Python爬取网页信息的示例
Python爬取网页信息的步骤
以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例。
1、确认网址
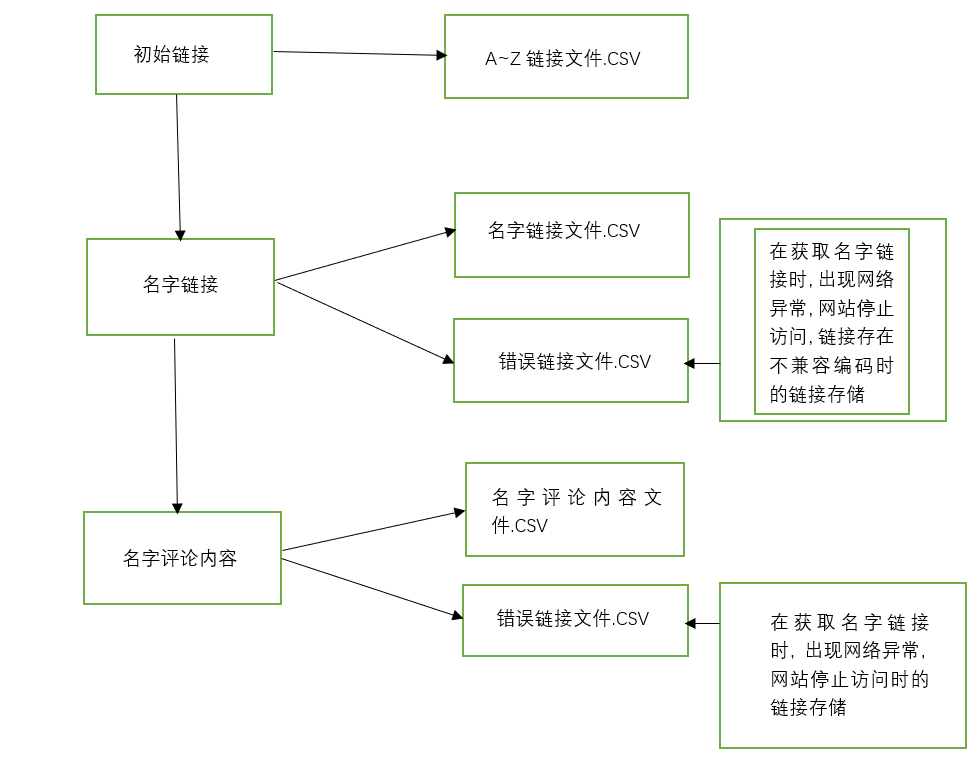
在浏览器中输入初始网址,逐层查找链接,直到找到需要获取的内容。
在打开的界面中,点击鼠标右键,在弹出的对话框中,选择“检查”,则在界面会显示该网页的源代码,在具体内容处点击查找,可以定位到需要查找的内容的源码。
注意:代码显示的方式与浏览器有关,有些浏览器不支持显示源代码功能(360浏览器,谷歌浏览器,火狐浏览器等是支持显示源代码功能)
步骤图:
1)首页,获取A~Z的页面链接

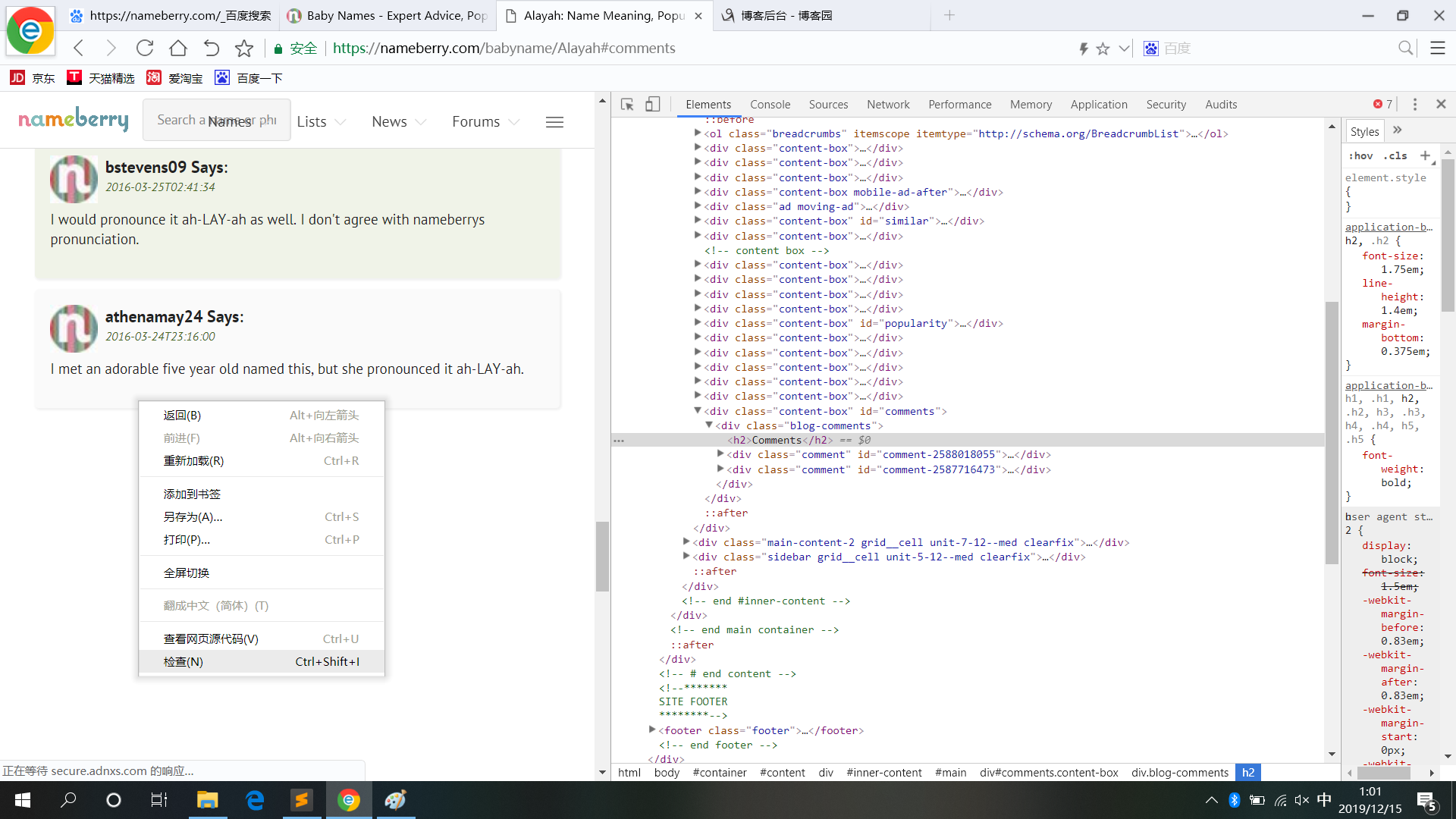
2)名字链接页,获取每个字母中的名字链接(存在翻页情况)

3)名字内容页,获取每个名字的评论信息
2、编写测试代码
1)获取A~Z链接,在爬取网页信息时,为了减少网页的响应时间,可以根据已知的信息,自动生成对应的链接,这里采取自动生成A~Z之间的连接,以pandas的二维数组形式存储
def get_url1():
urls=[]
# A,'B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'
a=['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] #自动生成A~Z的链接
for i in a:
urls.append("https://nameberry.com/search/baby_names_starting_with/%s" %i)
dp=pd.DataFrame(urls)
dp.to_csv("A~Z_Link1.csv",mode="a",encoding='utf_8_sig') #循环用于在每个字母链接下,调用爬取名字链接的页面的函数,即函数嵌套
for j in urls:
get_pages_Html(j)
return urls
2)获取名字链接,根据网页源码分析出包含名字链接的标签,编写代码,名字链接用直接存储的方式存储,方便读取名字链接进行对名字的评论内容的获取
#获取页数
def get_pages_Html(url1):
req = requests.get(url1)
soup=BeautifulSoup(req.text)
#异常处理,为解决页面不存在多页的问题,使用re正则表达式获取页面数
try:
lastpage = soup.find(class_="last").find("a")['href']
str1='{}'.format(lastpage)
b=re.findall('\\d+', str1 )
for page in b:
num=page
except:
num=1
get_pages(num,url1)
return num
def get_pages(n,url):
pages=[]
