超简单的scrapy实现ip动态代理与更换ip的方法实现
简单实现ip代理,为了不卖广告,
请自行准备一个ip代理的平台
例如我用的这个平台,每次提取10个ip

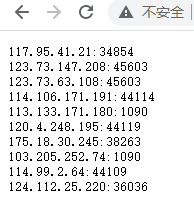
从上面可以看到数据格式是文本,换行是\r\n,访问链接之后大概就是长这样的,scrapy里面的ip需要加上前缀http://
例如:http://117.95.41.21:34854
OK,那现在已经准备好了ip了,先给你们屡一下思路。
ip池和计数器放在setting文件
第一次请求的时候要填满ip池,所以在爬虫文件的start_requests函数下手
更换ip的地方是middlewares的下载器中间件类的process_request函数,因为每个请求发起前都会经过这个函数
首先是setting文件,其实就是加两句代码
count = {'count': 0}
ipPool = []
还有就是开启下载器中间件,注意是下面那个download的类,中间件的process_request函数的时候才能生效
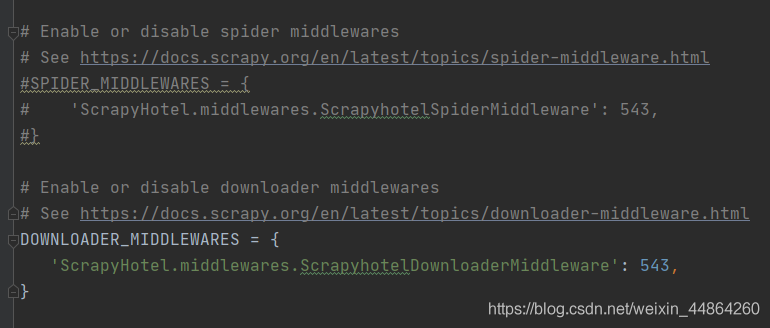
下载器中间件的process_request函数,进行ip代理和固定次数更还ip代理池
# 记得导包
from 你的项目.settings import ipPool, count
import random
import requests
def process_request(self, request, spider):
# 随机选中一个ip
ip = random.choice(ipPool)
print('当前ip', ip, '-----', count['count'])
# 更换request的ip----------这句是重点
request.meta['proxy'] = ip
# 如果循环大于某个值,就清理ip池,更换ip的内容
if count['count'] > 50:
print('-------------切换ip------------------')
count['count'] = 0
ipPool.clear()
ips = requests.get('你的ip获取的地址')
for ip in ips.text.split('\r\n'):
ipPool.append('http://' + ip)
# 每次访问,计数器+1
count['count'] += 1
return None
最后就是爬虫文件的start_requests函数,就是第一次发请求前要先填满ip池的ip
# 记得导包
from 你的项目.settings import ipPool
import random
import requests
def start_requests(self):
# 第一次请求发起前先填充一下ip池
ips = requests.get('你的ip获取的地址')
for ip in ips.text.split('\r\n'):
ipPool.append('http://' + ip)
简单的ip代理以及固定次数就更换ip池就完成了
到此这篇关于超简单的scrapy实现ip动态代理与更换ip的方法实现的文章就介绍到这了,更多相关scrapy ip动态代理与更换ip内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 这篇文章主要为大家介绍了Python爬虫进阶中Scrapy框架精细讲解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步...2021-10-22
python实战scrapy操作cookie爬取博客涉及browsercookie
这篇文章主要为大家介绍了python实战scrapy操作cookie爬取博客涉及browsercookie,下面来学习一下 scrapy 操作 Cookie来爬取博客吧...2021-11-13Python中Scrapy+adbapi提高数据库写入效率实现
本文主要介绍了Python中Scrapy+adbapi提高数据库写入效率实现,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-10-21- 这篇文章主要介绍了Scrapy实现模拟登录的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-21
- 这篇文章主要介绍了详解基于Scrapy的IP代理池搭建,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-09-29
- 这篇文章主要介绍了超简单的scrapy实现ip动态代理与更换ip的方法实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-21
pycharm无法安装第三方库的问题及解决方法以scrapy为例(图解)
这篇文章主要介绍了pycharm无法安装第三方库的解决办法以scrapy为例,本文通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-05-10- 这篇文章主要介绍了Python利用Scrapy框架爬取豆瓣电影,结合实例形式分析了Python使用Scrapy框架爬取豆瓣电影信息的具体操作步骤、实现技巧与相关注意事项,需要的朋友可以参考下...2020-04-27
- 在本篇文章里小编给大家整理的是一篇关于python scrapy简单模拟登录的代码分析,有兴趣的朋友们可以学习参考下。...2021-07-19
- 这篇文章主要给大家介绍了关于scrapy利用selenium爬取豆瓣阅读的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-09-21
- 这篇文章主要介绍了使用scrapy进行模拟登陆三种方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-21
- 在本篇文章里小编给大家整理的是一篇关于python中用Scrapy实现定时爬虫的实例讲解内容,有兴趣的朋友们可以学习下。...2021-01-18
详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
这篇文章主要介绍了详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-01-25- 这篇文章主要介绍了Scrapy启动报错invalid syntax的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-09-18
- 这篇文章主要介绍了python实现Scrapy爬取网易新闻,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-21
- 这篇文章主要介绍了Django-Scrapy生成后端json接口的方法示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-10-06
- 这篇文章主要为大家介绍了使用python scrapy简单代码实现搜狗图片下载器示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助...2021-11-13
详解向scrapy中的spider传递参数的几种方法(2种)
这篇文章主要介绍了详解向scrapy中的spider传递参数的几种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-09-28- 这篇文章主要介绍了scrapy中如何设置应用cookies的方法(3种),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-09-22
- scrapy是一个使用Python语言(基于Twisted框架)编写的开源网络爬虫框架,目前由scrapinghub Ltd维护.Scrapy简单易用、灵活易拓展、开发社区活跃,并且是跨平台的.在Linux、MaxOS以及windows平台都可以使用,需要的朋友可以参考下...2021-06-18