教你如何利用python3爬虫爬取漫画岛-非人哉漫画
最近学了一点点python爬虫的知识,面向百度编程爬了一本小说之后感觉有点不满足,于是突发奇想尝试爬一本漫画下来看看。
一、效果展示
首先是我们想要爬取的漫画网页:http://www.manhuadao.cn/
网页截图:
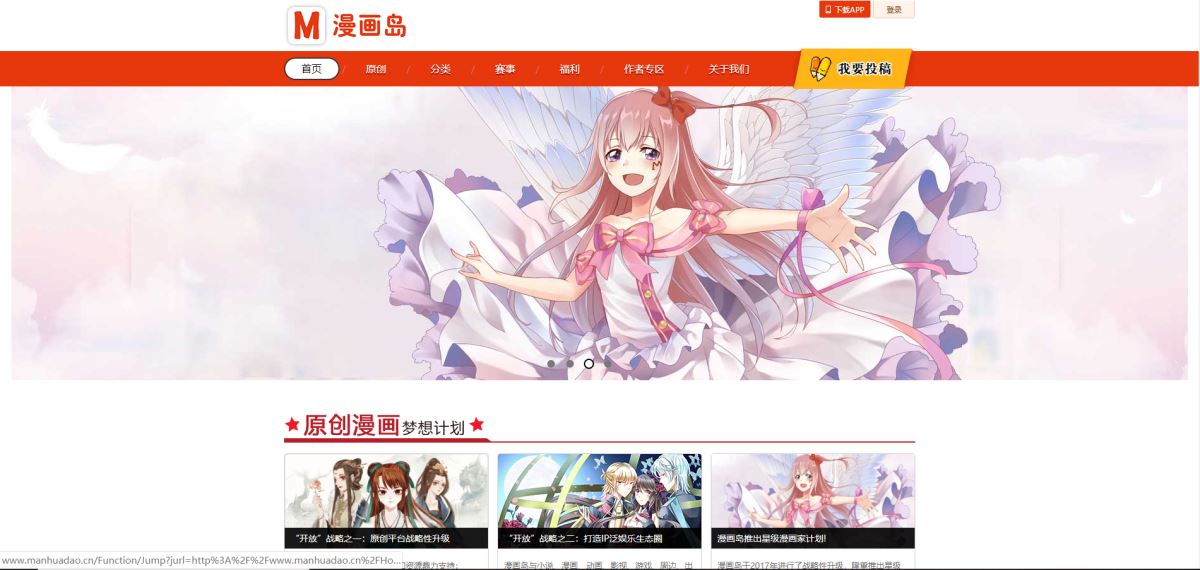
其次是爬取下来的效果:
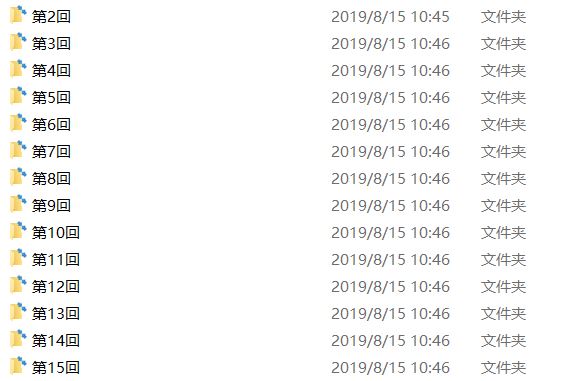
每一回的文件夹里面是这样的: (因为网站图片的问题...所以就成了这个鬼样子)

二、分析原理
1、准备:需要vscode或者其他能够编译运行python的软件,推荐python版本3.X ,否则有可能出现编译问题。
下载所需模块:win+R进入命令行,输入pipinstall <模块名>即可下载。例如:
pip install beautifulsoup4
2、原理: 模拟浏览器点击->打开漫画网页链接->获取网页源码->定位每一章漫画的链接->模拟点击->获取图片页面源码->定位图片链接->下载图片
三、实际操作(代码附在最后)
1、引入模块 (这里不再详述)
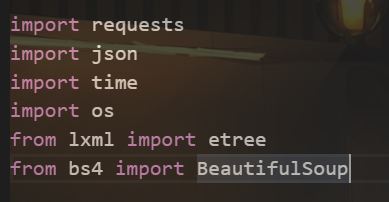
2、模拟浏览器访问网页

(1)、这里我们打开漫画的目录页,如下: url = ”http://www.manhuadao.cn/Home/ComicDetail?id=58ddb07827a7c1392c234628“ ,此链接就是目录页链接。

(2)、按F12打开此网页的源码(谷歌浏览器),选中上方NetWork,Ctrl+R刷新。
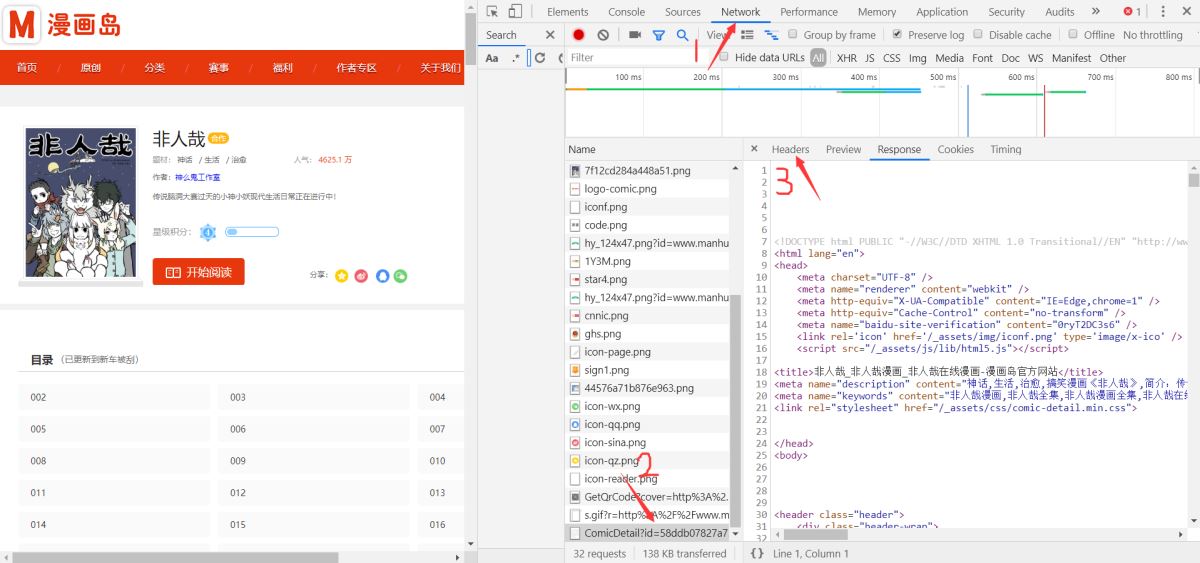
(3)、找到加载网页的源码文件,点击Headers,如下图: StatusCode表示网页返回的代码,值为200时表示访问成功。
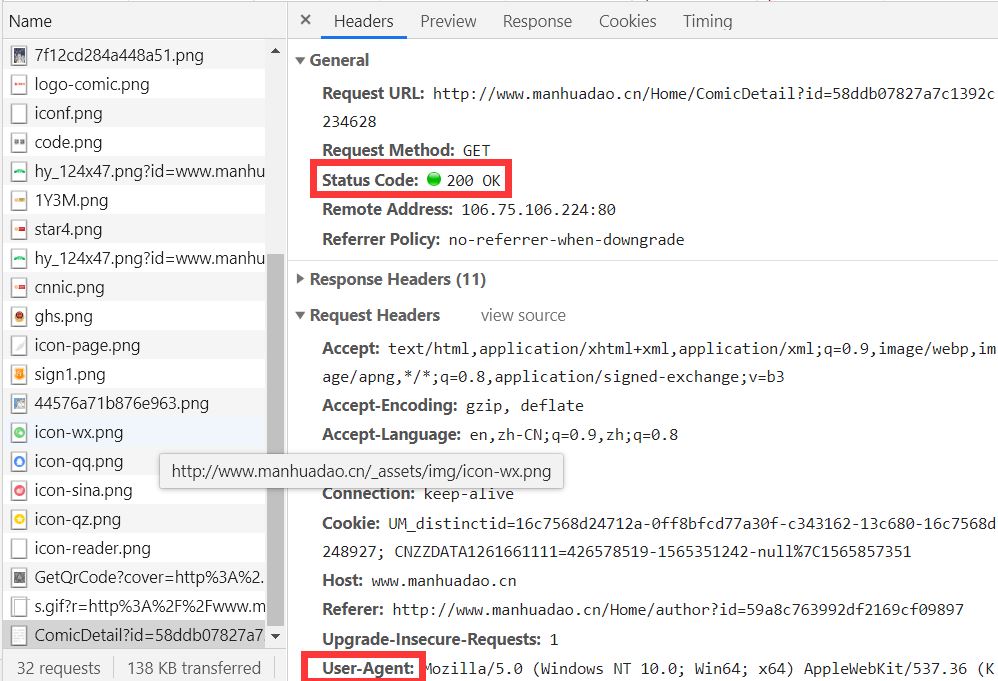
(4)、headers中的参数为下面红框User-Agent。
response = requests.get(url=url, headers=headers) # 模拟访问网页 print(response) # 此处应输出 <Response [200]> print(response.text) # 输出网页源码
两个输出分别输出:
 输出返回200表示访问成功。
输出返回200表示访问成功。
 (节选)
(节选)
(5)、将html代码存入 data 中,xpath定位每一章链接。点击上方Element,点击:
将鼠标移至目录处:

右边代码区域出现每一章链接:

data = etree.HTML(response.text)
# tp = data.xpath('//ul[@class="read-chapter"]/li/a[@class="active"]/@href')
tp = data.xpath('//*[@class="yesReader"]/@href')
zhang_list = tp # tp为链接列表
输出zhang_list,结果如下:

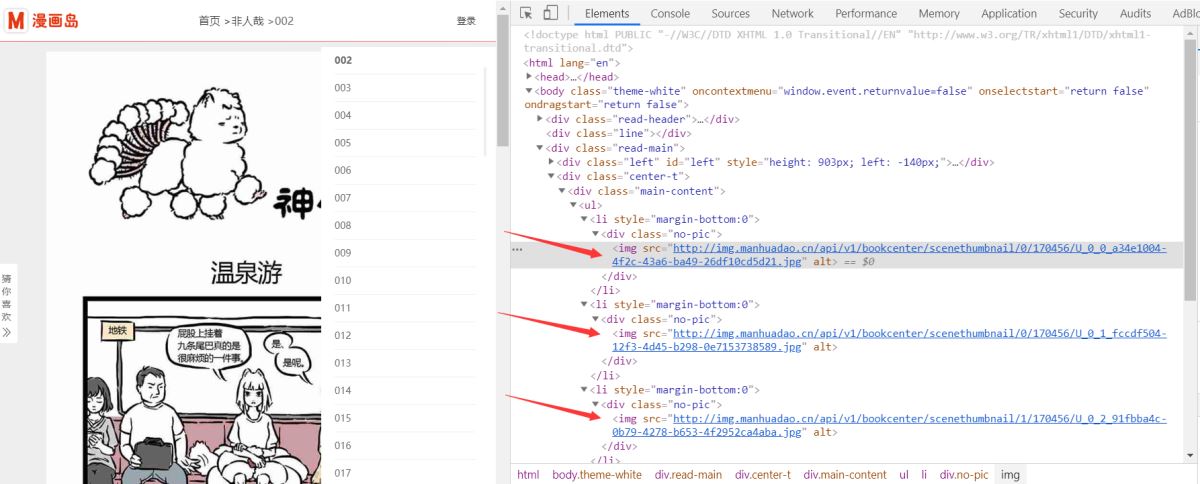
