Elasticsearch Recovery索引分片分配详解
基础知识点
在Eleasticsearch中recovery指的就是一个索引的分片分配到另外一个节点的过程;一般在快照恢复、索引副本数变更、节点故障、节点重启时发生。由于master保存整个集群的状态信息,因此可以判断出哪些shard需要做再分配,以及分配到哪个结点,例如:
如果某个shard主分片在,副分片所在结点挂了,那么选择另外一个可用结点,将副分片分配(allocate)上去,然后进行主从分片的复制。
如果某个shard的主分片所在结点挂了,副分片还在,那么将副分片升级为主分片,然后做主从分片复制。
如果某个shard的主副分片所在结点都挂了,则暂时无法恢复,等待持有相关数据的结点重新加入集群后,从该结点上恢复主分片,再选择另外的结点复制副分片。
正常情况下,我们可以通过ES的health的API接口,查看整个集群的健康状态和整个集群数据的完整性:

状态及含义如下:
green: 所有的shard主副分片都是正常的;
yellow: 所有shard的主分片都完好,部分副分片没有或者不完整,数据完整性依然完好;
red: 某些shard的主副分片都没有了,对应的索引数据不完整。
recovery过程要消耗额外的资源,CPU、内存、结点之间的网络带宽等等。 这些额外的资源消耗,有可能会导致集群的服务性能下降,或者一部分功能暂时不可用。了解一些recovery的过程和相关的配置参数,对于减小recovery带来的资源消耗,加快集群恢复过程都是很有帮助的。
减少集群Full Restart造成的数据来回拷贝
ES集群可能会有整体重启的情况,比如需要升级硬件、升级操作系统或者升级ES大版本。重启所有结点可能带来的一个问题: 某些结点可能先于其他结点加入集群, 先加入集群的结点可能已经可以选举好master,并立即启动了recovery的过程,由于这个时候整个集群数据还不完整,master会指示一些结点之间相互开始复制数据。 那些晚到的结点,一旦发现本地的数据已经被复制到其他结点,则直接删除掉本地“失效”的数据。 当整个集群恢复完毕后,数据分布不均衡,显然是不均衡的,master会触发rebalance过程,将数据在节点之间挪动。整个过程无谓消耗了大量的网络流量;合理设置recovery相关参数则可以防范这种问题的发生。
gateway.expected_nodes gateway.expected_master_nodes gateway.expected_data_nodes
以上三个参数是说集群里一旦有多少个节点就立即开始recovery过程。 不同之处在于,第一个参数指的是master或者data都算在内,而后面两个参数则分指master和data node。
在期待的节点数条件满足之前, recovery过程会等待gateway.recover_after_time (默认5分钟) 这么长时间,一旦等待超时,则会根据以下条件判断是否启动:
