删除uft-8文件bom头信息的方法
如果您在修改任何PHP文件发生:
* 不能登入或者不能登出; * 页顶出现一条空白; * 页顶出现错误警告; * 其它不正常的情况。
bom文件是怎么产生呢?
window编辑器如果保存为utf8文件就会帮你加上BOM头,以告诉其他编辑器以utf8来显示字符
但是在网页上并不需要添加BOM头识别,因为网页上可以使用 head头 指定charset=utf8告诉浏览器用utf8来解释.但是你用window自动的编辑器,编辑,然后有显示在网页上这样就会显示出0xEF 0xBB 0xBF这3个字符。
这样网页上就需要去除0xEF 0xBB 0xBF,可以使用editplus 选择不带BOM的编码,这样就可以去除了
bom文件头信息删除
我最常用的方法来处理php文件处理
| 代码如下 | 复制代码 |
|
<?php checkdir($basedir,$loop); |
|
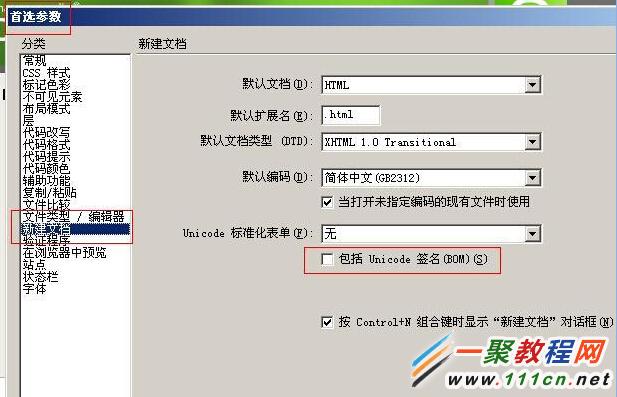
利用Dreamweaver 中去除bom方法
打开Dreamweaver->选择编辑->首选参数->新建文档标签->右边->"包括Unicode 签名(BOM)" 前面的对钩去掉即可
editplus等编程工具时UTF-8编码去掉BOM头方法
编辑器调整为UTF8编码格式后,保存的文件前面会多出一串隐藏的字符(也即是BOM),用于编辑器识别这个文件是否是以UTF8编码。一般的文本文件会忽略这一串隐藏的字符,但对于PHP等文件会解析这一串字符,这样会导致出错。
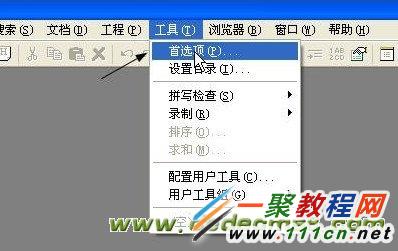
运行Editplus,点击工具,选择首选项,如下图:
选中文件,UTF-8标识选择 总是删除签名,如下图:
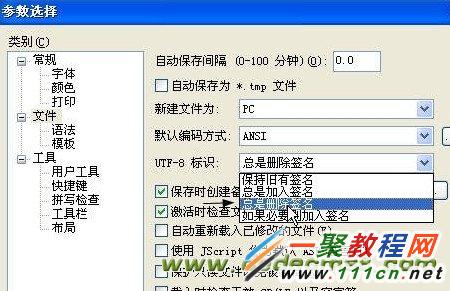
然后对PHP文件编辑和保存后的PHP文件就是不带BOM的了
linux下查找包含BOM头的文件和清除BOM头命令
查找包含BOM头的文件,命令如下:
grep -r -I -l $'^\xEF\xBB\xBF' ./
这条命令会查找当前目录及子目录下所有包含BOM头的文件,并把文件名在屏幕上输出。
但是,删除BOM头,网上找到的命令大多不能用,比较常见的命令是:
grep -r -I -l $'^\xEF\xBB\xBF' /path | xargs sed -i 's/^\xEF\xBB\xBF//;q'
但这条命令会把除了首行之外所有的行删除,所以毫无意义。
经测试如下命令是可行的:
find . -type f -exec sed -i 's/\xEF\xBB\xBF//' {} \;
这个命令会把当前目录及所有子目录下的BOM头删除掉。
HTML条件注释判断浏览器版本命令总结,这里总结了各种注释判断浏览器版本的一些命令与方法,希望例子对各位朋友会带来帮助。
| 项目 | 范例 | 说明 |
| ! | [if !IE] | NOT运算符。这是摆立即在前面的功能,操作员,或子表达式扭转布尔表达式的意义。 |
| lt | [if lt IE 5.5] | 小于运算符。如果第一个参数小于第二个参数,则返回true。 |
| lte | [if lte IE 6] | 小于或等于运算。如果第一个参数是小于或等于第二个参数,则返回true。 |
