阿里改造后的memcached客户端源码详解
源码分析
memcached本身是一个集中式的内存缓存系统,对于分布式的支持服务端并没有实现,只有通过客户端实现;再者,memcached是基于TCP/UDP进行通信,只要客户端语言支持TCP/UDP即可实现客户端,并且可以根据需要进行功能扩展。memchaced-client-forjava 既是使用java语言实现的客户端,并且实现了自己的功能扩展,下面这张类图描述了其主要类之间的关系。
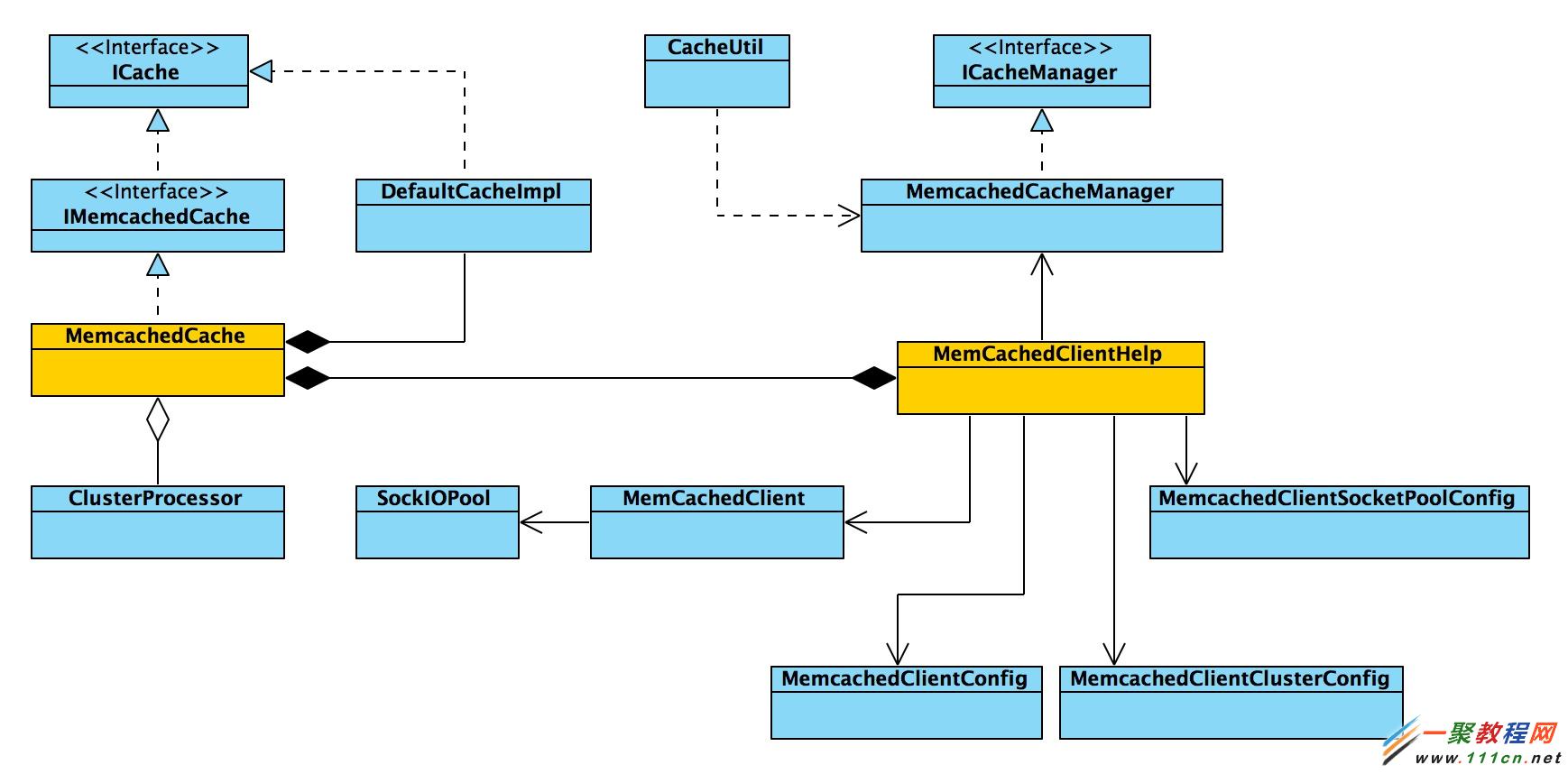
几个重要类的说明:
MemcachedCacheManager: 管理类,负责缓存服务端,客户端,以及相关资源池的初始化工作,获取客户端等等
MemcachedCache:memcached缓存实体类,实现了所有的缓存API,实际上也会调用MemcachedClient进行操作
MemcachedClient:memcached缓存客户端,一个逻辑概念,负责与服务端实例的实际交互,通过调用sockiopool中的socket
SockIOPool:socket连接资源池,负责与memcached服务端进行交互
ClusterProcessor:集群内数据异步操作工具类
客户端可配置化
MemcachedCacheManager是入口,其start方法读取配置文件memcached.xml,初始化各个组建,包括memcached客户端,socket连接池以及集群节点。
memcached客户端是个逻辑概念,并不是和memcached服务端实例一一对应的,可以认为其是一个逻辑环上的某个节点(后面会讲到hash一致性算法时涉及),该配置文件中,可配置一个或多个客户端,每个客户端可配置一个socketPool连接池,如下:
| 代码如下 | 复制代码 |
| <client name="mclient0" compressEnable="true" defaultEncoding="UTF-8" socketpool="pool0”> <errorHandler>com.alisoft.xplatform.asf.cache.memcached.MemcachedErrorHandler</errorHandler> </client> |
|
扩容
socketpool连接池配置的才是真正连接的memcached服务实例,当然,你可以连接多个memcached服务实例,多个实例可以分布在一台或者多台物理机器上。这样,随着实际业务数据量的增加,可以对现有缓存容量进行扩容,只需在servers中增加memcached实例即可,或者增加多个socketpool配置项,配置如下:
| 代码如下 | 复制代码 |
| <socketpool name="pool0" failover="true" initConn="5" minConn="5" maxConn="250" maintSleep="5000" nagle="false" socketTO="3000" aliveCheck="true"> <servers>192.168.1.66:11211,192.168.1.68:11211</servers> </socketpool> |
|
初始化过程
上文提及的MemcachedCacheManager,该类功能包括有初始化各种资源池,获取所有客户端,重新加载配置文件以及集群复制等。我们重点分析方法start,该方法首先加载配置文件,然后初始化资源池,即方法initMemCacheClientPool,该方法中定义了三个资源池,即socket连接资源池socketpool,memcachedcache资源池cachepool,以及由客户端组成的集群资源池clusterpool,这些资源池的数据结构都是线程安全的ConcurrentHashMap,保证了并发效率。将配置信息分别实例化后,再分别放入对应的资源池容器中,socket连接放入socketpool中,memcached客户端放入cachepool中,定义的集群节点放入clusterpool中。
注意,在实例化socket连接池资源socketpool时,会调用每个pool的初始化方法pool.initialize(),来映射memcached实例到HASH环上,以及初始化socket连接。
单点问题
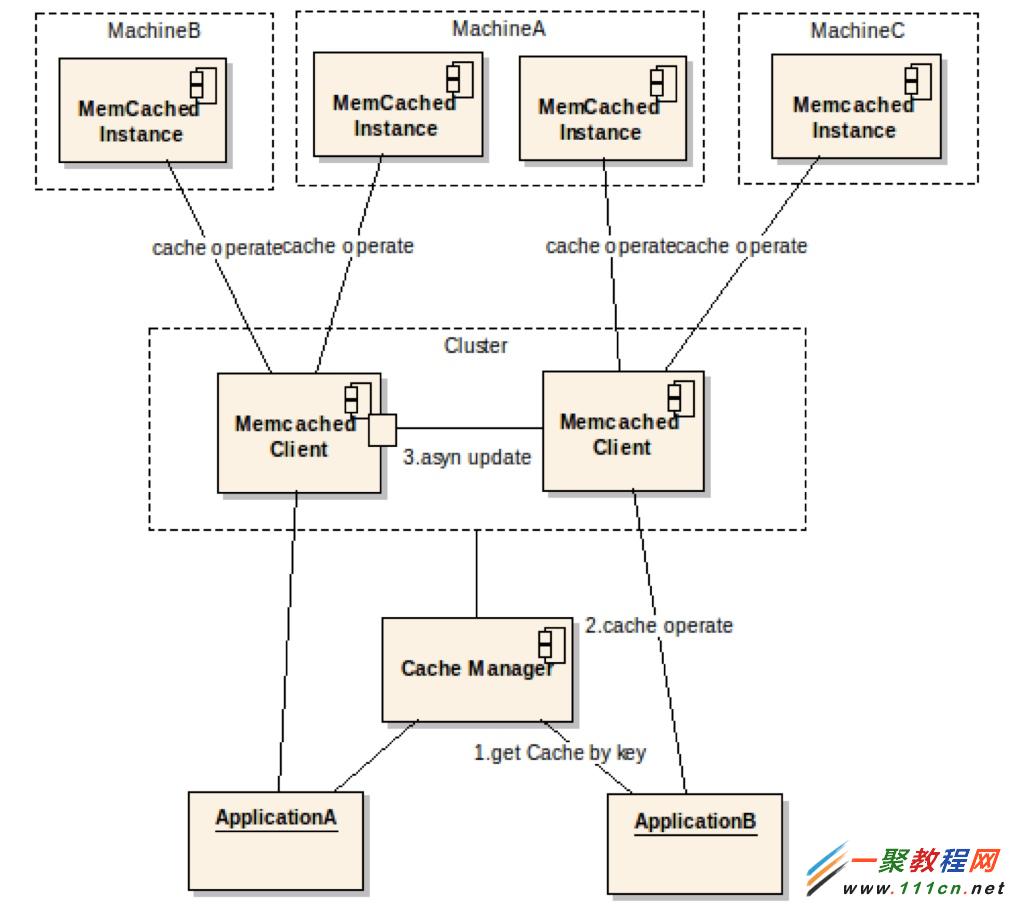
memcached的分布式,解决了容量水平扩容的问题,但是当某个节点失效时,还是会丢失一部分数据,单点故障依然存在,分布式只是解决了数据整体失效问题,而在实际项目中,特别是GAP平台适应的企业级项目中,是不允许数据不一致的,所以对每一份保存的数据都需要进行容灾处理,那么对于定义的每个memcached客户端,都至少增加一个新客户端与其组成一个cluster集群,当更新或者查找数据时,会先定位到该集群中某个节点,如果该节点失效,就去另外一个节点进行操作。在实际项目中,通过合理规划配置cluster和client(memcached客户端),可以最大限度的避免单点故障(当所有client都失效时还会丢失数据)。在配置文件中,集群配置如下:
| 代码如下 | 复制代码 |
<cluster name="cluster1" mode="active"> <memCachedClients>mclient1,mclient2</memCachedClients> </cluster> |
|
下图展现了扩容和单点故障解决方案:
HASH一致性算法
在memcached支持分布式部署场景下,如何获取一个memcached实例?如何平均分配memcached实例的存储?这些需要一个算法来实现,我们选择的是HASH一致性算法,具体就体现在客户端如何获取一个连接memcached服务端的socket上,也就是如何定位memcached实例的问题?算法要求能够根据每次提供的同一个key获得同一个实例。
HASH闭环的初始化
本质上,hash一致性算法是需要实现一个逻辑环,如图所示,环上所有的节点即为一个memcached实例,如何实现?其实是根据每个memcached实例所在的ip地址,将所有的实例映射到hash数值空间中,构成一个闭合的圆环。

HASH环映射的初始化的代码位于SocketIOPool.populateConsistentBuckets方法中,主要代码如下:
| 代码如下 | 复制代码 |
