyz] 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。
[^xyz] 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。
[a-z] 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。
[^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。
b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'erb' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
B 匹配非单词边界。'erB' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。
cx 匹配由 x 指明的控制字符。例如, cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。
d 匹配一个数字字符。等价于 [0-9]。
D 匹配一个非数字字符。等价于 [^0-9]。
f 匹配一个换页符。等价于 x0c 和 cL。
n 匹配一个换行符。等价于 x0a 和 cJ。
r 匹配一个回车符。等价于 x0d 和 cM。
s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ fnrtv]。
S 匹配任何非空白字符。等价于 [^ fnrtv]。
t 匹配一个制表符。等价于 x09 和 cI。
v 匹配一个垂直制表符。等价于 x0b 和 cK。
w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
W 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。
首先是一个文件看能不能读取(权限问题),或者存在不,我们可以用is_readable函数获取信息.:
php/func_filesystem_is_readable.htm">is_readable函数用法
| 代码如下 | 复制代码 |
|
<?php |
|
输出:
test.txt is readable
利用file_get_contents函数来读取文件,这个函数可以读取大数据量的文件,也可以读取远程服务器文件,但必须在php.ini开始allow_url_fopen = On否则此函数不可用。
| 代码如下 | 复制代码 |
|
<?php $file = "filelist.php"; if (file_exists($file) == false) { die('文件不存在'); } $data = file_get_contents($file); echo htmlentities($data); ?> |
|
读取远程 文件,这是本教程这外的话题了。
| 代码如下 | 复制代码 |
|
function vita_get_url_content($url) { |
|
利用fread函数
来读取文件,这个函数可以读取指定大小的数据量
//fread读取文件实例一
| 代码如下 | 复制代码 |
|
$filename = "/www.111cn.net/local/something.txt"; |
|
//php5以上版本读取远程服务器内容
| 代码如下 | 复制代码 |
|
$handle = fopen("http://www.111cn.net/", "rb"); |
|
还有一种方式,可以读取二进制的文件:
| 代码如下 | 复制代码 |
|
$data = implode('', file($file)); |
|
fwrite 文件的写操作
fwrite() 把 string 的内容写入文件指针 file 处。 如果指定了 length,当写入了 length 个字节或者写完了 string 以后,写入就会停止,视乎先碰到哪种情况。
fwrite() 返回写入的字符数,出现错误时则返回 false。
文件写入函式:
| 代码如下 | 复制代码 |
| <?php //文件写入函式 function PHP_Write($file_name,$data,$method="w") { $filenum=@fopen($file_name,$method); flock($filenum,LOCK_EX); $file_data=fwrite($filenum,$data); fclose($filenum); return $file_data; } ?> |
