检查PHP的exec函数是否执行成功
做一个代码发布的系统,需要用到PHP的exec函数来执行Linux下的命令和git,svn命令,如何判断PHP的exec函数是否执行成功呢?
写个PHP文件来做实验:
exec函数解析
exec语法: string exec(string command, string [array], int [return_var]);
exec返回值: 字符串
Exec参数说明
Command – 需要执行的命令
Array – 是输出值
return_var –是返回值0或1,如果返回0则执行成功,返回1则执行失败。
exec函数第一个参数是执行的命令,第二个参数是执行的结果,第三个参数是执行的状态。
<?php
exec('ls', $log, $status);
print_r($log);
print_r($status);
echo PHP_EOL;
执行这个php文件:
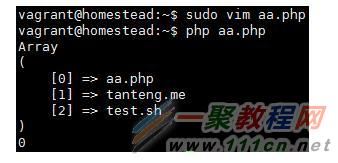
这里$log,$status输出结果如图。
但是$status为0,给人的感觉是执行失败,其实不是,这是exec执行成功。
改一下这个php文件,给exec第一个参数一个错误的命令。
如:exec(‘lsaa’,$log,$status).
再次执行,运行结果如图:
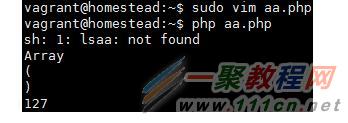
这里$status确是有值的。
那么证明$status为0的时候表示exec执行是成功的。这里PHP官方手册上并没有明确说明。
最终这个执行命令的方法如下:
PHP exec执行命令PHP
public function runLocalCommand($command) {
$command = trim($command);
$status = 1;
$log = '';
exec($command . ' 2>&1', $log, $status);
// 执行过的命令
$this->command = $command;
// 执行的状态
$this->status = !$status;
return $this->status;
}
去除了日志记录和其他的判断。
注意这里:
$this->status = !$status;
返回状态的时候取相反的值!
什么是opcode
也许你曾经尝试过用C/C++编写动态内容,虽然开发过程极其繁琐,但为了获得性能提升,这样做或许是值得的,它们可以将动态内容编译成二进制可执行文件,也就是目标代码,由操作系统进程直接装载运行。如今已经很少有人使用C/C++编写动态内容了,绝大多数的Web开发人员享受着当下的幸福时光,很多优秀的脚本语言可供选择,比如PHP,Ruby,Python,它们都属于解释型语言,所以用它们编写的动态内容都需要依赖响应的解释器程序来运行。
解释器程序也是一个二进制可执行文件,比如/bin/ruby,它同样可以直接在进程中运行,在运行过程中,解释器程序需要对输入的脚本代码进行分析,领会它们的旨意,然后执行它们。比如下面我们调用PHP的解释器,让它执行一段简单的脚本代码:
~ zfs$ php -r 'print 1+1;'
2
很好,它很快的输出了正确的结果,也许你觉的1+1的计算太小儿科,的确,在人类的大脑中计算1+1是很简单,几乎不用思考,但解释器的工作方式可不是你想象的那样,1+1和100+1000对它来说几乎没有什么区别,因为解释器核心引擎根本看不懂这些脚本代码,无法直接执行,所以需要进行一系列的代码分析工作,当解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode)。
从程序代码到中间代码的这个过程,我们称为解释(parse),它由解释器来完成。如此相似的是,编译型语言中的编译器(如C语言的编译器gcc),也要将程序代码生成中间代码,这个过程我们称为编译(compile)。编译器和解释器的一个本质不同在于,解释器在生成中间代码后,便直接执行它,所以运行时的控制权在解释器;而编译器则将中间代码进一步优化,生成可以直接运行的目标程序,但不执行它,用户可以在随后的任意时间执行它,这时的控制权在目标程序,和编译器没有任何关系。
事实上,就解释和编译本身而言,它们的原理是相似的,都包括词法分析,语法分析,语义分析等,所以,有些时候将解释型语言中生成opcode的过程也称为"编译",需要你根据上下文来理解。
那么,opcode究竟是什么样的呢? 它又是如何解释生成的呢? 我们以PHP为例,来寻找这些答案。
PHP解释器的核心引擎为Zend Engine,可以很容易的查看它的版本:
~ zfs$ php -v
PHP 5.5.14 (cli) (built: Sep 9 2014 19:09:25)
Copyright (c) 1997-2014 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2014 Zend Technologies
还记得前面我们曾经用PHP计算1+1的脚本代码吗? 我们来看看这段代码的opcode。在此之前,需要安装PHP的Parsekit扩展,它是一个用C编写的二进制扩展,由PECL来维护。有了Parsekit扩展后,我们就可以通过它提供的运行时API来查看任何PHP文件或者代码段的opcode。我们直接在命令行中调用parsekit_compile_string(),如下所示:
/usr/local/php/bin/php -r "var_dump(parsekit_compile_string('print 1+1;'));"
这样一来,我们便获得了这段代码的opcode,返回的是数组形式,结果如下所示:
array(20) {
["type"]=>
int(4)
["type_name"]=>
string(14) "ZEND_EVAL_CODE"