| gt | [if gt IE 5] | 大于运算符。如果第一个参数大于第二个参数,则返回true。 |
| gte | [if gte IE 7] | 大于或等于运算。如果第一个参数是大于或等于第二个参数,则返回true。 |
| ( ) | [if !(IE 7)] | 子表达式运营商。在与布尔运算符用于创建更复杂的表达式。 |
| & | [if (gt IE 5)&(lt IE 7)] | AND运算符。如果所有的子表达式计算结果为true,返回true。 |
| | | [if (IE 6)|(IE 7)] | OR运算符。返回true,如果子表达式计算结果为true。 |
实用示例:
<!--[if !IE]><!--> 除IE外都可识别 <!--<![endif]-->
<!--[if IE]> 所有的IE可识别 <![endif]-->
<!--[if IE 6]> 仅IE6可识别 <![endif]-->
<!--[if lt IE 6]> IE6以及IE6以下版本可识别 <![endif]-->
<!--[if gte IE 6]> IE6以及IE6以上版本可识别 <![endif]-->
<!--[if IE 7]> 仅IE7可识别 <![endif]-->
<!--[if lt IE 7]> IE7以及IE7以下版本可识别 <![endif]-->
<!--[if gte IE 7]> IE7以及IE7以上版本可识别 <![endif]-->
<!--[if IE 8]> 仅IE8可识别 <![endif]-->
<!--[if IE 9]> 仅IE9可识别 <![endif]-->
扩展知识:
<!--[if lt IE 9]>
加载CSS1
<!--[else]>
加载CSS2
<![endif]-->
注:这样有效是有效,但是用HTML VALIDATOR里,报错,因为这个不符合XHTML 1.1的规范,
如果把ELSE语句去掉,则正确.
上述问题解决方案一:
加载CSS2
<!--[if lt IE 9]>
加载CSS1(可以把要重写的写在这里).
<![endif]-->
问题是门户系统一直使用的是相对路径,首页做了rewrite,而首页的很多链接(包括css、js、图片等)都是相对路径,问了门户系统那边的没法解决,只能用相对路径。
杯具来了,href="news/2014/05/25/1234.html"类似这样的链接都成了http://www.111cn.net /news/2014/05/25/1234.html的全路径,而这个路径在nginx中是没法识别成门户系统的(nginx是通过/portal来匹配的)。
这是因为:HTML文档所有链接中的相对路径,浏览器都会提取当前文档的URL来填充。
突然想起了HTML的base标签,来看W3C的解释:
<base> 标签为页面上的所有链接规定默认地址或默认目标。
通常情况下,浏览器会从当前文档的 URL 中提取相应的元素来填写相对 URL 中的空白。
使用 <base> 标签可以改变这一点。浏览器随后将不再使用当前文档的 URL,而使用指定的基本 URL 来解析所有的相对 URL。这其中包括 <a>、<img>、<link>、<form> 标签中的 URL。
注释:<base> 标签必须位于 head 元素内部。
`(*∩_∩*)′尝试一下,在head标签中加入base标签
?
实例
| 代码如下 | 复制代码 |
|
<head> <body> |
|
问题果然解决!