(6)、获取图片链接(获取方式同上一步)
点进第一章,同上一步,寻找到图片链接:
i=1
for next_zhang in zhang_list: # 在章节列表中循环
i=i+1
j=0
hui_url = r_url+next_zhang
name1 = "第"+str(i)+"回"
file = 'C:/Users/wangyueke/Desktop/'+keyword+'/{}/'.format(name1) # 创建文件夹
if not os.path.exists(file):
os.makedirs(file)
print('创建文件夹:', file)
response = requests.get(url=hui_url, headers=headers) # 模拟访问每一章链接
data = etree.HTML(response.text)
# tp = data.xpath('//div[@class="no-pic"]//img/@src')
tp = data.xpath('//div[@class="main-content"]//ul//li//div[@class="no-pic"]//img/@src') # 定位
ye_list = tp
(7)、下载图片
for k in ye_list: # 在每一章的图片链接列表中循环
download_url = tp[j]
print(download_url)
j=j+1
file_name="第"+str(j)+"页"
response = requests.get(url=download_url) # 模拟访问图片链接
with open(file+file_name+".jpg","wb") as f:
f.write(response.content)
五、代码
'''
用于爬取非人哉漫画
目标网址:http://www.manhuadao.cn/
开始时间:2019/8/14 20:01:26
完成时间:2019/8/15 11:04:56
作者:kong_gu
'''
import requests
import json
import time
import os
from lxml import etree
from bs4 import BeautifulSoup
def main():
keyword="非人哉"
file = 'E:/{}'.format(keyword)
if not os.path.exists(file):
os.mkdir(file)
print('创建文件夹:',file)
r_url="http://www.manhuadao.cn/"
url = "http://www.manhuadao.cn/Home/ComicDetail?id=58ddb07827a7c1392c234628"
headers = { # 模拟浏览器访问网页
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \\Chrome/75.0.3770.142 Safari/537.36'}
response = requests.get(url=url, headers=headers)