["fn_flags"]=>
int(0)
["num_args"]=>
int(0)
["required_num_args"]=>
int(0)
["pass_rest_by_reference"]=>
bool(false)
["uses_this"]=>
bool(false)
["line_start"]=>
int(0)
["line_end"]=>
int(0)
["return_reference"]=>
bool(false)
["refcount"]=>
int(1)
["last"]=>
int(5)
["size"]=>
int(5)
["T"]=>
int(2)
["last_brk_cont"]=>
int(0)
["current_brk_cont"]=>
int(4294967295)
["backpatch_count"]=>
int(0)
["done_pass_two"]=>
bool(true)
["filename"]=>
string(17) "Parsekit Compiler"
["opcodes"]=>
array(5) {
[0]=>
array(8) {
["address"]=>
int(33847532)
["opcode"]=>
int(1)
["opcode_name"]=>
string(8) "ZEND_ADD"
["flags"]=>
int(197378)
["result"]=>
array(3) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(0)
}
["op1"]=>
array(3) {
["type"]=>
int(1)
["type_name"]=>
string(8) "IS_CONST"
["constant"]=>
&int(1)
}
["op2"]=>
array(3) {
["type"]=>
int(1)
["type_name"]=>
string(8) "IS_CONST"
["constant"]=>
&int(1)
}
["lineno"]=>
int(1)
}
[1]=>
array(7) {
["address"]=>
int(33847652)
["opcode"]=>
int(41)
["opcode_name"]=>
string(10) "ZEND_PRINT"
["flags"]=>
int(770)
["result"]=>
array(3) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(1)
}
["op1"]=>
array(3) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(0)
}
["lineno"]=>
int(1)
}
[2]=>
array(7) {
["address"]=>
int(33847772)
["opcode"]=>
int(70)
["opcode_name"]=>
string(9) "ZEND_FREE"
["flags"]=>
int(271104)
["op1"]=>
array(4) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(1)
["EA.type"]=>
int(0)
}
["op2"]=>
array(3) {
["type"]=>
int(8)
["type_name"]=>
string(9) "IS_UNUSED"
["opline_num"]=>
string(1) "0"
}
["lineno"]=>
int(1)
}
[3]=>
array(7) {
["address"]=>
int(33847892)
["opcode"]=>
int(62)
["opcode_name"]=>
string(11) "ZEND_RETURN"
["flags"]=>
int(16777984)
["op1"]=>
array(3) {
["type"]=>
int(1)
["type_name"]=>
string(8) "IS_CONST"
["constant"]=>
&NULL
}
["extended_value"]=>
int(0)
["lineno"]=>
int(1)
}
[4]=>
array(5) {
["address"]=>
int(33848012)
["opcode"]=>
int(149)
["opcode_name"]=>
string(21) "ZEND_HANDLE_EXCEPTION"
["flags"]=>
int(0)
["lineno"]=>
int(1)
}
}
}
parsekit扩展的安装请参见这篇文章
系统缓存
它是指APC把PHP文件源码的编译结果缓存起来,然后在每次调用时先对比时间标记。如果未过期,则使用缓存的中间代码运行。默认缓存3600s(一小时)。但是这样仍会浪费大量CPU时间。因此可以在php.ini中设置system缓存为永不过期(apc.ttl=0)。不过如果这样设置,改运php代码后需要重启WEB服务器。目前使用较多的是指此类缓存。
用户数据缓存
缓存由用户在编写PHP代码时用apc_store和apc_fetch函数操作读取、写入的。如果数据量不大的话,可以一试。如果数据量大,使用类似memcache此类的更加专著的内存缓存方案会更好。
APC模块的安装
最简单的方法是直接使用pecl,在命令行下输入:/usr/local/php/bin/pecl install apc
然后按照提示一步步完成即可,示例如下:
[root@iZ23bm1tc0pZ ~]# /usr/local/php/bin/pecl install apc
downloading APC-3.1.13.tgz ...