注:文中使用的域名和路径非真实场景中的域名和路径。
一个BUG
base标签最好不要动态写入,否则在Firefox和IE中会有一个小bug,比如对于页面http://localhost/static/test.html:
| 代码如下 | 复制代码 |
| <html> <head> <script> document.write('<base href="http://localhost/" />'); </script> </head></p> <p><body> <img src="static/1.jpg" /> </body> </html> |
|
Firefox和IE中会先加载http://localhost/static/static/1.jpg,然后再加载http://localhost/static/1.jpg。也就是说,他们都先尝试用相对于当前页面的路径进行加载,然后再通过base标签设置的默认路径加载。
习惯了Emmet这样的工具,我们几乎没怎么写过html文档头部标签了,今天这篇文章其实就是总结了一下当下各个设备的头部标签的写法。
基本标签
使用 HTML5 doctype,不区分大小写。
<!DOCTYPE html> <!-- 使用 HTML5 doctype,不区分大小写 -->
声明文档使用的字符编码
<meta charset='utf-8'> <!-- 声明文档使用的字符编码 -->
更加标准的 lang 属性写法 http://zhi.hu/XyIa
简体中文
<html lang="zh-cmn-Hans"> <!-- 更加标准的 lang 属性写法 http://zhi.hu/XyIa -->
繁体中文
<html lang="zh-cmn-Hant"> <!-- 更加标准的 lang 属性写法 http://zhi.hu/XyIa -->
很少情况才需要加地区代码,通常是为了强调不同地区汉语使用差异,例如:
<p lang="zh-cmn-Hans">
<strong lang="zh-cmn-Hans-CN">菠萝</strong>和<strong lang="zh-cmn-Hant-TW">?梨</strong>其实是同一种水果。只是大陆和台湾称谓不同,且新加坡、马来西亚一带的称谓也是不同的,称之为<strong lang="zh-cmn-Hans-SG">黄梨</strong>。
</p>
优先使用 IE 最新版本和 Chrome
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" /> <!-- 优先使用 IE 最新版本和 Chrome -->
SEO 优化
页面描述
每个网页都应有一个不超过 150 个字符且能准确反映网页内容的描述标签。文档
<meta name="description" content="不超过150个字符" /> <!-- 页面描述 -->
页面关键词
<meta name="keywords" content=""/> <!-- 页面关键词 -->
定义页面标题
<title>标题</title>
定义网页作者
<meta name="author" content="name, email@gmail.com" /> <!-- 网页作者 -->
定义网页seo/seo.html" target="_blank">搜索引擎索引方式,robotterms是一组使用英文逗号「,」分割的值,通常有如下几种取值:none,noindex,nofollow,all,index和follow。文档
<meta name="robots" content="index,follow" /> <!-- 搜索引擎抓取 -->
可选标签
为移动设备添加 viewport
<meta name ="viewport" content ="initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no"> <!-- `width=device-width` 会导致 iPhone 5 添加到主屏后以 WebApp 全屏模式打开页面时出现黑边 http://bigc.at/ios-webapp-viewport-meta.orz -->
width=device-width 会导致 iPhone 5 添加到主屏后以 WebApp 全屏模式打开页面时出现黑边http://bigc.at/ios-webapp-viewport-meta.orz
content 参数:
width viewport 宽度(数值/device-width)
height viewport 高度(数值/device-height)
initial-scale 初始缩放比例
maximum-scale 最大缩放比例
minimum-scale 最小缩放比例
user-scalable 是否允许用户缩放(yes/no)
minimal-ui iOS 7.1 beta 2 中新增属性,可以在页面加载时最小化上下状态栏。这是一个布尔值,可以直接这样写:<meta name="viewport" content="width=device-width, initial-scale=1, minimal-ui">
iOS 设备
添加到主屏后的标题(iOS 6 新增)
<meta name="apple-mobile-web-app-title" content="标题"> <!-- 添加到主屏后的标题(iOS 6 新增) -->
是否启用 WebApp 全屏模式
<meta name="apple-mobile-web-app-capable" content="yes" /> <!-- 是否启用 WebApp 全屏模式 -->
设置状态栏的背景颜色