gateway.expected_nodes gateway.expected_master_nodes gateway.expected_data_nodes
举例来说,对于一个有10个data node的集群,如果有以下的设置:
gateway.expected_data_nodes: 10 gateway.recover_after_time: 5m gateway.recover_after_data_nodes: 8
那么集群5分钟以内10个data node都加入了,或者5分钟以后8个以上的data node加入了,都会立即启动recovery过程。
减少主副本之间的数据复制
如果不是full restart,而是重启单个data node,仍然会造成数据在不同结点之间来回复制。为避免这个问题,可以在重启之前,先关闭集群的shard allocation:
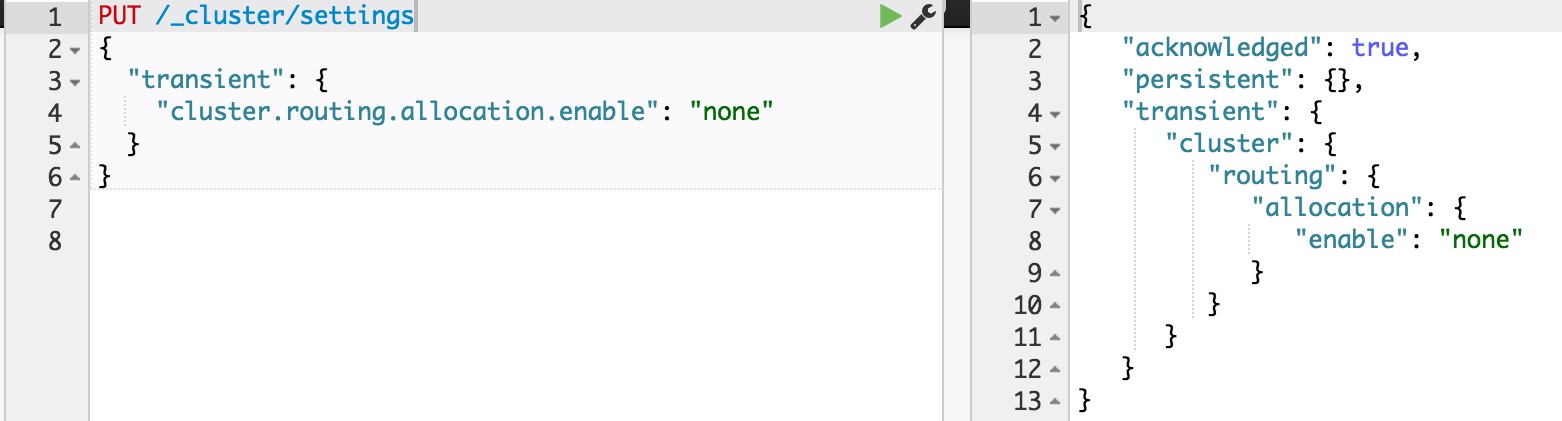
然后在节点重启完成加入集群后,再重新打开:
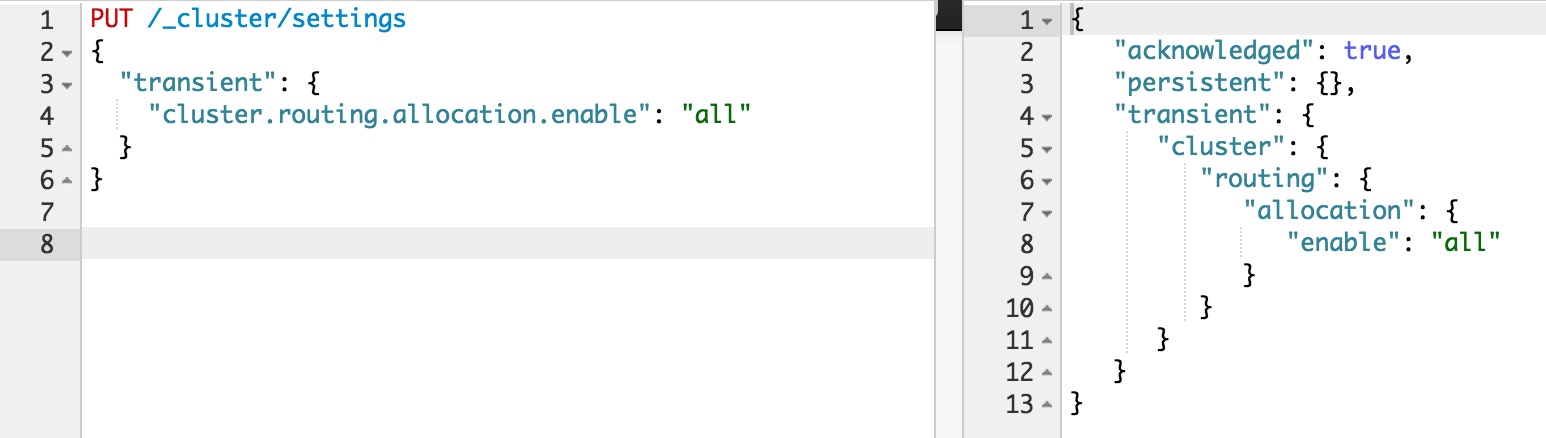
这样在节点重启完成后,尽量多的从本地直接恢复数据。
但是在ES1.6版本之前,即使做了以上措施,仍然会发现有大量主副本之间的数据拷贝。从表面去看,这点很让人不能理解。
主副本数据完全一致,ES应该直接从副本本地恢复数据就好了,为什么要重新从主片再复制一遍呢? 原因在于recovery是简单对比主副本的segment file来判断哪些数据一致可以本地恢复,哪些不一致需要远端拷贝的。
而不同节点的segment merge是完全独立运行的,可能导致主副本merge的深度不完全一样,从而造成即使文档集完全一样,产生的segment file却不完全一样。
为了解决这个问题,ES1.6版本以后加入了synced flush的新特性。 对于5分钟没有更新过的shard,会自动synced flush一下,实质是为对应的shard加了一个synced flush ID。这样当重启节点的时候,先对比一下shard的synced flush ID,就可以知道两个shard是否完全相同,避免了不必要的segment file拷贝,极大加快了冷索引的恢复速度。
需要注意的是synced flush只对冷索引有效,对于热索引(5分钟内有更新的索引)没有作用。 如果重启的结点包含有热索引,那么还是免不了大量的文件拷贝
。因此在重启一个结点之前,最好按照以下步骤执行,recovery几乎可以瞬间完成:
- 暂停数据写入程序
- 关闭集群shard allocation
- 手动执行POST /_flush/synced
- 重启节点
- 重新开启集群shard allocation
- 等待recovery完成,集群health status变成green
- 重新开启数据写入程序
特大热索引为何恢复慢