Starting to download APC-3.1.13.tgz (171,591 bytes)
.....................................done: 171,591 bytes
55 source files, building
running: phpize
Configuring for:
PHP Api Version: 20100412
Zend Module Api No: 20100525
Zend Extension Api No: 220100525
Enable internal debugging in APC [no] : no
Enable per request file info about files used from the APC cache [no] : no
Enable spin locks (EXPERIMENTAL) [no] : no
Enable memory protection (EXPERIMENTAL) [no] : no
Enable pthread mutexes (default) [no] : no
Enable pthread read/write locks (EXPERIMENTAL) [yes] : yes
然后重启服务器即可:
lnmp nginx restart
先看一下没有使用apc情况下的压测结果:
[root@iZ23bm1tc0pZ ~]# ab -n1000 -c100 http://zfsphp.cn/index.php
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking zfsphp.cn (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: nginx
Server Hostname: zfsphp.cn
Server Port: 80
Document Path: /index.php
Document Length: 14341 bytes
Concurrency Level: 100
Time taken for tests: 15.517 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 14544000 bytes
HTML transferred: 14341000 bytes
Requests per second: 64.45 [#/sec] (mean)
Time per request: 1551.671 [ms] (mean)
Time per request: 15.517 [ms] (mean, across all concurrent requests)
Transfer rate: 915.34 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 4.8 0 17
Processing: 46 1481 277.0 1560 1638
Waiting: 42 1481 277.1 1560 1638
Total: 58 1482 272.8 1560 1638
Percentage of the requests served within a certain time (ms)
50% 1560
66% 1576
75% 1582
80% 1587
90% 1602
95% 1612
98% 1622
99% 1629
100% 1638 (longest request)
可见最大吞吐率只有64.45reqs/s
然后我们开启apc,测试结果如下:
[root@iZ23bm1tc0pZ ~]# ab -n1000 -c100 http://zfsphp.cn/index.php
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking zfsphp.cn (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: nginx
Server Hostname: zfsphp.cn
Server Port: 80
Document Path: /index.php
Document Length: 14341 bytes
Concurrency Level: 100
Time taken for tests: 7.122 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 14544000 bytes
HTML transferred: 14341000 bytes
Requests per second: 140.41 [#/sec] (mean)
Time per request: 712.189 [ms] (mean)
Time per request: 7.122 [ms] (mean, across all concurrent requests)
Transfer rate: 1994.29 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 2.4 0 10
Processing: 23 677 125.3 705 775
Waiting: 22 677 125.4 705 775
Total: 30 678 123.1 705 775