| private void populateConsistentBuckets() { ……... for (int i = 0; i < servers.length; i++) { int thisWeight = 1; if (this.weights != null && this.weights[i] != null) thisWeight = this.weights[i]; double factor = Math .floor(((double) (40 * this.servers.length * thisWeight)) / (double ) this.totalWeight); for (long j = 0; j < factor; j++) { byte[] d = md5.digest((servers[i] + "-" + j).getBytes()); for (int h = 0; h < 4; h++) { // k 的值使用MD5hash算法计算获得 Long k = ((long) (d[3 + h * 4] & 0xFF) << 24) | ((long) (d[2 + h * 4] & 0xFF) << 16) | ((long) (d[1 + h * 4] & 0xFF) << 8) | ((long) (d[0 + h * 4] & 0xFF)); // 用treemap来存储memcached实例所在的ip地址, // 也就是将每个缓存实例所在的ip地址映射到由k组成的hash环上 consistentBuckets.put(k, servers[i]); if (log.isDebugEnabled()) log.debug("++++ added " + servers[i] + " to server bucket"); } } ……... } } |
|
获取socket连接
在实际获取memcahced实例所在服务器的soket时,只要使用基于同一个存储对象的key的MD5Hash算法,就可以获得相同的memcached实例所在的ip地址,也就是可以准确定位到hash环上相同的节点,代码位于SocketIOPool.getSock方法中,主要代码如下:
| 代码如下 | 复制代码 |
public SockIO getSock(String key, Integer hashCode){ …………. // from here on, we are working w/ multiple servers // keep trying different servers until we find one // making sure we only try each server one time Set<String> tryServers = new HashSet<String>(Arrays.asList(servers)); // get initial bucket // 通过key值计算hash值,使用的是基于MD5的算法 long bucket = getBucket(key, hashCode); String server = (this.hashingAlg == CONSISTENT_HASH) ? consistentBuckets .get(bucket) : buckets.g et((int) bucket); …………... } private long getBucket(String key, Integer hashCode) { / / 通过key值计算hash值,使用的是基于MD5的算法 long hc = getHash(key, hashCode); if (this.hashingAlg == CONSISTENT_HASH) { return findPointFor(hc); } else { long bucket = hc % buckets.size(); if (bucket < 0) bucket *= -1; return bucket; } } /** * Gets the first available key equal or above the given one, if none found, * returns the first k in the bucket * * @param k * key * @return */ private Long findPointFor(Long hv) { // this works in java 6, but still want to release support for java5 // Long k = this.consistentBuckets.ceilingKey( hv ); // return ( k == null ) ? this.consistentBuckets.firstKey() : k; // 该consistentBuckets中存储的是HASH结构初始化时,存入的所有memcahced实例节点,也就是整个hash环 // tailMap方法是取出大于等于hv的所有节点,并且是递增有序的 SortedMap<Long, String> tmap = this.consistentBuckets.tailMap(hv); // 如果tmap为空,就默认返回hash环上的第一个值,否则就返回最接近hv值的那个节点 return (tmap.isEmpty()) ? this.consistentBuckets.firstKey() : tmap .firstKey(); } /** * Returns a bucket to check for a given key. * * @param key * String key cache is stored under * @return int bucket */ private long getHash(String key, Integer hashCode) { if (hashCode != null) { if (hashingAlg == CONSISTENT_HASH) return hashCode.longValue() & 0xffffffffL; else return hashCode.longValue(); } else { switch (hashingAlg) { case NATIVE_HASH: return (long) key.hashCode(); case OLD_COMPAT_HASH: return origCompatHashingAlg(key); case NEW_COMPAT_HASH: return newCompatHashingAlg(key); case CONSISTENT_HASH: return md5HashingAlg(key); default: // use the native hash as a default hashingAlg = NATIVE_HASH; return (long) key.hashCode(); } } } /** * Internal private hashing method. * * MD5 based hash algorithm for use in the consistent hashing approach. * * @param key * @return */ private static long md5HashingAlg(String key) { / /通过key值计算hash值,使用的是基于MD5的算法 MessageDigest md5 = MD5.get(); md5.reset(); md5.update(key.getBytes()); byte[] bKey = md5.digest(); long res = ((long) (bKey[3] & 0xFF) << 24) | ((long) (bKey[2] & 0xFF) << 16) | ((long) (bKey[1] & 0xFF) << 8) | (long) (bKey[0] & 0xFF); return res; } |
|
通过以上代码的分析,整个memcahced服务端实例HASH环的初始化,以及数据更新和查找使用的算法都是基于同一种算法,这就保证了通过同一个key获得的memcahced实例为同一个。
socket连接池
这部分单独介绍,请猛烈地戳这里。
容灾、故障转移以及性能
衡量系统的稳定性,很大程度上是对各种异常情况的处理,充分考虑异常情况,以及合理处理异常是对系统设计人员的要求,下面看看在故障处理和容灾方面系统都做了那些工作。
定位memcached实例时,当第一次定位失败,会对所有其他的属于同一个socketpool中的memcahced实例进行定位,找到一个可用的,代码如下:
| 代码如下 | 复制代码 |
// log that we tried // 先删除定位失败的实例 tryServers.remove(server); if (tryServers.isEmpty()) break; // if we failed to get a socket from this server // then we try again by adding an incrementer to the // current key and then rehashing int rehashTries = 0; while (!tryServers.contains(server)) { // 重新计算key值 String newKey = new StringBuilder().append(rehashTries).append(key).toString(); // String.format( "%s%s", rehashTries, key ); if (log.isDebugEnabled()) log.debug("rehashing with: " + newKey); // 去HASH环上定位实例节点 bucket = getBucket(newKey, null); server=(this.hashingAlg == CONSISTENT_HASH) ? consistentBuckets.get(bucket) : buckets.get((int) bucket); rehashTries++; } |
|
查找数据时,当前节点获取不到,会尝试到所在集群中其他的节点查找,成功后,会将数据复制到原先失效的节点中,代码如下:
| 代码如下 | 复制代码 |
public Object get(String key) { Object result = null; boolean isError = false; ……....... if (result == null && helper.hasCluster()) if (isError || helper.getClusterMode().equals(MemcachedClientClusterConfig.CLUSTER_MODE_ACTIVE)) { List<MemCachedClient> caches = helper.getClusterCache(); for(MemCachedClient cache : caches) { if (getCacheClient(key).equals(cache)) continue; try{ try { result = cache.get(key); } catch(MemcachedException ex) { Logger.error(new StringBuilder(helper.getCacheName()) .append(" cluster get error"),ex); continue; } //仅仅判断另一台备份机器,不多次判断,防止效率低下 if (helper.getClusterMode().equals(MemcachedClientClusterConfig.CLUSTER_MODE_ACTIVE ) && result != null) { Object[] commands = new Object[]{CacheCommand.RECOVER,key,result}; // 加入队列,异步执行复制数据 addCommandToQueue(commands); } break; } catch(Exception e) { Logger.error(new StringBuilder(helper.getCacheName()) .append(" cluster get error"),e); } } } return result; } |
|
更新数据时,异步更新到集群内其他节点,示例代码如下:
| 代码如下 | 复制代码 |
public boolean add(String key, Object value) { boolean result = getCacheClient(key).add(key,value); if (helper.hasCluster()) { Object[] commands = new Object[]{CacheCommand.ADD,key,value}; // 加入队列,异步执行 addCommandToQueue(commands); } return result; } |
