php按文件生成时间排序列出目录下的所有文件
先看文件列表:

| 代码如下 | 复制代码 |
|
$dir=’ass’;
$dp = dir($dir); while ($file = $dp ->read()){ $filename=$dir.’/’.$file; if($file!=’.'&&$file!=’..’){ $key=filectime($filename)*1000+rand(100,999); $files[strval($key)]=$filename; } } echo ‘<pre>’; print_r($files); ksort($files); print_r($files); $keys = range(1,count($files)); $arr=array_combine($keys,$files); print_r($arr); echo ‘</pre>’; |
|
打印结果:

| 代码如下 | 复制代码 |
Array
(
[1] => 第十五课.ass
[2] => 第二十一课.ass
[3] => 第二十课.ass
[4] => 第九课.ass
[5] => 第二十六课.ass
[6] => 第四课.ass
[7] => 第十七课.ass
[8] => 第二十二课.ass
[9] => 第七课.ass
[10] => 第三课.ass
[11] => 第十八课.ass
)
|
|
这两天抽空写了个网页服务器状态监控,看到有朋友说需要,那我就放出来吧。很简单的东西。
使用方法
打开压缩包里面的status.php文件。编辑这里的内容为你自己的邮箱信息。
| 代码如下 | 复制代码 |
|
$mail->Host = 'smtp.exmail.qq.com'; // SMTP 服务器 | |
更改这里的内容为你要监控的IP
| 代码如下 | 复制代码 |
|
$server_ip_list = array( | |
然后访问你http://yourdomain.com/status.php文件,即可看到当前服务器状态并且自动发送邮件到你设置的邮箱。如果需要自动监控,请添加Cron任务或者使用什么监控宝之类的!
完整代码
| 代码如下 | 复制代码 |
|
<?php */ if (!$fp) { $i++; ?> | |
注意:
include './smtp/class.smtp.php';
include './smtp/class.phpmailer.php';
文件可以下载phpmailer包然后我们在包里面这两个文件复制出来然后即可使用了。
ps:这个只是一个非常的简单的不能很好的监控到服务器了,现在有很多成熟的免费产品都可以更好的达到我们要求,如dnspod里面有一个D监控了,然后我们就可以操作。
提取内容是一个比较有意思的项目了,今天要做一个这样的小搜索引擎了,下面小编就给各位介绍一个php提取网页正文内容的例子,希望能给各位带来帮助。Html2Article-php实现的提取网页正文部分,最近研究百度结果页的资讯采集,其中关键环节就是从采集回的页面中提取出文章。
因为难点在于如何去识别并保留网页中的文章部分,而且删除其它无用的信息,并且要做到通用化,不能像火车头那样根据目标站来制定采集规则,因为搜索引擎结果中有各种的网页。
抓回一个页面的数据,如何匹配出正文部分,郑晓在下班路上想了个思路是:
1. 提取出body标签部分–>剔除所有链接–>剔除所有script、注释–>剔除所有空白标签(包括标签内不含中文的)–>获取结果。
2. 直接匹配出非链接的、 符合在div、p、h标签中的中文部分???
还是会有不少其它多余信息啊,比如底部信息等。。 如何搞?不知道大家有木有什么思路或建议?