Percentage of the requests served within a certain time (ms)
50% 705
66% 719
75% 726
80% 730
90% 742
95% 750
98% 760
99% 765
100% 775 (longest request)
可见吞吐率提高了一倍多,达到140.41reqs/s。
然后,我们在开启动态内容缓存(楼主的博客用的是Smarty缓存),测试结果如下:
[root@iZ23bm1tc0pZ ~]# ab -n1000 -c100 http://zfsphp.cn/index.php
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking zfsphp.cn (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: nginx
Server Hostname: zfsphp.cn
Server Port: 80
Document Path: /index.php
Document Length: 14341 bytes
Concurrency Level: 100
Time taken for tests: 2.263 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 14544000 bytes
HTML transferred: 14341000 bytes
Requests per second: 441.98 [#/sec] (mean)
Time per request: 226.255 [ms] (mean)
Time per request: 2.263 [ms] (mean, across all concurrent requests)
Transfer rate: 6277.49 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 3.1 0 12
Processing: 18 215 38.1 222 255
Waiting: 18 215 38.3 222 255
Total: 26 216 35.6 223 255
Percentage of the requests served within a certain time (ms)
50% 223
66% 230
75% 232
80% 234
90% 237
95% 239
98% 240
99% 243
100% 255 (longest request)
这一次吞吐率居然达到441.98reqs/s,提高了三倍多,相比最初的64.45reqs/s提高了近7倍,可见使用apc的opcode缓存配合Smarty缓存,对网站性能的优化效果还是相当明显的。
演示代码
运行效果(图1)
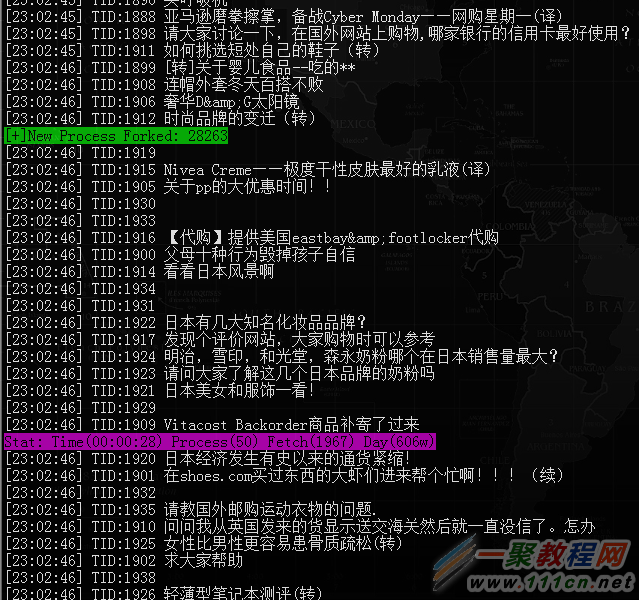
运行效果(图2)
主要封装函数
multi_process();
根据参数,创建指点数目的子进程。
亮点功能1:子进程各种异常退出,比如segment fault, Allowed memory size exhausted等,中断一个子进程后,父进程会重新fork一个新进程顶上去,保持子进程数量。如果子进程里完成任务(比如判断tid达到10000),可以在子进程里exit(9),父进程会收到这个退出状态(9),然后等待所有子进程退出,最后退出自身进程。
亮点功能2:与curl封装函数一起实现了一统计功能,在程序关闭后会显示出一些主要的统计信息(图2的底部)。
mp_counter();
在父进程以及所有子进程之间通信,负责协调分配各子进程的任务,使用了锁机制。可以设置’init’参数重置计数,可以设置每次更新计数的值。
curl_get();
对curl相关函数的封装,加入了大量的错误机制,支持POST,GET,Cookie,Proxy,下载。
mp_msg();
实现规范之一就是,每条任务处理完,只输出一行信息。
亮点功能:这个函数会判断终端的高度和宽度,实现每一屏内容会显示一条统计信息(图1的紫色行),便于观察程序的执行情况,控制每一行输出的长度,保持一条信息不会超过一行。
rand_exit();
众所周知,PHP存在内在泄露的问题,所以每一个子进程里执行一定次数的任务后就退出,由multi_process()负责自动建立新的子进程(如图1中的绿色行)。
程序效率
本次测试使用的是Vultr的最低配置机器,1 CPU(3.6GHz),768MB RAM,美国LA机房(一定程度上影响了抓取速度)。
执行了十多分钟后,统计信息如下:

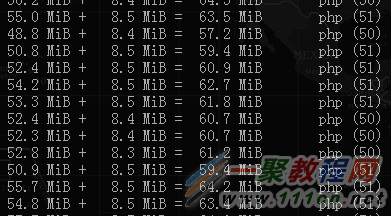
运行期间内存占用统计(while true; do psmem | grep php;sleep 10; done)如下:
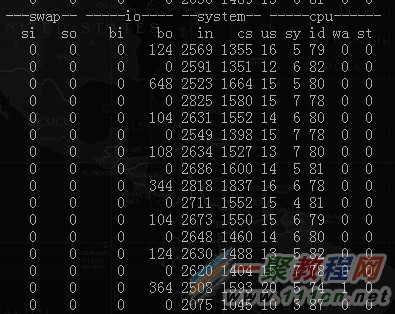
vmstat 1命令结果如下
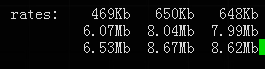
iftop带宽监控如下:
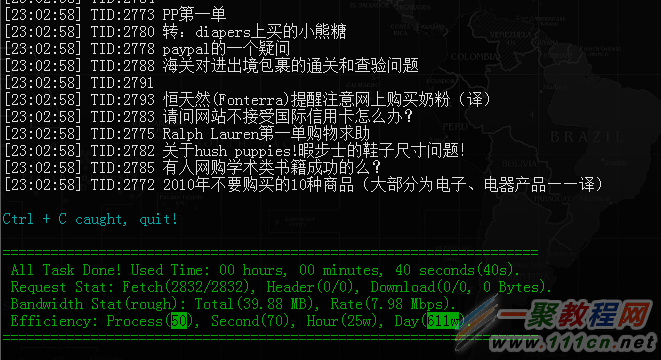
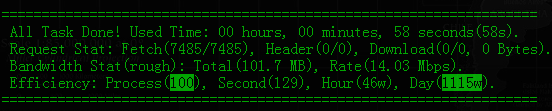
50个子进程,执行11分55秒,抓取50951次,按这个速度计算,一天可以抓取615万次。
所有进程(1父进程+50子进程)共占用内存约60MB,占用CPU约20%(1核心),带宽占用约7-8Mbps。