|
删除数据时,需要同步执行,如果异步的话,会产生脏数据,代码如下:
| 代码如下 | 复制代码 |
public Object remove(String key) { Object result = getCacheClient(key).delete(key); //异步删除由于集群会导致无法被删除,因此需要一次性全部清除 if (helper.hasCluster()) { List<MemCachedClient> caches = helper.getClusterCache(); for(MemCachedClient cache : caches) { if (getCacheClient(key).equals(cache)) continue; try { cache.delete(key); } catch(Exception ex) { Logger.error(new StringBuilder(helper.getCacheName()) .append(" cluster remove error"),ex); } } } return result; } |
|
异步执行集群内数据同步,因为不可能每次数据都要同步执行到集群内每个节点,这样会降低系统性能;所以在构造MemcachedCache对象时,会建立一个队列,线程安全的linked阻塞队列LinkedBlockingQueue,将所有需要异步执行的命令放入队列中,异步执行,具体异步执行由ClusterProcessor类负责。
| 代码如下 | 复制代码 |
public MemcachedCache(MemCachedClientHelper helper,int statisticsInterval) { this.helper = helper; dataQueue = new LinkedBlockingQueue<Object[]>(); ……… processor = new ClusterProcessor(dataQueue,helper); processor.setDaemon(true); processor.start(); } |
|
本地缓存的使用是为了降低连接服务端的IO开销,当有些数据变化频率很低时,完全可以放在应用服务器本地,同时可以设置有效时间,直接获取。DefaultCacheImpl类为本地缓存的实现类,在构造MemcachedCache对象时,即初始化。
每次查找数据时,会先查找本地缓存,如果没有再去查缓存,结束后将数据让如本地缓存中,代码如下:
| 代码如下 | 复制代码 |
public Object get(String key, int localTTL) { Object result = null; // 本地缓存中查找 result = localCache.get(key); if (result == null) { result = get(key); if (result != null) { Calendar calendar = Calendar.getInstance(); calendar.add(Calendar.SECOND, localTTL); // 放入本地缓存 localCache.put(key, result,calendar.getTime()); } } return result; } |
|
增加缓存数据时,会删除本地缓存中对应的数据,代码如下:
| 代码如下 | 复制代码 |
public Object put(String key, Object value, Date expiry) { boolean result = getCacheClient(key).set(key,value,expiry); //移除本地缓存的内容 if (result) localCache.remove(key); …….. return value; } |
|
改造部分
据以上分析,我们通过封装,做到了客户端的可配置化,memcached实例的水平扩展,通过集群解决了单点故障问题,并且保证了应用程序只要每次使用相同的数据对象的key值即可获取相同的memcached实例进行操作。但是,为了使缓存的使用对于应用程序来说完全透明,我们对cluster部分进行了再次封装,即把cluster看做一个node,根据cluster名称属性,进行HASH数值空间计算(同样基于MD5算法),映射到一个HASH环上,如下图,。
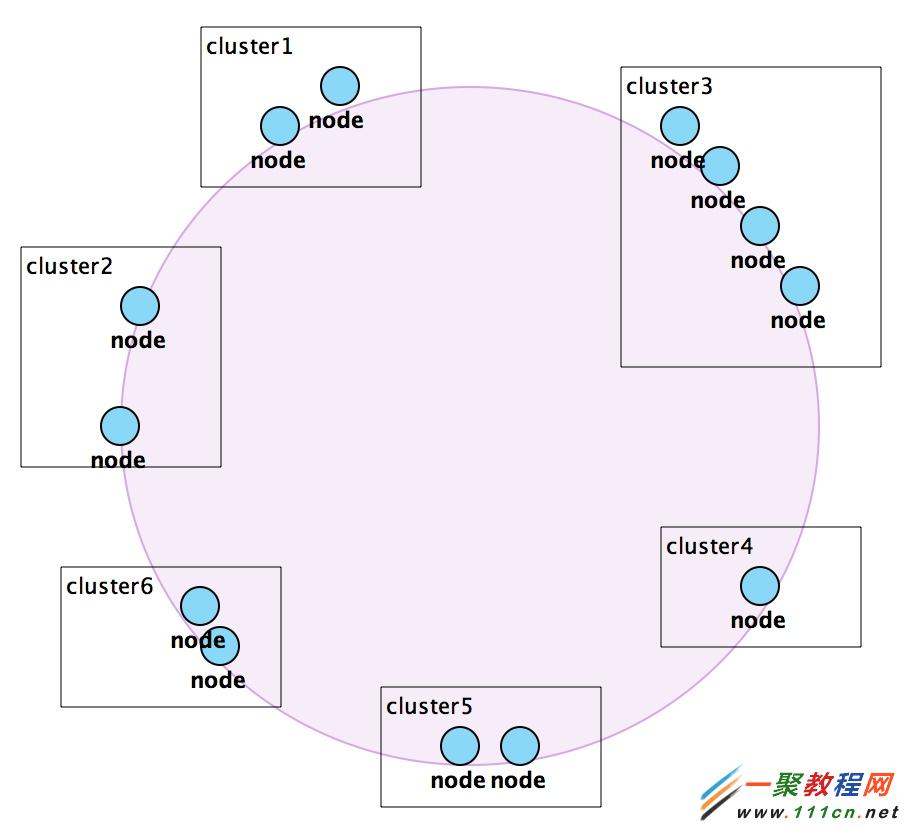
这部分逻辑放在初始化资源池clusterpool时进行(即放在MemcahedCacheManager.initMemCacheClientPool方法中),与上文中所描述的memcached实例HASH环映射的逻辑一致,部分代码如下:
| 代码如下 | 复制代码 |
| //populate cluster node to hash consistent Buckets MessageDigest md5 = MD5.get(); // 使用cluster的名称计算HASH数值空间 byte[] d = md5.digest((node.getName()).getBytes()); for (int h = 0; h < 4; h++) { Long k = ((long) (d[3 + h * 4] & 0xFF) << 24) | ((long) (d[2 + h * 4] & 0xFF) << 16) | ((long) (d[1 + h * 4] & 0xFF) << 8) | ((long) (d[0 + h * 4] & 0xFF)); consistentClusterBuckets.put(k, node.getName()); if (log.isDebugEnabled()) log.debug("++++ added " + node.getName() + " to cluster bucket"); } |
|
在进行缓存操作时,仍然使用数据对象的key值获取到某个cluster节点,然后再使用取余算法(这种算法也是经常用到的分布式定位算法,但是有局限性,即随着节点数的增减,定位越来越不准确),拿到cluster中的某个节点,在进行缓存的操作;定位hash环上cluster节点的逻辑也与上文一样,这里不在赘述。部分定位cluster中节点的取余算法代码如下:
public IMemcachedCache getCacheClient(String key){
………….