这个类是从网上找到的一个php实现的提取网页正文部分的算法,郑晓在本地也测试了下,准确率非常高。
| 代码如下 | 复制代码 |
|
<?php class Readability { // DOM 解析类目前只支持 UTF-8 编码 // 当判定失败时显示的内容 // DOM 解析类(PHP5 已内置) // 需要解析的源代码 // 章节的父元素列表 // 需要删除的标签 private $junkTags = Array("style", "form", "iframe", "script", "button", "input", "textarea", // 需要删除的属性
// DOM 解析类只能处理 UTF-8 格式的字符 // 预处理 HTML 标签,剔除冗余的标签等 // 生成 DOM 解析类 foreach ($this->DOM->childNodes as $item) { // insert proper
// Replace all doubled-up <BR> tags with <P> tags, and remove fonts. // @see https://github.com/feelinglucky/php-readability/issues/7 return trim($string);
/** $i = 0; return $RootNode; /** // Study all the paragraphs and find the chunk that has the best score. // Look for a special classname // Look for a special ID // Add a point for the paragraph found // 保存父元素的判定得分 // 保存章节的父元素,以便下次快速获取 $topBox = null; if ($contentScore && $contentScore > $orgContentScore) {
if ($titleNodes->length return null;
if ($images->length && $leadImage = $images->item(0)) { return null;
// 获取页面标题 // 获取页面主内容 // 删除不需要的标签 // 删除不需要的属性 $content = mb_convert_encoding($Target->saveHTML(), Readability::DOM_DEFAULT_CHARSET, "HTML-ENTITIES"); // 多个数据,以数组的形式返回 function __destruct() { } |
|
使用起来也非常简单,实例化时传入网页的html源码和相应的编码,然后直接调用其getContent方法即可返回提取到的正文部分,提取出的文章中可能还会含有少部分链接,可以自己后期再修改
需求是这样的:
找到数组中所有可能的指定长度的组合,要求没有重复。
方法一:
| 代码如下 | 复制代码 |
|
function getCombinationToString($arr,$m){ $temp_list2 = getCombinationToString($arr, $m); var_dump($t); |
|
执行时间:238ms。
方法二:
| 代码如下 | 复制代码 |
|
function getCombinAryByNum( $arr, $num,$t=array()) { $arr = array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18); var_dump($ss); |
|
执行时间:710ms。
微信支付接口现在也慢慢的像支付宝一个可以利用api接口来实现第三方网站或应用进行支付了,下文整理了一个php微信支付接口开发程序并且己测试,有兴趣的朋友可进入参考。必要条件:
appid //公众号后台开发者中心获得(和邮件内的一样) mchid//邮件内获得 key//商户后台自己设置 appsecret //公众号开发者中心获得
两个证书文件,邮件内获得 apiclient_cert.pem apiclient_key.pem
注意事项:
公众号后台微信支付-》开发配置-》新增测试目录和测试个人微信号。
开发者中心-》网页授权获取用户基本信息-》修改成你的测试域名。否则会出现redirect_uri 参数错误
——————————后续待完善——————-
微信支付就绪页面后台自行了三次操作:
1.获取openid
//使用jsapi接口
| 代码如下 | 复制代码 |
| $jsApi = new JsApi_pub(); //=========步骤1:网页授权获取用户openid============ //通过code获得openid if (!isset($_GET['code'])) { //触发微信返回code码 $url = $jsApi->createOauthUrlForCode(WxPayConf_pub::JS_API_CALL_URL); //echo $url; Header("Location: $url"); }else { //获取code码,以获取openid $code = $_GET['code']; $jsApi->setCode($code); $openid = $jsApi->getOpenid(); } |