不同进程数量的抓取速度对比:
1个进程


100个进程
多进程的封装几乎完美,但curl由于它的功能太过于丰富和强大,可能永远也无法达到完美
代码如下
curl.lib.php
| 代码如下 | 复制代码 |
|
<?php // 命令行颜色输出 /* /* /* /* // cookie和临时文件目录 // 清除过期的cookie文件和下载临时文件 /** /** /** if(!$header_text){ // 处理状态码 /** return curl_func($url, $method, $data, $path, $proxy); /**
/** function img_down($url, $path_pre){ function get_img_ext($path){ /** } /** /** /** /** // 控制台输出颜色 // 去除URL中的/../ // 去除实体转码 // 统计数据 for($i = 0; $i < curl_config_get('retry'); $i++){ // 初始化 // 设置超时 // 接收网页内容到变量 // 忽略SSL验证 // 设置referer, 在文件里配置的优先级最高 // 设置HTTP请求标识,在文件里配置的优先级最高 curl_setopt($ch, CURLOPT_USERAGENT, $useragent); // 出口IP // 设置代理 // 设置允许接收gzip压缩数据,以及解压,抓取HEADER时不使用(获取不到正确的文件大小,影响判断下载成功) // 遇到301和302转向自动跳转继续抓取,如果用于WEB程序并且设置了open_basedir,这个选项无效 // 启用cookie // 设置post参数内容 // 设置用于下载的参数 // 仅获取header // 抓取结果 // 调试curl时间,记录连接时间,等待时间,传输时间,总时间。 // 关闭CURL句柄 // 如果CURL有错误信息则判断为抓取失败,重试 // 统计流量 // 对结果进行处理 if(in_array($status_code, array_merge(range(400, 417), array(500, 444)))){ if(empty($savepath)){ // 分析页面编码 // 转码条件:1)匹配到编码, 2)返回编码不为空, 3)匹配到的编码和返回编码不相同 // iconv如果失败则返回空白页 // 统计下载文件量 return TRUE; // 如果是下载或者抓取header,并且错误代码为6(域名无法解析),则不输出错误。失效的图片引用太多了。 // 统计数据 return FALSE; /** // 多并发下建议关闭黄色错误输出 if(php_sapi_name() != 'cli'){ if(!in_array($color, $available_msg)){ echo "{$reverse}".$colors[$color]."({$method})[cURL ERROR: {$msg}] {$url}{$end}\n"; /** /** function relative_to_absolute($content, $url) { preg_match("/(http|https|ftp):\/\/[^\/]*/", $url, $preg_base); preg_match("/(http|https|ftp):\/\/.*\//", $url, $preg_full); return $content; /** $cookie_files = glob("{$cookie_dir}curl_*_pid_*"); foreach($files as $file){
}
function curl_rand_ua_pc(){ function curl_rand_ua_mobile(){ function curl_config_get($key){ if(!empty($curl_config[getmypid()][$key])){ function curl_config_set($key, $val){ function curl_set_ua($ua){ function curl_set_referer($referer){ function curl_set_retry($retry){ function curl_set_conntimeout($conntimeout){ function curl_set_fetchtimeout($fetchtimeout){ function curl_set_downtimeout($downtimeout){ | |
process.lib.php
| 代码如下 | 复制代码 |
|