对于冷索引,由于数据不再更新,利用synced flush特性,可以快速直接从本地恢复数据。 而对于热索引,特别是shard很大的热索引,;除了synced flush派不上用场需要大量跨节点拷贝segment file以外,translog recovery是导致慢的更重要的原因。
从主片恢复数据到副片需要经历3个阶段:
- 对主片上的segment file做一个快照,然后拷贝到复制片分配到的结点。数据拷贝期间,不会阻塞索引请求,新增索引操作记录到translog里。
- 对translog做一个快照,此快照包含第一阶段新增的索引请求,然后重放快照里的索引操作。此阶段仍然不阻塞索引请求,新增索引操作记录到translog里。
- 为了能达到主副片完全同步,阻塞掉新索引请求,然后重放阶段二新增的translog操作。
可见,在recovery完成之前,translog是不能够被清除掉的(禁用掉正常运作期间后台的flush操作)。
如果shard比较大,第一阶段耗时很长,会导致此阶段产生的translog很大。重放translog比起简单的文件拷贝耗时要长得多,因此第二阶段的translog耗时也会显著增加。
等到第三阶段,需要重放的translog可能会比第二阶段还要多。 而第三阶段是会阻塞新索引写入的,在对写入实时性要求很高的场合,就会非常影响用户体验。
因此,要加快大的热索引恢复速度,最好的方式是遵从上一节提到的方法: 暂停新数据写入,手动sync flush,等待数据恢复完成后,重新开启数据写入,这样可以将数据延迟影响可以降到最低。
万一遇到Recovery慢,想知道进度怎么办呢? CAT Recovery API可以显示详细的recovery各个阶段的状态。 这个API怎么用就不在这里赘述了,参考: CAT Recovery。
其他Recovery相关的专家级设置
还有其他一些专家级的设置(参见: recovery)可以影响recovery的速度,但提升速度的代价是更多的资源消耗,因此在生产集群上调整这些参数需要结合实际情况谨慎调整,一旦影响应用要立即调整回来。
对于搜索并发量要求高,延迟要求低的场合,默认设置一般就不要去动了。
对于日志实时分析类对于搜索延迟要求不高,但对于数据写入延迟期望比较低的场合,可以适当调大indices.recovery.max_bytes_per_sec,提升recovery速度,减少数据写入被阻塞的时长。
最后要说的一点是ES的版本迭代很快,对于Recovery的机制也在不断的优化中。 其中有一些版本甚至引入了一些bug,比如在ES1.4.x有严重的translog recovery bug,导致大的索引trans log recovery几乎无法完成 。
因此实际使用中如果遇到问题,最好在Github的issue list里搜索一下,看是否使用的版本有其他人反映同样的问题。
以上就是Elasticsearch Recovery索引分片分配详解的详细内容,更多关于Elasticsearch Recovery索引分片分配的资料请关注猪先飞其它相关文章!