# print(response.text) # 输出网页源码
data = etree.HTML(response.text)
# tp = data.xpath('//ul[@class="read-chapter"]/li/a[@class="active"]/@href')
tp = data.xpath('//*[@class="yesReader"]/@href')
zhang_list = tp
i=1
for next_zhang in zhang_list:
i=i+1
j=0
hui_url = r_url+next_zhang
name1 = "第"+str(i)+"回"
file = 'C:/Users/wangyueke/Desktop/'+keyword+'/{}/'.format(name1) # 这里需要自己设置路径
if not os.path.exists(file):
os.makedirs(file)
print('创建文件夹:', file)
response = requests.get(url=hui_url, headers=headers)
data = etree.HTML(response.text)
# tp = data.xpath('//div[@class="no-pic"]//img/@src')
tp = data.xpath('//div[@class="main-content"]//ul//li//div[@class="no-pic"]//img/@src')
ye_list = tp
for k in ye_list:
download_url = tp[j]
print(download_url)
j=j+1
file_name="第"+str(j)+"页"
response = requests.get(url=download_url)
with open(file+file_name+".jpg","wb") as f:
f.write(response.content)
if __name__ == '__main__':
main()
到此这篇关于利用python3爬虫爬取漫画岛-非人哉漫画的文章就介绍到这了,更多相关python3爬虫漫画岛内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 这篇文章主要介绍了Python3 实现将bytes图片转jpg格式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-08
Python3中小括号()、中括号[]、花括号{}的区别详解
这篇文章主要介绍了Python3中小括号()、中括号[]、花括号{}的区别详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-15- 在本篇内容里小编给大家分享的是关于用C#做网络爬虫的步骤和方法,需要的朋友们可以参考下。...2020-06-25
- 这篇文章主要介绍了Python3 常用数据标准化方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-24