<?php declare(ticks = 1); // 中断信号 // 命令行颜色输出 // 程序开始运行时间 // 父进程PID // 文件保存目录,/dev/shm/是内存空间映射到硬盘上,IO速度快。 // 清理过期资源(文件和SEM信号锁),每次程序执行都需要调用,清除掉之前执行时的残留文件。 // 判断是否在子进程中 /** // 父进程PID或者自身PID // 系统启动时间 // 进程启动时间 // 由父进程ID确定变量文件路径前缀 // 由于系统启动时间和当前父进程启动时间(jiffies格式)确定计数使用的文件 // 更新计数,先锁定 if(!file_exists($cur_path)){ $counter = 0; // 更新记数, 继续研究下判断init不能用== // 写入计数,解锁 return $new_counter; /** if(empty($num)){ // 记录进程数量,统计用 // 子进程数量 // 任务完成标识 while(TRUE) { // 清空子进程退出状态 // 如果任务未完成,并且子进程数量没有达到最高,则创建 // 注册父进程的信号处理函数 //$stat && pcntl_signal(SIGINT, "signal_handler"); echo "{$reverse}{$green}[+]New Process Forked: {$pid}{$end}\n"; // 1,注册一个信号,处理函数直接exit(),目的是让子进程不进行任何处理,仅由主进程处理这个信号 // 注册信号后直接返回,继续处理主程序的后续部分。 // 子进程管理部分 // 统计信息 // 子进程退出状态码为9时,则判断为所有任务完成,然后等待所有子进程退出
if(strpos($script, '/') === FALSE || strpos($script, '..') !== FALSE){ return $path; function final_stat(){ // 时间统计 // curl抓取统计 $down_total = mp_counter('down_total', 0); $header_total = mp_counter('header_total', 0); $download_size = hs(mp_counter('download_size', 0)); echo " Request Stat: Fetch({$fetch_success}/{$fetch_total}), Header({$header_success}/{$header_total}), "; // curl流量统计 // 效率统计 echo "========================================================================{$end}\n"; /** function sub_process_exit(){ function hnum($num){ /**
/** if(!function_exists('get_ppid')){ // 以进程(多进程运行时,使用父进程)为单位,每个进程使用一个锁。 // 解除锁 // 清理资源(文件和SEM信号锁) // 清除sem的文件和信号量 // 清除mp_counter的文件(仅此类型文件不可重用,所以严格处理,匹配系统启动时间和进程启动时间) // 清除文件 // 系统启动时间 // 如果是在子进程中调用,则取父进程的启动时间。如果不是在子进程中调用,则取自身启动时间。时间都是jiffies格式。 // 防止PHP进程内存泄露,每个子进程执行完一定数量的任务就退出。 // 单次的任务结果输出函数 // 整理统计信息 // cron方式运行 $lock = sem_lock('mp_msg'); $t_cols = mp_counter('t_cols', 0); if($t_lines <= 1){ $process_num = mp_counter('process_num', 0); $fetch_total = mp_counter('fetch_total', 0); echo "{$reverse}{$purple}"; } | |
我习惯设置的日志路径是这样
/home/www/logs/域名.log
比如
/home/www/logs/www.yundaiwei.com.log
为了方便管理,日志需要按天保存在一个文件中,并且保留指定天数的日志,超过时间的就删除。
分享一下脚本
#!/usr/bin/php
<?php
$logdir = '/home/www/logs/';
// 保留天数含当天
$log_save_day = 7;
$files = glob("{$logdir}/*");
foreach($files as $path){
$filename = basename($path);
preg_match("/(\d{8})\.log/", $filename, $preg);
$date = @$preg[1];
if(empty($date)){
// 当天日志,更改文件名
$newpath = $logdir . '/' . str_replace('log', date('Ymd',strtotime("-1 day")).'.log', $filename);
rename($path, $newpath);
echo "$path >>> $newpath\n";
}else{
// 超过保留天数,删除
if(time()+10 - strtotime($date) > 3600*24*$log_save_day){
unlink($path);
echo "$path delete!\n";
}
}
}
shell_exec('/etc/init.d/nginx reload &> /dev/null');
相关文章
- eval函数在php中是一个函数并不是系统组件函数,我们在php.ini中的disable_functions是无法禁止它的,因这他不是一个php_function哦。 eval()针对php安全来说具有很...2016-11-25
- 在php中eval是一个函数并且不能直接禁用了,但eval函数又相当的危险了经常会出现一些问题了,今天我们就一起来看看eval函数对数组的操作 例子, <?php $data="array...2016-11-25