for k in range(1,int(n)+1):
pages.append("{}?page={}".format(url,k))
dp=pd.DataFrame(pages)
dp.to_csv("NUM_pages_1.csv",mode="a",encoding='utf_8_sig')
#函数调用
for l in pages:
parse_HTML2(l)
return pages
# 名字的链接,根据网页源码的标签,确定名字链接的位置
def parse_HTML2(url2):
try:
req = requests.get(url2)
req.encoding = req.apparent_encoding
soup = BeautifulSoup(req.text)
except:
dp=pd.DataFrame(url2)
dp.to_csv("Error_pages_1.csv",mode="a",encoding='utf_8_sig')
name_data_l=[]
error=[]
li_list = soup.find_all('li',class_="Listing-name pt-15 pb-15 bdb-gray-light w-100pct flex border-highlight")
try:
for li in li_list:
nameList=li.find('a',class_='flex-1')['href']
name_data_l.append('https://nameberry.com/'+nameList)
time.sleep(1)
cun(name_data_l,'Name_List_1')
except:
dp=pd.DataFrame(name_data_l)
dp.to_csv("Error_Name_List_1.csv",mode="a",encoding='utf_8_sig')
# cun(url2,'Error_link_Q')
# dp=pd.DataFrame(name_data_l)
# dp.to_csv("Name_List.csv",mode="a",encoding='utf_8_sig')
# for i in name_data_l:
# parse_HTML3(i)
return name_data_l
3)获取名字评论的内容,采用字典形式写入文件
# 名字里的内容
def parse_HTML3(url3):
count=0
req = requests.get(url3)
req.encoding = req.apparent_encoding
soup = BeautifulSoup(req.text)
error=[]
try:
Name=soup.find('h1',class_='first-header').find("a").get_text().replace(",","").replace("\n","")
except:
error.append(url3)
cun(error,"Error_Link_Comment")