<meta name="apple-mobile-web-app-status-bar-style" content="black-translucent" /> <!-- 设置状态栏的背景颜色,只有在 `"apple-mobile-web-app-capable" content="yes"` 时生效 -->
只有在 "apple-mobile-web-app-capable" content="yes" 时生效
content 参数:
default 默认值。
black 状态栏背景是黑色。
black-translucent 状态栏背景是黑色半透明。
如果设置为 default 或 black ,网页内容从状态栏底部开始。
如果设置为 black-translucent ,网页内容充满整个屏幕,顶部会被状态栏遮挡。
禁止数字识自动别为电话号码
<meta name="format-detection" content="telephone=no" /> <!-- 禁止数字识自动别为电话号码 -->
iOS 图标
rel 参数:
apple-touch-icon 图片自动处理成圆角和高光等效果。
apple-touch-icon-precomposed 禁止系统自动添加效果,直接显示设计原图。
iPhone 和 iTouch,默认 57×57 像素,必须有
<link rel="apple-touch-icon-precomposed" href="/apple-touch-icon-57x57-precomposed.png" /> <!-- iPhone 和 iTouch,默认 57x57 像素,必须有 -->
iPad,72×72 像素,可以没有,但推荐有
<link rel="apple-touch-icon-precomposed" sizes="72x72" href="/apple-touch-icon-72x72-precomposed.png" /> <!-- iPad,72x72 像素,可以没有,但推荐有 -->
Retina iPhone 和 Retina iTouch,114×114 像素,可以没有,但推荐有
<link rel="apple-touch-icon-precomposed" sizes="114x114" href="/apple-touch-icon-114x114-precomposed.png" /> <!-- Retina iPhone 和 Retina iTouch,114x114 像素,可以没有,但推荐有 -->
Retina iPad,144×144 像素,可以没有,但推荐有
<link rel="apple-touch-icon-precomposed" sizes="144x144" href="/apple-touch-icon-144x144-precomposed.png" /> <!-- Retina iPad,144x144 像素,可以没有,但推荐有 -->
iOS 启动画面
官方文档:https://developer.apple.com/library/ios/qa/qa1686/_index.html
参考文章:http://wxd.ctrip.com/blog/2013/09/ios7-hig-24/
iPad 的启动画面是不包括状态栏区域的。
iPad 竖屏 768 x 1004(标准分辨率)
<link rel="apple-touch-startup-image" sizes="768x1004" href="/splash-screen-768x1004.png" /> <!-- iPad 竖屏 768 x 1004(标准分辨率) -->
iPad 竖屏 1536×2008(Retina)
<link rel="apple-touch-startup-image" sizes="1536x2008" href="/splash-screen-1536x2008.png" /> <!-- iPad 竖屏 1536x2008(Retina) -->
iPad 横屏 1024×748(标准分辨率)
<link rel="apple-touch-startup-image" sizes="1024x748" href="/Default-Portrait-1024x748.png" /> <!-- iPad 横屏 1024x748(标准分辨率) -->
iPad 横屏 2048×1496(Retina)
<link rel="apple-touch-startup-image" sizes="2048x1496" href="/splash-screen-2048x1496.png" /> <!-- iPad 横屏 2048x1496(Retina) -->
iPhone 和 iPod touch 的启动画面是包含状态栏区域的。
iPhone/iPod Touch 竖屏 320×480 (标准分辨率)
<link rel="apple-touch-startup-image" href="/splash-screen-320x480.png" /> <!-- iPhone/iPod Touch 竖屏 320x480 (标准分辨率) -->
iPhone/iPod Touch 竖屏 640×960 (Retina)
<link rel="apple-touch-startup-image" sizes="640x960" href="/splash-screen-640x960.png" /> <!-- iPhone/iPod Touch 竖屏 640x960 (Retina) -->
iPhone 5/iPod Touch 5 竖屏 640×1136 (Retina)