原文出处:https://blog.csdn.net/u012450329/article/details/52881045
相关文章
- 联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进...2015-11-24
Elasticsearch工具cerebro的安装与使用教程
这篇文章主要介绍了Elasticsearch工具cerebro的安装与使用教程,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-08docker 启动elasticsearch镜像,挂载目录后报错的解决
这篇文章主要介绍了docker 启动 elasticsearch镜像,挂载目录后报错的解决,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-11-20- mysql 唯一索引UNIQUE一般用于不重复数据字段了我们经常会在数据表中的id设置为唯一索引UNIQUE,下面我来介绍如何在mysql中使用唯一索引UNIQUE吧。 创建唯一索引的目的不是为了提高访问速度,而只是为了避免数据出现重复...2015-11-24
R语言 install.packages 无法读取索引的解决方案
这篇文章主要介绍了R语言 install.packages 无法读取索引的解决方案,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-06- 其他强制操作,优先操作如下:mysql常用的hint对于经常使用oracle的朋友可能知道,oracle的hint功能种类很多,对于优化sql语句提供了很多方法。同样,在mysql里,也有类似的hint功能。下面介绍一些常用的。强制索引 FORCE INDEX...2014-05-31
- 这篇文章主要介绍了c#索引(Index)和范围(Range)的相关资料,帮助大家更好的理解和学习c#,感兴趣的朋友可以了解下...2020-12-08
- 通过本文可以帮助大家快速学习Docker安装ElasticSearch的过程,本文通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧...2021-08-31
golang elasticsearch Client的使用详解
这篇文章主要介绍了golang elasticsearch Client的使用详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-04- 这篇文章主要介绍了MySQL 索引使用方法的相关资料,文中示例代码非常详细,帮助大家更好的理解和学习,感兴趣的朋友可以了解下...2020-07-05
- 这篇文章主要给大家介绍了关于oracle索引测试的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-01-17
- 如果你在面试中,听到MySQL5.6”、“索引优化” 之类的词语,你就要立马get到,这个问的是“索引下推”。本文就来分分享这个小知识点索引下推...2021-09-16
- Abs: 取得绝对值。 Acos: 取得反余弦值。 ada_afetch: 取得数据库的返回列。 ada_autocommit: 开关自动改动功能。 ada_close: 关闭 Adabas D 链接。 ada_commit: 改...2016-11-25
- 这篇文章主要介绍了Mysql判断表字段或索引是否存在的相关资料,非常不错具有参考借鉴价值,需要的朋友可以参考下...2016-06-12
- 这篇文章主要介绍了MySQL数据库优化技术之索引使用方法,结合实例形式总结分析了MySQL表的优化、索引设置、SQL优化等相关技巧,非常具有实用价值,需要的朋友可以参考下...2016-07-29
- 这篇文章主要介绍了R语言 查找满足条件的数并获取索引的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-06
- 这篇文章主要介绍了使用postman操作ElasticSearch的方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-05
- 这篇文章主要介绍了java连接ElasticSearch集群操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-09-17
- 这篇文章主要介绍了MySQL索引用法,结合实例形式较为详细的分析了mysql索引的功能、定义、使用方法与相关注意事项,需要的朋友可以参考下...2016-07-29
elasticsearch+logstash并使用java代码实现日志检索
这篇文章主要介绍了elasticsearch+logstash并使用java代码实现日志检索,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-02-22