String clusterNode = getClusterNode(key);
MemcachedClientCluster mcc = clusterpool.get(clusterNode);
List<IMemcachedCache> memcachedCachesClients = mcc.getCaches();
//根据取余算法获取集群中的某一个缓存节点
if (!memcachedCachesClients.isEmpty())
{
long keyhash = key.hashCode();
int index = (int)keyhash % memcachedCachesClients.size();
if (index < 0 )
index *= -1;
return memcachedCachesClients.get(index);
}
return null;
}
这样,对于应用来说,配置好资源池以后,无需关心那个集群或者客户端节点,直接通过MemcachedCacheManager获取到某个memcachedcache,然后进行缓存操作即可。
最后,使用GAP平台分布式缓存组件,需要提前做好容量规划,集群和客户端事先配置好;另外,缓存组件没有提供数据持久化功能。 我们可能会很少去考虑用“最佳做法”去开发一个php程序,也许是没有意识到,也许是不知道何为最佳做法。下面是本站整理国外php大师对php开发时的原则。
1. 在合适的时候使用PHP – Rasmus Lerdorf
没有谁比PHP的创建者Rasmus Lerdorf明白PHP用在什么地方是更合理的,他于1995年发布了PHP这门语言,从那时起,PHP就像燎原之火,烧遍了整个开发阵营,改变了互联网的世界。可是,Rasmus并不是因此而创建PHP的。PHP是为了解决WEB开发者的实际问题而诞生的。
和许多开源项目一样,PHP变得流行,流行的动机并不能用正常的哲学来进行解释,甚至流行得有些孤芳自赏。它完全可以作为一个案例,一个解决各种Web问题的工具需求所引起的案例,因此当PHP刚出现的时候,这种工具需求全部聚焦到PHP的身上。
但是,你不能奢望PHP可以解决所有问题。Lerdorf是第一个承认PHP只是一种工具的人,并且PHP也有很多力所不能及的情况。
根据工作的不同来选择合适的工具。我跑了很多家公司,为了说服他们部署和使用PHP,但是这并不意味着PHP对所有问题都适用。它只是可以一个解决大部分问题的front-end脚步语言。
作为一个web开发者,尝试用PHP解决所有问题是不科学的,同时也会浪费你的时间。当PHP玩不转的时候,不要犹豫,试用一下其他的语言吧。
2. 使用多表存储提高规模伸缩性 – Matt Mullenweg
没有人愿意质疑Matt Mullenweg在PHP方面的权威性,他开发了这个星球上最流行的blog系统,(依靠一个强大的社区力量支持): WordPress. 创建Wordpress以后,Matt和他的团队启动了WordPress.com平台,一个基于WordPress MU的免费blog站点。现在,Wordpress.com已经拥有大约400万用户, 这些用户每天提供超过 140,000篇的日志。
如果有人知道如何让网站的规模伸缩自如,这个人一定是Matt Mullenweg。2006年的时候 Matt对Wordpress的数据结构进行了前瞻性的改进,并且解释了为什么Wordpress MU对每个blog使用独立的MYSQL表格, 而不是把所有的blog数据都塞进一个巨大的表格。
我们测试过这个方法,但是发现如果要扩展它的伸缩性,代价太高。如果用一个整体的数据结构,在大流量面前,你将会面临服务器硬件的问题。在MU里面。用户们都被分布到独立的表格当中,并且可以轻易地组织起来。举个例子,WordPress.com把用户的数据分散存储到4096个数据库中,这些数据库可以分散大规模的数据访问,实现流量和压力分流。
数据表的可迁移性让代码(blog)可以运行得更快,并且让系统具备更强的伸缩性。依靠强大的缓存策略和灵活的数据库运用策略, Matt向人们展示了时下最流行的Facebook和Wordpress.com都可以在PHP下稳定运行,并且处理惊人的访问量。
3. 千万不要相信用户 – Dave Child
Dave Child是Added Bytes (previously ilovejackdaniels.com) 网站的核心人物,这个网站以他出色的《cheat sheets for many programming languages》而闻名。 Dave为很多英国的公司服务,并且已经在编程世界里树立起相当的权威。
Dave为PHP开发者提供了很多深谋远虑的建议,并总结成了《writing secure code in PHP》:千万不要相信你的用户,他们甚至可能会伤害你。
有一条web开发的基本原则,我重复多少遍都觉得不够,那就是:千万不要相信你的用户,同时要假设你网站中的每个数据单元都是从用户那里收集来的恶意代码。很多时候,你必须用JAVAscript在客户端检验表单提交过来的内容, 如果你习惯了如此,那么,这是一个好习惯。如果安全性对你来说很重要,这就是最重要最需要学习的原则。
Dave目前正致力于为它的《Writing Secure PHP》系列书籍整理实例,书的最后他说:
最后,变得偏执一点吧。除非你认为你的站点永远不会受到攻击,否则就正视所有的问题,当问题真正发生的时候,你的情况会变得很糟。你需要把每个用户都看成会带来一场攻防站的黑客,想尽一切办法来保护站点的安全,同时想好相应问题的解决方案。
4. 多使用PHP缓存 – Ben Balbo
Ben Balbo开发了Site Point,一个为developers和designers提供指导的网站。他是墨尔本PHP开发和开源俱乐部的成员, 因此他对PHP有一定的了解,同时对PHP caching有一定的想法和经验。
如果你拥有一个访问量很大,但更新并不频繁的站点(比如blog,基于某种CMS),或许它需要进行一些改造,这些改造不会花费太多的时间,但是对性能有突出的贡献。 如果要为一个复杂/更新频率很快的站点建立缓存机制,过程可能会很曲折,但是好处也是显而易见的。
PHP缓存技术有很多种,Ben为我们推荐了如下一些:
缓存函数的运行结果
设置过期时间
缓存IE下载的文件
模板缓存技术
Cache_Lite
由于PHP作为动态语言的特性,缓存机制对于更新频率并不快的站点来说非常重要。
5. 使用IDE, Templates和Snippets加速PHP开发 – Chad Kieffer
当Chad Kieffer从UI设计和数据库优化的工作中抽身出来的时候,他会在他的博客2 tablespoons上分享很多技术经验。由于Chad多方面的全面发展,他经常可以发现其他程序员不能发现的问题,并形成相关经验,尤其是他开发网站的方法。他参与了网站开发的各个环节,因此他的建议对于提高网站开发的大局观非常有用。
Chad认为使用Eclipse PDT(Eclipse’s PHP development package) 这样的IDE,同时使用一些模板技术和开源项目可以有效地提高PHP的开发速度。
紧凑的计划,长长的to do lists以及deadlines让开发人员非常苦闷。不过有些功能,比如Eclipse Templates,可以有效减少编码的时间和出错的几率。
通常来说,任何项目都可以自动化,自动化程度越高, 你完成项目的时间就越短。花时间来开发使用频率很高的框架和模板,将会节省你以后更多时间。同时,使用像Eclipse and the PDT package这样的IDE,你会发现效率得到明显提高,IDE可以自动闭合,补全分号并且可以在本地debug。
6. 利用好PHP的过滤函数 – Joey Sochacki
或许Joey Sochacki并不像Matt Mullenweg那样有名 ,但他也是一个经验丰富的开发者,并且通过他的博客Devolio分享了很多技术经验
Joey发现在编写php代码的过程中有很多地方需要进行过滤,但却并没有太多的coder关注php的内置过滤函数。
过滤数据是我们经常需要做的事情,但是很多功能丰富的PHP内置过滤函数却不为人知。使用类似filter_* 的PHP内置函数,我们几乎可以处理所有的过滤任务,包括数据类型验证/URL/email和IP地址验证/特殊字符处理等等。
过滤是一件复杂的事情,但是我相信joey的发现会给你很多启发,让你认识到PHP强大的过滤功能。
7. 使用PHP框架 – Josh Sharp
对于是否应该使用Zend, CakePHP, Code Igniter, 或者 其他PHP框架,一直存在着很多争议,但是在web开发者的心中,他们有自己衡量的标准。
Josh Sharp自己创建了一家提供面包和黄油服务的网站,因此他对于使用PHP框架来开发网站有一定的经验。他认为使用一个PHP框架来进行项目开发(use a PHP framework ),可以有效地节省时间,并且减少出错的几率。为什么?因为他觉得PHP实在是太好上手了。
PHP的易于使用有时候也有缺陷,因为并不严格的语法,经常会导致很多错误代码的诞生。但如果使用一个PHP框架,出错的几率就会大大减少。
PHP框架可以让你的代码结构更加规范,并且节省大量时间。
8. 不要使用PHP框架 – Rasmus Lerdorf
与Josh的观点恰恰相反,PHP的鼻祖Rasmus Lerdorf却认为最好不要使用PHP框架,为什么?因为不基于框架的PHP性能更好。Rasmus在Drupalcon 2008的演讲上,用“Hello World”的例子来对比了一些框架PHP和简单PHP之间的性能,结果显示框架PHP的性能要远远落后。
9. 使用批处理 – Jack D. Herrington
Jack Herrington对PHP世界并不陌生, 并且为大名鼎鼎的IBM developerWorks贡献过超过30篇的专搞, 同时出版过《PHP Hacks》的书,因此他是一个真正的专家。
Herrington推荐使用批处理和Cron来代替那些可以运行在后台的程序脚步,Web用户并不愿意在线 等待你的处理过程,所以有些事情更适合放到后台来处理。
