Java超详细分析讲解哈希表
哈希表概念
- 散列表,又称为哈希表(Hash table),采用散列技术将记录存储在一块连续的存储空间中。
- 在散列表中,我们通过某个函数f,使得存储位置 = f(关键字),这样我们可以不需要比较关键字就可获得需要的记录的存储位置。
- 散列技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,散列主要是面向查找的存储结构。
哈希函数的构造
构造原则:
- 计算简单
散列函数的计算时间不应该超过其他查找技术与关键字比较的时间。
- 散列地址分布均匀
解决冲突最好的办法就是尽量让散列地址均匀地分布在存储空间中。
- 保证存储空间的有效利用,并减少为处理冲突而耗费的时间。
构造方法:
平均数取中法
假设关键字是1234,那么它的平方就是1522756.在抽取中间的3位就是227,用作散列地址。再比如关键字4321,那么它的平方就是18671041,抽中间三位数就是671或710。平方去中法比较适合不知道关键字的分布,而位数又不是很多的情况。
折叠法
折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短一些),然后将这几部分叠加求和,并按散列表表长,取几位作为散列表地址。
比如我们的关键字是9 8 7 6 5 4 3 2 1 0,散列表表长为3位,我们将它分为四组,987|654|321|0,然后将他们叠加求和987+654+321+0=1962,再求后3位得到散列地址为962。
有时可能这还不能够保证分布均匀,不妨从一端向另一端来回折叠后对齐相加。比如我们将987和321反转,再与654和0相加,变成789+654+123+0=1566,此时散列地址为566。
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
保留余数法
此方法为最常用的构造哈希函数的方法。
公式为:
f(key) = key mod p (p <= m)
代码如下:
public int hashFunc(int key){
return key % length;
}
哈希冲突问题以及解决方法
哈希冲突就是,两个不同的关键字,但是通过散列函数得出来的地址是一样的。
key1 ≠ key2,但是f(key1)= f(key2)
同义词
此时的key1 和key2就被称为这个散列函数的同义词
那可不行啊,一件单人间怎么可以住两个人呢?
别担心,这个问题自然已经被神通广大的大佬们解决了。
开放地址法
开发定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只需要散列表足够大,空的散列地址总能找到,并将记录存入
例子:
19 01 23 14 55 68 11 86 37
要存储在表长11的数组中,其中H(key)=key MOD 11
再哈希函数法
对于我们的哈希表来说,我们事先需要准备多个哈希函数。每当发生散列地址冲突时,就换一个哈希函数,总有一个哈希函数能够使关键字不聚集。
公共溢出区法
在原先基础表的基础上再添加一个溢出表
当发生冲突时,就将该数据放到溢出表中
在查找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位置进行对比,如果相等就查找成功,如果不相等,则到溢出表进行顺序查找。

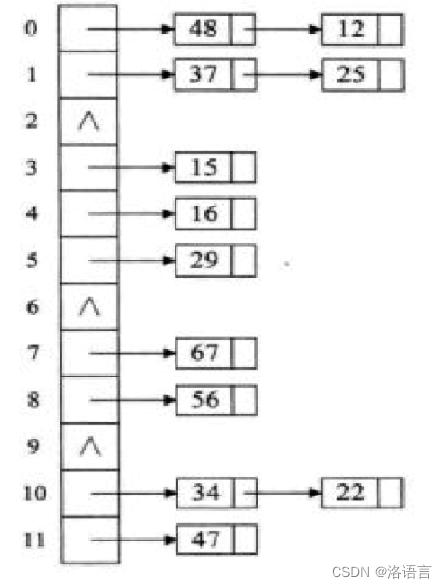
链式地址法
就时用链表将发生冲突的数据链起来,在查找时,只需要遍历链表即可,此方法也是最常用的方法。
如图:
哈希表的填充因子
填充因子就是 :填入表中的键值对个数 / 哈希表长度
填充因子标志着哈希表的装满程度,散列表的平均查找长度取决于填充因子,而不是取决于查找集合的键值对个数。Java中的HashMap默认初始容量为16,默认加载因子为0.75(当底层数组容量占用75%时,数组开始扩容,扩容后容量是原容量的二倍),此时虽然浪费了一定空间,但是换来的是查找效率的大大提升。
代码实现
下面用链式地址法来实现哈希表。
public class HashTableDemo {
//哈希表每个位置链表的节点
class Node{
//关键字
int key;
String value;
Node next;
//无参构造
Node(){}
//有参构造
Node(int key, String value){
this.key = key;
this.value = value;
next = null;
}
//重写哈希表的equals()方法
public boolean equals(Node node){
if(this == node) return true;
else{
if(node == null) return false;
else{
return this.value == node.value && this.key == node.key;
}
}
}
}
//哈希表的长度
int length;
//哈希表存的键值对个数
int size;
//存储数据容器
Node table[];
//不指定初始化长度的无参构造
public HashTableDemo(){
length = 16;
size = 0;
table = new Node[length];
//为哈希表每一个位置初始化
for (int i = 0; i < length; i++) {
table[i] = new Node(i,null);
}
}
//指定初始化长度的有参构造
public HashTableDemo(int length){
this.length = length;
size = 0;
table = new Node[length];
for (int i = 0; i < length; i++) {
table[i] = new Node(i,null);
}
}
}
哈希函数
public int hashFunc(int key){
return key % length;
}
添加数据
思路:
- 先通过哈希函数算出该键值对在table中的位置。
- 遍历该处的链表的每一个节点,若发现某节点的key与传入的key相等,那么就更新此处的value。
- 若未发现相等的key,那么在链表末尾添加新的节点.