<link rel="apple-touch-startup-image" sizes="640x1136" href="/splash-screen-640x1136.png" /> <!-- iPhone 5/iPod Touch 5 竖屏 640x1136 (Retina) -->
添加智能 App 广告条 Smart App Banner(iOS 6+ Safari)文档
<meta name="apple-itunes-app" content="app-id=myAppStoreID, affiliate-data=myAffiliateData, app-argument=myURL"> <!-- 添加智能 App 广告条 Smart App Banner(iOS 6+ Safari) -->
Windows 8
Windows 8 磁贴颜色
<meta name="msapplication-TileColor" content="#000"/> <!-- Windows 8 磁贴颜色 -->
Windows 8 磁贴图标
<meta name="msapplication-TileImage" content="icon.png"/> <!-- Windows 8 磁贴图标 -->
其他
添加 RSS 订阅
<link rel="alternate" type="application/rss+xml" title="RSS" href="/rss.xml" /> <!-- 添加 RSS 订阅 -->
添加 favicon icon
<link rel="shortcut icon" type="image/ico" href="/favicon.ico" /> <!-- 添加 favicon icon -->
更多
字典匹配
最简单的分词就是基于字典匹配,一个句子“浅谈中文分词”,如果字典中我有这三个词“浅谈”“中文”“分词”那么我自然就可以把句子进行分词了。基于字典匹配随之而来的问题就是有多个匹配的情况,比如有“北京”“北京大学”两个词,这时来了个句子“北京大学在哪里”,应该用“北京”去匹配还是用“北京大学”去匹配,于是人们提出了很多启发式的匹配方案,比如最经典的最大匹配,就是尽可能的匹配最长的词,还有类似分词后分出的词的个数尽量少等启发规则,于是有了mmseg算法,提出了一些比较好的启发规则,而且实际应用时效果也很不错,所以应用很广泛,具体细节大家自行搜索,这里不在赘述。
统计模型
很快基于字典的分词还是会暴露出很多的问题,最主要的问题就是歧义的问题,比如“武汉市长江大桥”,不同的分词可能会变成“武汉/市长/江大桥”和“武汉市/长江/大桥”,显然字典匹配是不能解决这样的歧义问题的,于是有了统计的分词算法。在我的这篇文章里介绍的就是一元模型的分词算法,对于一个句子序列a1a2a3...an变成最后的词序列A1A2A3...Am,一元模型是希望
argmaxΠmi=1P(Ai)
同样的n元模型即是
argmaxΠP(Ai|Ai−1,Ai−2...,Ai−n+1)
我的这篇文章是一元模型的求法,于是统计模型的诞生有些的解决了分词问题中的歧义问题。
隐马尔可夫模型HMM(Hidden Markov Model)
前面的n元模型能够解决歧义的问题,但是,却不能很好解决未登录词的问题,所谓未登录词,是指没有见过的词,或者说没有在我们字典中的词于是后来人们提出了基于字标注的分词,比如这样一句话“我喜欢天安门”就可以变成这样的标注“我s喜b欢e天b安m门e”通过s(single)b(begin)m(middle)e(end)这样的标注把分词问题转变为标注问题,当第一次提出字标注算法时,在分词大会上也是取得了惊人的准确率。
HMM隐藏马尔可夫链模型就是这样一个字标注的分词算法,假设原来的句子序列是a1a2a3...an,标注序列是c1c2...cn,那么HMM是要求这样的式子
argmaxΠP(ci|ci−1)∗P(ai|ci)
在我的SnowNLP这个项目里有去实现HMM的分词。
最大熵模型ME(Maximum Entropy)
我的这篇文章介绍了信息熵的概念,信息熵越大不确定性也就越大,信息熵最大时表示各种概率的均等分布,也就是个不偏不倚的猜测,最大熵模型一般就是在已知条件下,来求是的熵最大的情况,最大熵模型我们一般会有feature函数,给定的条件就是样本期望等于模型期望,即
p−(f)=Σp−(ai,ci)∗f(ai,ci)=p(f)=Σp(ci|ai)∗p−(ai)∗f(ai,ci)
在已知条件下就是求熵最大的情况
argmaxH(ci|ai)
H就是信息熵的函数,于是这样我们就求出了P(ci|ai),就知道了每个字a的标注c了,最大熵模型的一个好处是我们可以引入各种各样的feature,而不仅仅是从字出现的频率去分词,比如我们可以加入domain knowledge,可以加入已知的字典信息等。
最大熵马尔可夫模型MEMM(Maximum-entropy Markov model)
最大熵模型的一个问题就是把每个字的标注问题分裂来看了,于是就有聪明人把马尔可夫链和最大熵结合,搞出了最大熵马尔可夫模型,这样不仅可以利用最大熵的各种feature的特性,而且加入了序列化的信息,使得能够从整个序列最大化的角度来处理,而不是单独的处理每个字,于是MEMM是求这样的形式
argmaxΠP(ci|ci−1,ai)
条件随机场CRF(Conditional Random Field)
MEMM的不足之处就是马尔可夫链的不足之处,马尔可夫链的假设是每个状态只与他前面的状态有关,这样的假设显然是有偏差的,所以就有了CRF模型,使得每个状态不止与他前面的状态有关,还与他后面的状态有关,从最开始的图片也能看出,HMM是基于贝叶斯网络的有向图,而CRF是无向图。
P(Yv|Yw,w≠v)=P(Yv,Yw,w∼v) where w~v means that w and v are neighbors in G.