|
正则表达式(Regular Expression)
正则表达式系统:
1.POSIX
2.Perl
PHP中使用的regex是PCRE:
NOTE:PCRE(Perl兼容正则表达式,Perl Compatible Regular Expressions)
PCRE语法:
1.定界符
必须成对出现,可以使用除0-9a-zA-Z以外的任何字符
2.原子
1.正则需要匹配的可见和不可见字符都是原子
2.一个正则表达式最少含有一个原子
3.当需要匹配诸如"("、"["、"^"等含有语义的符号时需要用""反斜线进行转义
原子字符:
f 匹配换页符
n 匹配换行符
r 匹配回车符
t 匹配制表符
v 匹配垂直制表符
3.元字符
转义字符
^ 匹配字符串起始处
$ 匹配字符串末尾
. 匹配除"n"之外的任何单个字符
* 匹配前面的子表达式0或多次
+ 匹配前面的子表达式1次或多次
? 匹配前面的子表达式0次或1次
{n} 匹配n次
{n,} 匹配n次或n次以上
{n,m} 最少匹配n次至多匹配m次,(n<=m)
[] 中括号代表原子表,中间的原子地位都是相等。在匹配的时候,匹配表中的任意一个字符
[^] 抑扬符,排除后面的原子表所包含的字符。
(pattern) 匹配pattern并获取这一匹配。
num 对获取的第num个匹配的引用。
(?:pattern) 匹配pattern但不获取这一匹配
(?=pattern) 正向肯定预查,非获取匹配,例如:windows(?=XP|7)能匹配windowsXP中的windows不能匹配windows98中的windows
(?!=pattern) 正向否定欲查非获取匹配,例如:windows(?!98|2000),能匹配windowsXP中的windows,不能匹配windows98中的windows
(?<=pattern) 反向肯定预查,非获取匹配。例如:(?<=My|Postgre)SQL能匹配MySQL中的SQL,不能匹配MSSQL中的SQL
(?<!pattern) 反向否定预查,非获取匹配。例如:(?<!My|Postgre)SQL能匹配MSSQL中的SQL,不能匹配MySQL中的SQL
b 匹配单词边界
B 匹配除单词边界以外的字符
d 匹配任何一个数字。等价于[0-9]
D 匹配任何一个非数字以外的字符。等价于[^0-9]
s 匹配任何一个空白字符(包括空格、制表符、换页符等)。等价于[fnrtv]
S 匹配任何一个非空白字符。等价于[^fnrtv]
w 匹配任何一个数字、字母或下划线。等价于[0-9a-zA-Z]
W 匹配任何一个非数字、字母或下划线的字符。等价于[^0-9a-zA-Z]
4.模式修正符
i 不区分大小写
m 此模式中如果有回车或换行,^和$将匹配每行的行首和行尾
s 让.能匹配n
x 忽略空白
U 取消贪婪,相当于(.*?)
A 与^效果一样
D 结尾处不忽略回车 ,在结束处有$符的时候,在匹配的字符串后面加上回车,$依然能够匹配它成功。但是加上D之后,结尾的回车,不再匹配
NOTE:正则表达式是从左向右进行匹配的
常用的正则表达式
1、非负整数:”^d+$”
2、正整数:”^[0-9]*[1-9][0-9]*$”
3、非正整数:”^((-d+)|(0+))$”
4、负整数:”^-[0-9]*[1-9][0-9]*$”
5、整数:”^-?d+$”
6、非负浮点数:”^d+(.d+)?$”
7、正浮点数:”^((0-9)+.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*.[0-9]+)|([0-9]*[1-9][0-9]*))$”
8、非正浮点数:”^((-d+.d+)?)|(0+(.0+)?))$”
9、负浮点数:”^(-((正浮点数正则式)))$”
10、英文字符串:”^[A-Za-z]+$”
11、英文大写串:”^[A-Z]+$”
12、英文小写串:”^[a-z]+$”
13、英文字符数字串:”^[A-Za-z0-9]+$”
14、英数字加下划线串:”^w+$”
15、E-mail地址:”^[w-]+(.[w-]+)*@[w-]+(.[w-]+)+$”
16、URL:”^[a-zA-Z]+://(w+(-w+)*)(.(w+(-w+)*))*(?s*)?$”
下面这个用PHP写的函数,可以获取任意的字符串$string中的所有链接地址($string可以是从一个HTML页面文件直接读取出来的字符串),结果保存在一个数组中返回.该函数自动把电子邮件地址排除在外,而且返回的数组中不会有重复元素.