- 最后返回value。
代码如下:
public String put(int key, String value){
int index = hashFunc(key);
//保证cur2始终是cur的前一个节点。
Node cur = table[index].next;
Node cur2 = table[index];
while(cur != null){
if(cur.key == key){
cur.value = value;
return value;
}
cur = cur.next;
cur2 = cur2.next;
}
cur2.next = new Node(key, value);
size++;
return value;
}
删除数据
思路:
- 先通过哈希函数算出该键值对在table中的位置。
- 遍历该处的链表的每一个节点,若发现某节点的key与传入的key相等,那么就删除此节点,并返回它的value。
- 若未发现相等的key,返回null。
代码如下:
public String remove(int key){
int index = hashFunc(key);
Node cur = table[index];
while(cur.next != null){
if(cur.next.key == key){
size--;
String value = cur.next.value;
cur.next = cur.next.next;
return value;
}
cur = cur.next;
}
return null;
}
判断哈希表是否为空
思路:判断哈希表每个位置处的链表是否为空。
public boolean isEmpty(){
for(int i = 0; i < length; i++){
if(table[i].next != null)
return false;
}
return true;
}
遍历哈希表
public void print(){
for(int i = 0; i < length; i++){
Node cur = table[i];
System.out.printf("第%d条链表: ",i);
if(cur.next == null){
System.out.println("null");
continue;
}
cur = cur.next;
while(cur != null){
System.out.print(cur.key + "---"+ cur.value + " ");
cur = cur.next;
}
System.out.println();
}
}
获得哈希表已存键值对个数
//返回哈希表已存数据个数
public int size(){
return size;
}
到此这篇关于Java超详细分析讲解哈希表的文章就介绍到这了,更多相关Java哈希表内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
原文出处:https://blog.csdn.net/m0_62969222/article/details/124912720
相关文章
- 这篇文章主要介绍了如何利用java语言实现经典《复杂迷宫》游戏,文中采用了swing技术进行了界面化处理,感兴趣的小伙伴可以动手试一试...2022-02-01
java 运行报错has been compiled by a more recent version of the Java Runtime
java 运行报错has been compiled by a more recent version of the Java Runtime (class file version 54.0)...2021-04-01- 这篇文章主要介绍了在java中获取List集合中最大的日期时间操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-15
- 这篇文章主要介绍了教你怎么用Java获取国家法定节假日,文中有非常详细的代码示例,对正在学习java的小伙伴们有非常好的帮助,需要的朋友可以参考下...2021-04-23
- 这篇文章主要介绍了Java如何发起http请求的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-31
- 说起C#和Java这两门语言(语法,数据类型 等),个人以为,大概有90%以上的相似,甚至可以认为几乎一样。但是在工作中,我也发现了一些细微的差别...2020-06-25
- 这篇文章主要介绍了解决Java处理HTTP请求超时的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-29
- 这篇文章主要介绍了java 判断两个时间段是否重叠的案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-15
- 这篇文章主要介绍了超简洁java实现双色球若干注随机号码生成(实例代码),本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-04-02
- 这篇文章主要介绍了Java生成随机姓名、性别和年龄的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-10-01
java 画pdf用itext调整表格宽度、自定义各个列宽的方法
这篇文章主要介绍了java 画pdf用itext调整表格宽度、自定义各个列宽的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-31- 这篇文章主要介绍了java正则表达式判断前端参数修改表中另一个字段的值,需要的朋友可以参考下...2021-05-07
Java使用ScriptEngine动态执行代码(附Java几种动态执行代码比较)
这篇文章主要介绍了Java使用ScriptEngine动态执行代码,并且分享Java几种动态执行代码比较,需要的朋友可以参考下...2021-04-15- 这篇文章主要介绍了Java开发实现人机猜拳游戏,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-08-03
- 这篇文章主要介绍了Java List集合返回值去掉中括号('[ ]')的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-29
Java中lombok的@Builder注解的解析与简单使用详解
这篇文章主要介绍了Java中lombok的@Builder注解的解析与简单使用,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-01-06- 下面小编就为大家带来一篇java中String类型变量的赋值问题介绍。小编觉得挺不错的。现在分享给大家,给大家一个参考。...2016-03-28
Java 8 Stream 的终极技巧——Collectors 功能与操作方法详解
这篇文章主要介绍了Java 8 Stream Collectors 功能与操作方法,结合实例形式详细分析了Java 8 Stream Collectors 功能、操作方法及相关注意事项,需要的朋友可以参考下...2020-05-20- 这篇文章主要介绍了Java线程池中的各个参数如何合理设置操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-06-19
- 在Java中,我们可以利用多线程来最大化地压榨CPU多核计算的能力,下面这篇文章主要给大家介绍了关于java中多线程与线程池基本使用的相关资料,需要的朋友可以参考下...2021-09-13