诚然,在某些情况下,这有点大材小用了,但是你可以清楚地看到,使用Cron, MySQL, PHP面向对象的方法以及Pear::DB这些便捷的工具来创建一个批处理工具并不是一件复杂的事情。
Jack认为使用cron, PHP和MySQL在后台处理一些任务,比起多进程的业务逻辑要划算得多。
两种方法我都尝试过,我认为Cron非常符合”Keep It Simple, Stupid” (KISS) 的原则,它让后台处理变得简单。与多进程的业务逻辑相比,它没有内存溢出的风险。你可以创建一个简单的批处理脚本,并且在cron中运行,这个脚本会定时检查是否有任务需要处理,处理完之后就会自动退出,因此你不用担心是否有进程卡壳,或者陷入死循环。
10. 及时启用错误报告 – David Cummings
David Cummings有一个专门提供CMS软件服务的公司 ,并且获得过几次奖 ,他有非常丰富的PHP开发经验。David曾经写过《two PHP tips he wished he’d learned in the beginning》,其中一点就是:及时启用错误报告,这会节省大量的时间。
我告诉人们,最重要的事情就是最大程度地开启PHP的错误报告,为什么?因为PHP可能会隐藏很多小问题:
变量没有预定义
在代码片段中引用了不可用的变量
使用了未定义的常量这些因素看起来并不是什么大事,除非你在使用面向对象的方法编写一些类库。通常,关闭错误报告将可能使你付出更大的成本来维护你的代码。
错误报告可以帮你轻易地找到代码的问题所在,如果错误报告的等级够高,细微的错误都能被立即发现,帮助你节省整体debug的时间。
准备环境
首先安装一个全新的Drupal,推荐使用drush安装,方便迅速。
先要建一个数据库,记住用户和密码。
###进入mysql
mysql -uroot -p
CREATE DATABASE `mydb` CHARACTER SET utf8 COLLATE utf8_general_ci;
GRANT ALL ON `mydb`.* TO `username`@localhost IDENTIFIED BY 'password';
####退出mysql
Drush安装Drupal7:
drush dl drupal-7.x; #--select 用来选择一个版本
drush site-install standard --account-name=admin --account-pass=admin --db-url=mysql://YourMySQLUser:RandomPassword@localhost/YourMySQLDatabase
默认会安装最新版本的drupal7,如果要选择一个版本,请加参数:–select。
安装成功后,再下载一个varnish模块。
#进入drupal目录
drush dl varnish
安装Varnish
我们默认一个CentOS为例,因为CentOS仓库中的Varnish版本较低,要导入一个新的repo,然后,在升级一下yum软件库。
具体参考这个链接:https://www.varnish-cache.org/installation/redhat
####Varnish 4.0:
rpm --nosignature -i https://repo.varnish-cache.org/redhat/varnish-4.0.el6.rpm
yum install varnish
####Varnish 3.0:
###RHEL 5 or a compatible distribution, use:
rpm --nosignature -i https://repo.varnish-cache.org/redhat/varnish-3.0.el5.rpm
yum install varnish
###RHEL 6 and compatible distributions, use:
rpm --nosignature -i https://repo.varnish-cache.org/redhat/varnish-3.0.el6.rpm
yum install varnish
#如果安装的版本不对,请update一下。
#yum update
输入如下命令监测是否安装成功:
$ usr/sbin/varnishd -V
varnishd (varnish-3.0.5 revision 1a89b1f)
Copyright (c) 2006 Verdens Gang AS
Copyright (c) 2006-2011 Varnish Software AS
设置Varnish的VCL
复制如下代码到/etc/varnish/default.vcl里面:
| 代码如下 | 复制代码 |
| backend default { .host = "127.0.0.1"; .port = "80"; } sub vcl_recv { if (req.restarts == 0) { if (req.http.x-forwarded-for) { set req.http.X-Forwarded-For = req.http.X-Forwarded-For + ", " + client.ip; } else { set req.http.X-Forwarded-For = client.ip; } } # Do not cache these paths. if (req.url ~ "^/status.php$" || req.url ~ "^/update.php$" || req.url ~ "^/ooyala/ping$" || req.url ~ "^/admin/build/features" || req.url ~ "^/info/.$" || req.url ~ "^/flag/.$" || req.url ~ "^./ajax/.$" || req.url ~ "^./ahah/.$") { return (pass); } # Pipe these paths directly to Apache for streaming. if (req.url ~ "^/admin/content/backup_migrate/export") { return (pipe); } # Allow the backend to serve up stale content if it is responding slowly. set req.grace = 6h; # Use anonymous, cached pages if all backends are down. if (!req.backend.healthy) { unset req.http.Cookie; } # Always cache the following file types for all users. if (req.url ~ "(?i).(png|gif|jpeg|jpg|ico|swf|css|js|html|htm)(?[wd=.-]+)?$") { unset req.http.Cookie; } # Remove all cookies that Drupal doesn't need to know about. ANY remaining # cookie will cause the request to pass-through to Apache. For the most part # we always set the NO_CACHE cookie after any POST request, disabling the # Varnish cache temporarily. The session cookie allows all authenticated users # to pass through as long as they're logged in. if (req.http.Cookie) { set req.http.Cookie = ";" + req.http.Cookie; set req.http.Cookie = regsuball(req.http.Cookie, "; +", ";"); set req.http.Cookie = regsuball(req.http.Cookie, ";(SESS[a-z0-9]+|NO_CACHE)=", "; 1="); set req.http.Cookie = regsuball(req.http.Cookie, ";[^ ][^;]*", ""); set req.http.Cookie = regsuball(req.http.Cookie, "^[; ]+|[; ]+$", ""); # Remove the "has_js" cookie set req.http.Cookie = regsuball(req.http.Cookie, "has_js=[^;]+(; )?", ""); # Remove the "Drupal.toolbar.collapsed" cookie set req.http.Cookie = regsuball(req.http.Cookie, "Drupal.toolbar.collapsed=[^;]+(; )?", ""); # Remove AdminToolbar cookie for drupal6 set req.http.Cookie = regsuball(req.http.Cookie, "DrupalAdminToolbar=[^;]+(; )?", ""); # Remove any Google Analytics based cookies set req.http.Cookie = regsuball(req.http.Cookie, "__utm.=[^;]+(; )?", ""); # Remove the Quant Capital cookies (added by some plugin, all __qca) set req.http.Cookie = regsuball(req.http.Cookie, "__qc.