- 今天带大家来学习selenium库的使用方法及相关知识总结,文中非常详细的介绍了selenium库,对正在学习python的小伙伴很有帮助,需要的朋友可以参考下...2021-05-25
- 这篇文章主要介绍了selenium 反爬虫之跳过淘宝滑块验证功能,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-08-27
- 这篇文章主要介绍了利用C#实现网络爬虫,完整的介绍了C#实现网络爬虫详细过程,感兴趣的小伙伴们可以参考一下...2020-06-25
- 这篇文章主要介绍了Nginx中配置过滤爬虫的User-Agent的简单方法,文中罗列了一些常用搜索引擎的爬虫名称以免造成不必要的过滤,需要的朋友可以参考下...2016-01-27
python爬虫用request库处理cookie的实例讲解
在本篇内容里小编给大家整理的是一篇关于python爬虫用request库处理cookie的实例讲解内容,有需要的朋友们可以学习参考下。...2021-02-21- 本文主要讲述了利用Python网络爬虫对指定京东商城中指定商品下的用户评论进行爬取,对数据预处理操作后进行文本情感分析,感兴趣的朋友可以了解下...2021-05-28
- 这篇文章主要介绍了浅谈Python3中print函数的换行,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-08-05
- 这篇文章主要介绍了解决python3安装pandas出错的问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-05-20
- 这篇文章主要为大家详细介绍了基于C#实现网页爬虫的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-06-25
c# Selenium爬取数据时防止webdriver封爬虫的方法
这篇文章主要介绍了c# Selenium爬取数据时防止webdriver封爬虫的方法,帮助大家更好的理解和使用c#,感兴趣的朋友可以了解下...2021-01-15- 这篇文章主要介绍了python3 sqlite3限制条件查询的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-04-07
- 本篇文章给大家分享了C#爬虫通过代理刷文章浏览量的详细步骤和方法,有兴趣的朋友可以参考学习下。...2020-06-25
- 这篇文章主要介绍了node.js爬虫框架node-crawler的相关资料,帮助大家利用node.js进行爬虫,感兴趣的朋友可以了解下...2020-10-29
- 这篇文章主要介绍了如何快速一键生成Python爬虫请求头,帮助大家更好的理解和学习使用python爬虫,感兴趣的朋友可以了解下...2021-03-05
- 这篇文章主要介绍了python3 循环读取excel文件并写入json操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-07-14
- 这篇文章主要介绍了python网络爬虫实现发送短信验证码的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-25