| 代码如下 | 复制代码 |
|
function GetAllLink($string) $regex[url] = "((http|https|ftp|telnet|news)://)?([a-z0-9_-/.]+.[][a-z0-9:;&#@=_~%?/.,+-]+)"; //去掉标签之间的文字 //去掉JAVASCRIPT代码 |
|
//去掉非<a>的HTML标签
| 代码如下 | 复制代码 |
|
$string = eregi_replace("<[^a][^<>]*>","", $string); //去掉EMAIL链接 //替换需要的网页链接 $output[0] = strtok($string, "t"); return $output; |
|
以下是以PHP的语法所写的示例
验证字符串是否只含数字与英文,字符串长度并在4~16个字符之间
| 代码如下 | 复制代码 |
|
<?php |
|
简易的台湾身分证字号验证
| 代码如下 | 复制代码 |
|
<?php |
|
下面的代码实现文字中的代码块,功能就如你在脚本之家看到的代码一样。
| 代码如下 | 复制代码 |
|
function codedisp($code) { |
|
相关文章
- 取双引号内的内容我们如果一个字符串中只有一个可以使用explode来获得,但如果有多个需要使用正则表达式来提取了,具体的例子如下。 写程序的时候总结一点经验,如何只...2016-11-25
- 这篇文章主要给大家介绍了一个关于JS正则匹配的踩坑记录,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-04-13
- 今天遇到一个正则匹配的问题,忽然翻到有捕获组的概念,手册上也是一略而过,百度时无意翻到C#和Java中有对正则捕获组的特殊用法,搜索关键词有PHP时竟然没有相关内容,自己试了一下,发现在PHP中也是可行的,于是总结一下,分享的同...2015-11-08
- 正则表达式是一门非常有用的并且进行模糊判断的一个功能了,我们下面来看通过正则来验证输入汉字、英语、数字,具体如下。 收藏了正则表达式。可以验证只能输入数...2016-11-25
- 这篇文章主要介绍了java正则表达式判断前端参数修改表中另一个字段的值,需要的朋友可以参考下...2021-05-07
- 常用的日期时间正则表达式 下面收藏了大量的日期时间正则匹配函数,包括分钟,时间与秒都能达到。 正则表达式 (?n:^(?=d)((?<day>31(?!(.0?[2469]|11))|30(?!.0?2)|29(...2016-11-25
- 网址规则是可寻的,所以我们可以使用正则表达式来提取字符串中的url地址了,下面一起来看看小编整理的几个PHP正则表达式匹配验证提取网址URL实例. 匹配网址 URL 的...2016-11-25
- 这篇文章主要介绍了正则表达式中两个反斜杠的匹配规则,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-05-07
- 这篇文章给大家详细介绍了JS中使用正则表达式g模式和非g模式的区别,非常不错,具有参考借鉴价值,需要的朋友参考下吧...2017-04-03
- 本文主要介绍了JavaScript利用正则表达式替换字符串中内容的具体实现方法,并做了简要注释,便于理解。具有一定的参考价值,需要的朋友可以看下...2017-01-09
- 这篇文章主要介绍了C#正则表达式使用方法,大家参考使用...2020-06-25
- c#正则表达式,用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。...2020-06-25
- 这篇文章主要介绍了python正则表达式常用函数及使用方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-05-07
- 这篇文章给大家介绍了Idea使用正则表达式批量替换字符串的方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧...2021-07-21
- 关于匹配字符串问题,有很多种类型,今天讨论 js 代码里的字符串匹配,因为我想学完之后写个语法高亮练手,所以用js代码当作例子...2021-05-07
- 今天遇到一个正则匹配的问题,忽然翻到有捕获组的概念,手册上也是一略而过,百度时无意翻到C#和Java中有对正则捕获组的特殊用法,搜索关键词有PHP时竟然没有相关内容,自己试了一下,发现在PHP中也是可行的,于是总结一下,分享的同...2015-11-08
- 正则表达式的作用用来描述字符串的特征。本文重点给大家介绍C# 中使用正则表达式匹配字符的含义,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧...2020-06-25
- 这篇文章主要给大家介绍了关于利用Python验证的50个常见正则表达式的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-11
- 这篇文章主要介绍了C#运算符和表达式,这是自学C#编程的第五篇,希望对大家的学习有所帮助。...2020-06-25
- 这篇文章主要介绍了PHP正则表达式过滤html标签属性的相关内容,实用性非常,感兴趣的朋友参考下吧...2016-05-06