|
刚开始的时候第一步也遇到问题,没饭获得openid这个和部分服务器有关,demo内用的是curl获取的方式。奇怪我的服务器curl一直无法获取到。后来改成file_get_contents可以正常获取了。可这并不是解决之道。因为后面还需要用到更多的curl操作。看到开发文档里面有一个地方写证书操作需要libcurl 7.20.1以上版本,然后我就一直在整服务器想把linux的php curl版本提高。最后面我是换到了另外一台windows服务器就好了。先暂时这样吧,下次需要用的时候再调试。
第二步:获取与支付订单号id
| 代码如下 | 复制代码 |
| $unifiedOrder = new UnifiedOrder_pub(); //var_dump($unifiedOrder); //设置统一支付接口参数 //设置必填参数 //appid已填,商户无需重复填写 //mch_id已填,商户无需重复填写 //noncestr已填,商户无需重复填写 //spbill_create_ip已填,商户无需重复填写 //sign已填,商户无需重复填写 $unifiedOrder->setParameter("openid","$openid");//商品描述 $unifiedOrder->setParameter("body","贡献一分钱");//商品描述 //自定义订单号,此处仅作举例 $timeStamp = time(); $out_trade_no = WxPayConf_pub::APPID."$timeStamp"; $unifiedOrder->setParameter("out_trade_no","$out_trade_no");//商户订单号 $unifiedOrder->setParameter("total_fee","1");//总金额 $unifiedOrder->setParameter("notify_url",WxPayConf_pub::NOTIFY_URL);//通知地址 $unifiedOrder->setParameter("trade_type","JSAPI");//交易类型 //非必填参数,商户可根据实际情况选填 //$unifiedOrder->setParameter("sub_mch_id","XXXX");//子商户号 //$unifiedOrder->setParameter("device_info","XXXX");//设备号 //$unifiedOrder->setParameter("attach","XXXX");//附加数据 //$unifiedOrder->setParameter("time_start","XXXX");//交易起始时间 //$unifiedOrder->setParameter("time_expire","XXXX");//交易结束时间 //$unifiedOrder->setParameter("goods_tag","XXXX");//商品标记 //$unifiedOrder->setParameter("openid","XXXX");//用户标识 //$unifiedOrder->setParameter("product_id","XXXX");//商品ID $prepay_id = $unifiedOrder->getPrepayId(); //echo 'prepay_id:'; var_dump($prepay_id); |
|
这一步也遇到非常多的问题。
首先微信支付测试比较困难,只有在微信内才可以测试。我就用手机刷来刷去。其次使用var_dump调试也不好使额。打印一些 xml格式的文件只显示字符长度,不显示内容。于是用log的形式写在服务器上调试,log代码:
| 代码如下 | 复制代码 |
| // 打印log function log_d($word) { $log_name="./logd.log";//log文件路径 $fp = fopen($log_name,"a"); flock($fp, LOCK_EX) ; fwrite($fp,"执行日期:".strftime("%Y-%m-%d-%H:%M:%S",time())."n".$word."nn"); flock($fp, LOCK_UN); fclose($fp); } |
|
在demo里面的 WxPayPubHelper.php 里面 用 $this->log_d(xxx);调用。
刚开始的时候由于给我的mchid和 appid不匹配一直报错。。是他们给错我账号了。刚开始我也不懂乱试。这一步的调试在 getPrepayId()内 var_dump($this->result); 就能看到错误代码。
第三步:生成支付前端 js代码就绪到网页上:
| 代码如下 | 复制代码 |
| $jsApi->setPrepayId($prepay_id); $jsApiParameters = $jsApi->getParameters(); ———————-点击前往支付————————- |
|
这部分又遇到了问题:
android返回“System:Access_denied”,ios返回”access_control:not_allowed”
搜了很多百度。其实早就看到了这个东西一直没注意!