Python astype(np.float)函数使用方法解析
这篇文章主要介绍了Python astype(np.float)函数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-06-08- 这篇文章主要介绍了Python中的imread()函数用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-16
- 本文主要介绍了C# 中取绝对值的函数。具有很好的参考价值。下面跟着小编一起来看下吧...2020-06-25
- 下面小编就为大家带来一篇C#学习笔记- 随机函数Random()的用法详解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2020-06-25
- 引发这个问题思考的是一段js程序的运行结果: 复制代码 代码如下: var i = 0; function a(){ for(i=0;i<20;i++){ } } function b(){ for(i=0;i<3;i++){ a(); } return i; } var Result = b(); 这段程序的运行结果是Re...2014-05-31
- CREATE FUNCTION ChangeBigSmall (@ChangeMoney money) RETURNS VarChar(100) AS BEGIN Declare @String1 char(20) Declare @String2 char...2016-11-25
- 这篇文章主要介绍了C++中Sort函数详细解析,sort函数是algorithm库下的一个函数,sort函数是不稳定的,即大小相同的元素在排序后相对顺序可能发生改变...2022-08-18
Android开发中findViewById()函数用法与简化
findViewById方法在android开发中是获取页面控件的值了,有没有发现我们一个页面控件多了会反复研究写findViewById呢,下面我们一起来看它的简化方法。 Android中Fin...2016-09-20- strstr() 函数搜索一个字符串在另一个字符串中的第一次出现。该函数返回字符串的其余部分(从匹配点)。如果未找到所搜索的字符串,则返回 false。语法:strstr(string,search)参数string,必需。规定被搜索的字符串。 参数sea...2013-10-04
PHP函数分享之curl方式取得数据、模拟登陆、POST数据
废话不多说直接上代码复制代码 代码如下:/********************** curl 系列 ***********************///直接通过curl方式取得数据(包含POST、HEADER等)/* * $url: 如果非数组,则为http;如是数组,则为https * $header:...2014-06-07- Foreach 函数(PHP4/PHP5)foreach 语法结构提供了遍历数组的简单方式。foreach 仅能够应用于数组和对象,如果尝试应用于其他数据类型的变量,或者未初始化的变量将发出错误信息。...2013-09-28
- free函数是释放之前某一次malloc函数申请的空间,而且只是释放空间,并不改变指针的值。下面我们就来详细探讨下...2020-04-25
- PHP 函数 strip_tags 提供了从字符串中去除 HTML 和 PHP 标记的功能,该函数尝试返回给定的字符串 str 去除空字符、HTML 和 PHP 标记后的结果。由于 strip_tags() 无法实际验证 HTML,不完整或者破损标签将导致更多的数...2014-05-31
- v-for标签可以用来遍历数组,将数组的每一个值绑定到相应的视图元素中去,下面这篇文章主要给大家介绍了关于在Vue.js中轻松解决v-for执行出错的三个方案,文中通过示例代码介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。...2017-06-15
Java使用ScriptEngine动态执行代码(附Java几种动态执行代码比较)
这篇文章主要介绍了Java使用ScriptEngine动态执行代码,并且分享Java几种动态执行代码比较,需要的朋友可以参考下...2021-04-15SQL Server中row_number函数的常见用法示例详解
这篇文章主要给大家介绍了关于SQL Server中row_number函数的常见用法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-12-08- 分享一个PHP加密解密的函数,此函数实现了对部分变量值的加密的功能。 加密代码如下: /* *功能:对字符串进行加密处理 *参数一:需要加密的内容 *参数二:密钥 */ function passport_encrypt($str,$key){ //加密函数 srand(...2015-10-30
php的mail函数发送UTF-8编码中文邮件时标题乱码的解决办法
最近遇到一个问题,就是在使用php的mail函数发送utf-8编码的中文邮件时标题出现乱码现象,而邮件正文却是正确的。最初以为是页面编码的问题,发现页面编码utf-8没有问题啊,找了半天原因,最后找到了问题所在。 1.使用 PEAR 的...2015-10-21