上式是条件随机场的定义,一个图被称为条件随机场,是说图中的结点只和他相邻的结点有关。最后由于不是贝叶斯网络的有向图,所以CRF利用团的概念来求,最后公式如下
P(y|x,λ)=1Z(x)∗exp(Σλj∗Fj(y,x))
因为条件随机场既可以像最大熵模型那样加各种feature,又没有马尔可夫链那样的偏执假设, 所以近年来CRF已知是被公认的最好的分词算法StanfordNLP里就有良好的中文分词的CRF实现,在他们的这篇论文提到,他们把字典作为feature加入到CRF中,可以很好的提高分词的performance。
最近看到这篇论文,已经有人用deep learning的方法来尝试解决分词的算法,也取得了不错的效果。
总之现在的中文分词技术相对来说还是比较成熟了,所以如果没有必要用这些开源的分词实现已经足够了,不过鉴于学习的目的,自己去实现一个分词算法还是很有趣的。
相关文章
- 下面小编来给大家演示几个php操作zip文件的实例,我们可以读取zip包中指定文件与删除zip包中指定文件,下面来给大这介绍一下。 从zip压缩文件中提取文件 代...2016-11-25
Jupyter Notebook读取csv文件出现的问题及解决
这篇文章主要介绍了JupyterNotebook读取csv文件出现的问题及解决,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2023-01-06- 有时我们接受或下载到的PSD文件打开是空白的,那么我们要如何来解决这个 问题了,下面一聚教程小伙伴就为各位介绍Photoshop打开PSD文件空白解决办法。 1、如我们打开...2016-09-14
- C#使用System.IO中的文件操作方法在Windows系统中处理本地文件相当顺手,这里我们还总结了在Oracle中保存文件的方法,嗯,接下来就来看看整理的C#操作本地文件及保存文件到数据库的基本方法总结...2020-06-25
- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- 这篇文章主要介绍了C#实现HTTP下载文件的方法,包括了HTTP通信的创建、本地文件的写入等,非常具有实用价值,需要的朋友可以参考下...2020-06-25
- 这篇文章主要为大家详细介绍了SpringBoot实现excel文件生成和下载,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-09
- 复制代码 代码如下: <td> <a href="/member/life/edit_ppt/<?php echo $v->id;?>" class="btn">编辑</a> <a href="javascript:;" onclick="if(confirm('您确定删除这条记录?')){location.href='/member/life/d...2014-06-07
php无刷新利用iframe实现页面无刷新上传文件(1/2)
利用form表单的target属性和iframe 一、上传文件的一个php教程方法。 该方法接受一个$file参数,该参数为从客户端获取的$_files变量,返回重新命名后的文件名,如果上传失...2016-11-25- 要替换字符串中的内容我们只要利用php相关函数,如strstr,str_replace,正则表达式了,那么我们要替换目录所有文件的内容就需要先遍历目录再打开文件再利用上面讲的函数替...2016-11-25
- 又码了一个周末的代码,这次在做一些关于文件上传的东西。(PHP UPLOAD)小有收获项目是一个BT种子列表,用户有权限上传自己的种子,然后配合BT TRACK服务器把种子的信息写出来...2016-11-25
- 今天小编在这里就来给photoshop的这一款软件的使用者们来说下AI源文件转photoshop图像变模糊问题的解决教程,各位想知道具体解决方法的使用者们,那么下面就快来跟着小编...2016-09-14
- 这篇文章主要介绍了C++万能库头文件在vs中的安装步骤(图文),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-23
- 步骤:Window -> PHP -> Editor -> Templates,这里可以设置(增、删、改、导入等)管理你的模板。新建文件注释、函数注释、代码块等模板的实例新建模板,分别输入Name、Description、Patterna)文件注释Name: 3cfileDescriptio...2013-10-04
- 本篇文章主要说明的是与php文件上传的相关配置的知识点。PHP文件上传功能配置主要涉及php.ini配置文件中的upload_tmp_dir、upload_max_filesize、post_max_size等选项,下面一一说明。打开php.ini配置文件找到File Upl...2015-10-21
ant design中upload组件上传大文件,显示进度条进度的实例
这篇文章主要介绍了ant design中upload组件上传大文件,显示进度条进度的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-10-29- 这篇文章主要介绍了C#使用StreamWriter写入文件的方法,涉及C#中StreamWriter类操作文件的相关技巧,需要的朋友可以参考下...2020-06-25
- 举一个案例:复制代码 代码如下:<?phpclass Downfile { function downserver($file_name){$file_path = "./img/".$file_name;//转码,文件名转为gb2312解决中文乱码$file_name = iconv("utf-8","gb2312",$file_name...2014-06-07
- 伪造跨站请求介绍伪造跨站请求比较难以防范,而且危害巨大,攻击者可以通过这种方式恶作剧,发spam信息,删除数据等等。...2013-10-01
- 这篇文章主要介绍了C#路径,文件,目录及IO常见操作,较为详细的分析并汇总了C#关于路径,文件,目录及IO常见操作,具有一定参考借鉴价值,需要的朋友可以参考下...2020-06-25