发起授权请求的页面必须是在授权目录下的页面,而不能是存在与子目录中。否则会返回错误
支付文件我放在了/域名/pay/demo/
刚开始的时候我一直是到/域名/pay/结尾以为就可以了。支持子目录,结果是不行的!。
—————————最后看下图—————
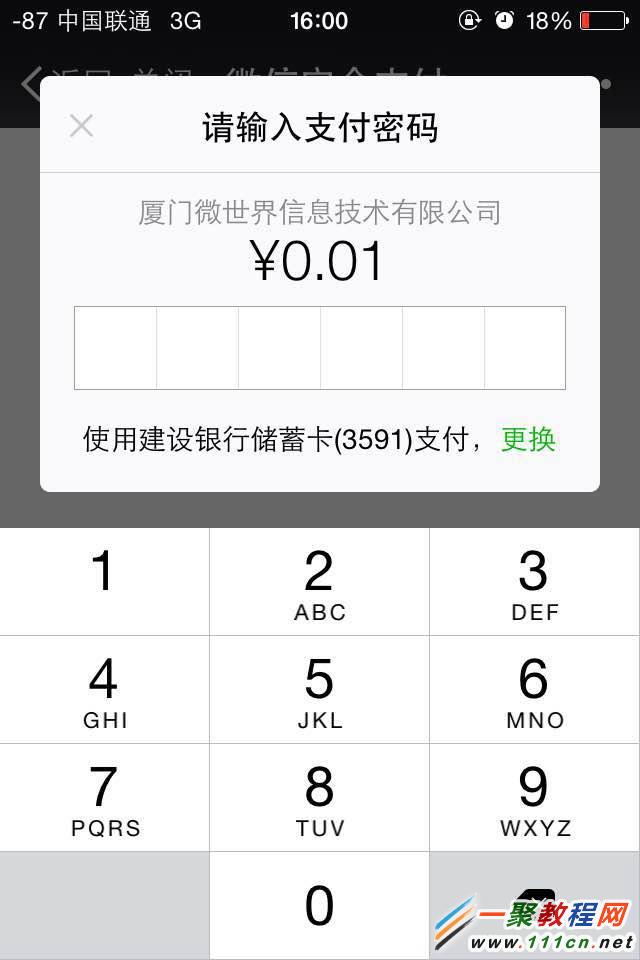
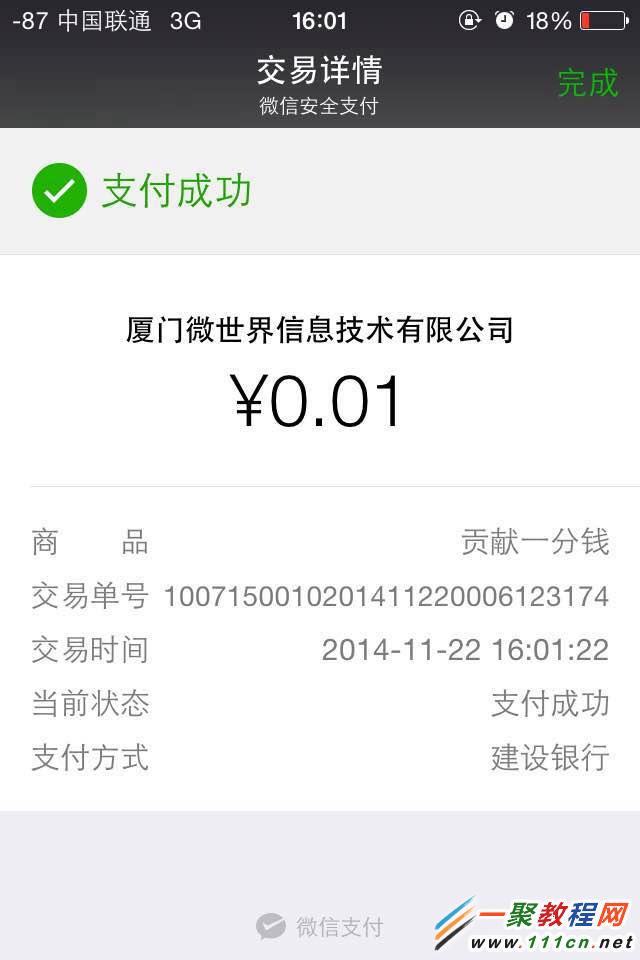

—————–流程中的xmljs——————–
待提交生成与支付订单id:
| 代码如下 | 复制代码 |
| <xml> <openid><![CDATA[ou9dHt0L8qFLI1foP-kj5x1mDWsM]]></openid> <body><![CDATA[贡献一下]]></body> <out_trade_no><![CDATA[wx88888888888888881414411779]]></out_trade_no> <total_fee>1</total_fee> <notify_url><![CDATA[http://shanmao.me/wxpay/notify_url.php]]></notify_url> <trade_type><![CDATA[JSAPI]]></trade_type> <appid><![CDATA[wx8888888888888888]]></appid> <mch_id>10012345</mch_id> <spbill_create_ip><![CDATA[61.50.221.43]]></spbill_create_ip> <nonce_str><![CDATA[60uf9sh6nmppr9azveb2bn7arhy79izk]]></nonce_str> <sign><![CDATA[2D8A96553672D56BB2908CE4B0A23D0F]]></sign> </xml> 提交后返回正确,其中包含了perpay_id: <xml> <return_code><![CDATA[SUCCESS]]></return_code> <return_msg><![CDATA[OK]]></return_msg> <appid><![CDATA[wx8888888888888888]]></appid> <mch_id><![CDATA[10012345]]></mch_id> <nonce_str><![CDATA[Be8YX7gjCdtCT7cr]]></nonce_str> <sign><![CDATA[885B6D84635AE6C020EF753A00C8EEDB]]></sign> <result_code><![CDATA[SUCCESS]]></result_code> <prepay_id><![CDATA[wx201410272009395522657a690389285100]]></prepay_id> <trade_type><![CDATA[JSAPI]]></trade_type> </xml> 生成支付用的js : { "appId": "wx8888888888888888", "timeStamp": "1414411784", "nonceStr": "gbwr71b5no6q6ne18c8up1u7l7he2y75", "package": "prepay_id=wx201410272009395522657a690389285100", "signType": "MD5", "paySign": "9C6747193720F851EB876299D59F6C7D" } 支付成功后返回的通知xml: <xml><appid><![CDATA[wx8888888888]]></appid> <bank_type><![CDATA[CCB_DEBIT]]></bank_type> <fee_type><![CDATA[CNY]]></fee_type> <is_subscribe><![CDATA[Y]]></is_subscribe> <mch_id><![CDATA[1011111]]></mch_id> <nonce_str><![CDATA[38gt0ffgsvfsdfsdfbt1981duv63p7]]></nonce_str> <openid><![CDATA[o4p3SjfdsfdsfdsdCE5Y2XHw4]]></openid> <out_trade_no><![CDATA[wx4b56d1fsdfdsf416643247]]></out_trade_no> <result_code><![CDATA[SUCCESS]]></result_code> <return_code><![CDATA[SUCCESS]]></return_code> <sign><![CDATA[356EfsdfdsfsdsfE69509EDA344]]></sign> <sub_mch_id><![CDATA[10018826]]></sub_mch_id> <time_end><![CDATA[20141122160122]]></time_end> <total_fee>1</total_fee> <trade_type><![CDATA[JSAPI]]></trade_type> <transaction_id><![CDATA[100715001020fsdfsd1220006123174]]></transaction_id> </xml> |