=[^;]+(; )?", ""); if (req.http.Cookie == "") { # If there are no remaining cookies, remove the cookie header. If there # aren't any cookie headers, Varnish's default behavior will be to cache # the page. unset req.http.Cookie; set req.http.X-Varnish-NoCookie = "TRUE"; } else { # If there is any cookies left (a session or NO_CACHE cookie), do not # cache the page. Pass it on to Apache directly. set req.http.X-Varnish-NoCookie = "FALSE"; set req.http.X-Varnish-CookieData = req.http.Cookie; return (pass); } } # Handle compression correctly. Different browsers send different # "Accept-Encoding" headers, even though they mostly all support the same # compression mechanisms. By consolidating these compression headers into # a consistent format, we can reduce the size of the cache and get more hits. # @see: http:// varnish.projects.linpro.no/wiki/FAQ/Compression if (req.http.Accept-Encoding) { if (req.http.Accept-Encoding ~ "gzip") { # If the browser supports it, we'll use gzip. set req.http.Accept-Encoding = "gzip"; } else if (req.http.Accept-Encoding ~ "deflate") { # Next, try deflate if it is supported. set req.http.Accept-Encoding = "deflate"; } else { # Unknown algorithm. Remove it and send unencoded. unset req.http.Accept-Encoding; } } if (req.request != "GET" && req.request != "HEAD" && req.request != "PUT" && req.request != "POST" && req.request != "TRACE" && req.request != "OPTIONS" && req.request != "DELETE") { /* Non-RFC2616 or CONNECT which is weird. */ return (pipe); } if (req.request != "GET" && req.request != "HEAD") { /* We only deal with GET and HEAD by default */ return (pass); } ## Unset Authorization header if it has the correct details... #if (req.http.Authorization == "Basic <hash>") { # unset req.http.Authorization; #} if (req.http.Authorization || req.http.Cookie) { /* Not cacheable by default */ return (pass); } return (lookup); } sub vcl_pipe { # Note that only the first request to the backend will have # X-Forwarded-For set. If you use X-Forwarded-For and want to # have it set for all requests, make sure to have: set bereq.http.connection = "close"; # here. It is not set by default as it might break some broken web # applications, like IIS with NTLM authentication. } # Routine used to determine the cache key if storing/retrieving a cached page. sub vcl_hash { if (req.http.X-Forwarded-Proto == "https") { hash_data(req.http.X-Forwarded-Proto); } } sub vcl_hit { if (req.request == "PURGE") { purge; error 200 "Purged."; } } sub vcl_miss { if (req.request == "PURGE") { purge; error 200 "Purged."; } } # Code determining what to do when serving items from the Apache servers. sub vcl_fetch { set beresp.http.X-Varnish-CookieData = beresp.http.set-cookie; # Don't allow static files to set cookies. if (req.url ~ "(?i).(png|gif|jpeg|jpg|ico|swf|css|js)(?[a-z0-9]+)?$") { # beresp == Back-end response from the web server. unset beresp.http.set-cookie; } else if (beresp.http.Cache-Control) { unset beresp.http.Expires; } if (beresp.status == 301) { set beresp.ttl = 1h; return(deliver); } ## Doesn't seem to work as expected #if (beresp.status == 500) { # set beresp.saintmode = 10s; # return(restart); #} # Allow items to be stale if needed. set beresp.grace = 1h; } # Set a header to track a cache HIT/MISS. sub vcl_deliver { if (obj.hits > 0) { set resp.http.X-Varnish-Cache = "HIT"; } else { set resp.http.X-Varnish-Cache = "MISS"; } } # In the event of an error, show friendlier messages. sub vcl_error { set obj.http.Content-Type = "text/html; charset=utf-8"; set obj.http.Retry-After = "5"; synthetic {" <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html> <head> <title>"} + obj.status + " " + obj.response + {"</title> </head> <body> <h1>Error "} + obj.status + " " + obj.response + {"</h1> <p>"} + obj.response + {"</p> <h3>Guru Meditation:</h3> <p>XID: "} + req.xid + {"</p> <hr> <p>Varnish cache server</p> </body> </html> "}; return (deliver); } |
|
配置完成之后,启动Varnish。
测试效果
打开浏览器,输入druapl7的地址,先看Drupal7是否正常,然后加上端口号。
比如我们的测试地址是:http://drupal7.111cn.net
那么再用浏览器打开varnish的地址,如下:http://drupal7.111cn.net:6081/
测试结果,两边都正常就表示drupal和varnish都工作正常。
让Varnish缓存Drupal页面
用Firebug查看varnish的请求,如果看到http头里面有X-Varnish的标记表示varnish已经起作用,这时候我们要判断varnish是否缓存了页面。
如何判断:X-Varnish后面有一个数字,表示不是缓存,X-Varnish后面有两个数字,表示缓存成功。
到这里,我们会发现所有的varnish都没有缓存命中,那么问题来了。。。(挖掘机不会出现)
如何让varnish缓存起作用:
// Tell Drupal it's behind a proxy.