li_list = soup.find_all('div',class_="comment")
for li in li_list:
Title=li.find("h4").get_text().replace(",","").replace("\n","")
Time=li.find("p",class_='meta').get_text().replace(",","").replace("\n","")
Comments=li.find("div",class_='comment-text').get_text().replace(",","").replace("\n","")
dic2={
"Name":Name,
"Title":Title,
"Time":Time,
"Comments":Comments
}
time.sleep(1)
count=count+1
save_to_csv(dic2,"Name_data_comment")
print(count)
return 1
3、测试代码
1)代码编写完成后,具体的函数调用逻辑,获取链接时,为直接的函数嵌套,获取内容时,为从文件中读取出名字链接,在获取名字的评论内容。避免因为逐层访问,造成访问网页超时,出现异常。
如图:
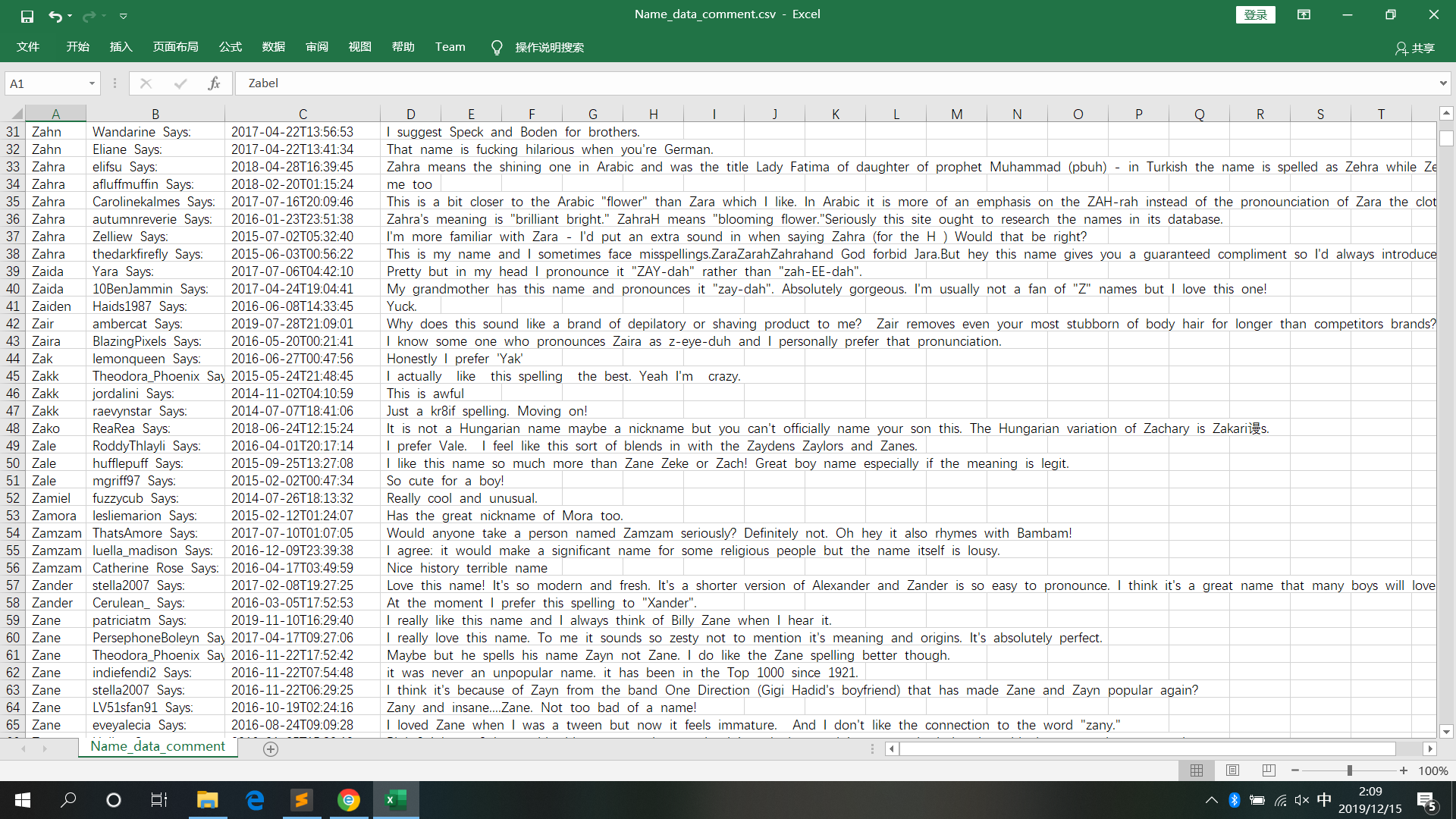
2)测试结果
4、小结
在爬取网页内容时,要先分析网页源码,再进行编码和调试,遵从爬虫协议(严重者会被封号),在爬取的数据量非常大时,可以设置顺序部分请求(一部分的进行爬取网页内容)。
总之,爬虫有风险,测试需谨慎!!!
以上就是Python爬取网页信息的示例的详细内容,更多关于Python爬取网页信息的资料请关注猪先飞其它相关文章!
相关文章
- 这篇文章主要介绍了python-opencv-画外接矩形框的实例代码,代码简单易懂,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-09-04
Python astype(np.float)函数使用方法解析
这篇文章主要介绍了Python astype(np.float)函数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-06-08- 2022虎年新年即将来临,小编为大家带来了一个利用Python编写的虎年烟花特效,堪称全网最绚烂,文中的示例代码简洁易懂,感兴趣的同学可以动手试一试...2022-02-14
- 在本篇文章里小编给大家分享的是一篇关于python中numpy.empty()函数实例讲解内容,对此有兴趣的朋友们可以学习下。...2021-02-06
- 这篇文章主要介绍了Python 图片转数组,二进制互转操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-09
python-for x in range的用法(注意要点、细节)