|
这其中的数据我随意了的,大家就参考下格式吧。注意大小写敏感。
相关文章
- 下面小编来给大家演示几个php操作zip文件的实例,我们可以读取zip包中指定文件与删除zip包中指定文件,下面来给大这介绍一下。 从zip压缩文件中提取文件 代...2016-11-25
Jupyter Notebook读取csv文件出现的问题及解决
这篇文章主要介绍了JupyterNotebook读取csv文件出现的问题及解决,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2023-01-06- 这篇文章主要介绍了在java中获取List集合中最大的日期时间操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-15
- 这篇文章主要介绍了教你怎么用Java获取国家法定节假日,文中有非常详细的代码示例,对正在学习java的小伙伴们有非常好的帮助,需要的朋友可以参考下...2021-04-23
- 有时我们接受或下载到的PSD文件打开是空白的,那么我们要如何来解决这个 问题了,下面一聚教程小伙伴就为各位介绍Photoshop打开PSD文件空白解决办法。 1、如我们打开...2016-09-14
- C#使用System.IO中的文件操作方法在Windows系统中处理本地文件相当顺手,这里我们还总结了在Oracle中保存文件的方法,嗯,接下来就来看看整理的C#操作本地文件及保存文件到数据库的基本方法总结...2020-06-25
- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- 这篇文章主要介绍了C#实现HTTP下载文件的方法,包括了HTTP通信的创建、本地文件的写入等,非常具有实用价值,需要的朋友可以参考下...2020-06-25
- 这篇文章主要为大家详细介绍了SpringBoot实现excel文件生成和下载,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-09
mysql中获取一天、一周、一月时间数据的各种sql语句写法
创建表:复制代码 代码如下:create table if not exists t( id int, addTime datetime default '0000-00-00 00:00:00′)添加两条初始数据:insert t values(1, '2012-07-12 21:00:00′);insert t values(2, '2012-07...2014-05-31- 这篇文章主要介绍了.NET/C# 使用Stopwatch测量运行时间,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-06-25
php无刷新利用iframe实现页面无刷新上传文件(1/2)
利用form表单的target属性和iframe 一、上传文件的一个php教程方法。 该方法接受一个$file参数,该参数为从客户端获取的$_files变量,返回重新命名后的文件名,如果上传失...2016-11-25- 要替换字符串中的内容我们只要利用php相关函数,如strstr,str_replace,正则表达式了,那么我们要替换目录所有文件的内容就需要先遍历目录再打开文件再利用上面讲的函数替...2016-11-25
- 又码了一个周末的代码,这次在做一些关于文件上传的东西。(PHP UPLOAD)小有收获项目是一个BT种子列表,用户有权限上传自己的种子,然后配合BT TRACK服务器把种子的信息写出来...2016-11-25
- 今天小编在这里就来给photoshop的这一款软件的使用者们来说下AI源文件转photoshop图像变模糊问题的解决教程,各位想知道具体解决方法的使用者们,那么下面就快来跟着小编...2016-09-14
- 这篇文章主要介绍了C++万能库头文件在vs中的安装步骤(图文),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-23
- 步骤:Window -> PHP -> Editor -> Templates,这里可以设置(增、删、改、导入等)管理你的模板。新建文件注释、函数注释、代码块等模板的实例新建模板,分别输入Name、Description、Patterna)文件注释Name: 3cfileDescriptio...2013-10-04
- 本篇文章主要说明的是与php文件上传的相关配置的知识点。PHP文件上传功能配置主要涉及php.ini配置文件中的upload_tmp_dir、upload_max_filesize、post_max_size等选项,下面一一说明。打开php.ini配置文件找到File Upl...2015-10-21
ant design中upload组件上传大文件,显示进度条进度的实例
这篇文章主要介绍了ant design中upload组件上传大文件,显示进度条进度的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-10-29- 这篇文章主要介绍了C#使用StreamWriter写入文件的方法,涉及C#中StreamWriter类操作文件的相关技巧,需要的朋友可以参考下...2020-06-25