这篇文章主要介绍了python-for x in range的用法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-10- 这篇文章主要介绍了Python中的imread()函数用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-16
- 这篇文章主要介绍了python如何实现b站直播自动发送弹幕,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下...2021-02-20
python Matplotlib基础--如何添加文本和标注
这篇文章主要介绍了python Matplotlib基础--如何添加文本和标注,帮助大家更好的利用Matplotlib绘制图表,感兴趣的朋友可以了解下...2021-01-26- 这篇文章主要介绍了Vue基于localStorage存储信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-11-16
- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- 今天小编就为大家分享一篇python 计算方位角实例(根据两点的坐标计算),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 这篇文章主要为大家详细介绍了python实现双色球随机选号,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-05-02
- 在本篇文章里小编给大家整理的是一篇关于python中使用np.delete()的实例方法,对此有兴趣的朋友们可以学习参考下。...2021-02-01
- 这篇文章主要介绍了使用Python的pencolor函数实现渐变色功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-09
- 这篇文章主要介绍了python自动化办公操作PPT的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-05
Python getsizeof()和getsize()区分详解
这篇文章主要介绍了Python getsizeof()和getsize()区分详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-20- 这篇文章主要介绍了PyTorch一小时掌握之迁移学习篇,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-09-08
- 这篇文章主要为大家详细介绍了python实现学生通讯录管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-25
- 这篇文章主要介绍了解决python 两个时间戳相减出现结果错误的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-12