$conf['reverse_proxy'] = TRUE;
// Tell Drupal what addresses the proxy server(s) use.
$conf['reverse_proxy_addresses'] = array('127.0.0.1');
// Bypass Drupal bootstrap for anonymous users so that Drupal sets max-age < 0.
$conf['page_cache_invoke_hooks'] = FALSE;
// Make sure that page cache is enabled.
$conf['cache'] = 1;
$conf['cache_lifetime'] = 0;
$conf['page_cache_maximum_age'] = 21600;
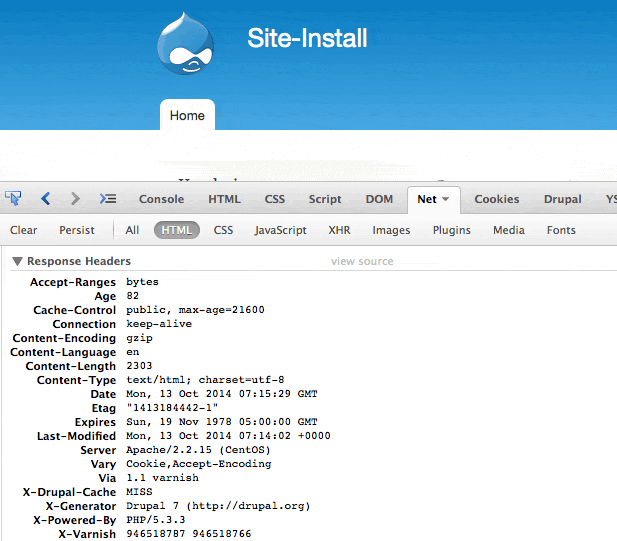
给Drupal的settings.php添加如下内容,然后刷新浏览器,即可看到X-Varnish的数字变成了两个(多刷几次)。
至此,Varnish已经完全可以缓存Drupal的页面了。如下图所示:
那么,Drupal的Varnish模块是做什么用的?
简单来说,Varnish就是通过Drupal的缓存接口,清除varnish的缓存,比如页面过期。
此外,通过Expire模块,可以精确的控制那些页面,过期时间都可以控制,比较方便。
配置Drupal.org的Varnish模块
启用Varnish模块,阅读一下varnish模块的官方说明: https://www.drupal.org/project/varnish
主要是给Drupal的settings.php添加如下两行:
// Add Varnish as the page cache handler.
$conf['cache_backends'] = array('sites/all/modules/varnish/varnish.cache.inc');
$conf['cache_class_cache_page'] = 'VarnishCache';
然后到Drupal设置页面,路径如下: admin/config/development/varnish
例如:
Varnish Control Terminal: 127.0.0.1:6082
Varnish Control Key: 86b2d660-9768-4a13-ab90-4b0736d6a4d1
点击保存,status就会变为绿色。
(注意:Control Key的值在/etc/varnish/secret 文件里面,复制内容即可)
设置完成,那么清空一下Drupal的缓存,就会发现Varnish里面的缓存值就会刷新,实现了即时清空缓存的目的。
+++++到此完成++++++++(更多问题到drupal大学:http://drupal001.net提问哦!)+++++
哦哦,还有一种情况,就是Varnish安装再另外一台服务器上,因为Varnish控制后台默认监听的是本机,因此,如果要刷新另一台反向代理服务器的缓存,就必须修改配置。可选的方法有两个,
其一,让Varnish的管理后台地址使用内网的IP(比如192.168.1.x),一般这种架构都是内网集群,因此监听内网也是比较合理的。
其二,本机使用autossh,把本机的端口6082映射到内网机器上面。
$ autossh -fN -L 6082:localhost:6082
完成
至此,Drupal7 + Varnish的配置已经完成,Drupal和varnish也完全集成。Varnish的缓存总得来说速度大于其他缓存,所以可以代替Boost缓存。
如果要使用Varnish缓存动态内容,还有更多的内容要做,本文就不再增加大家的阅读量了(^_^)。
+++++++++++++++++++++++
最后,顺便多嘴,说一下Apache的RPAF Module。
Varnish默认使用 X-Forwarded-For作为远程IP的地址信息,但是这个不是一个标准的协议,有时候我们还是用PHP里面的 $_SERVER['REMOTE_ADDR']来获得IP。
Apache有一个模块,RPAF的配置文件 rpaf.conf如下,即可获设置正确的IP地址。(具体安装就不多说)
RPAFenable On
RPAFsethostname On
RPAFproxy_ips 127.0.0.1 192.168. 10.0.0.
RPAFheader X-Forwarded-For
Drupal的钩子系统允许和模块交互并改变其他模块的逻辑,甚至是改变Drupal核心逻辑。这是一个非常简单的系统,甚至可以让第三方模块创建自己的钩子。在通常的实践中,有两种类型的钩子你可能想要创建,一种是内容修改类的钩子,一种是拦截类的钩子。修改类的钩子提供了一个标准的方法来修改某个特定对象或变量的内容,典型的是使用 drupal_alter()函数。拦截类的钩子可以让第三方模块在模块执行过程中根据条件做出一些动作。
例1:简单调用
| 代码如下 | 复制代码 |
| <?php // will call all modules implementing hook_hook_name module_invoke_all('hook_name'); ?> |
|
例2:聚合结果
| 代码如下 | 复制代码 |
| <?php $result = array(); foreach (module_implements('hook_name') as $module) { // will call all modules implementing hook_hook_name and // push the results onto the $result array $result[] = module_invoke($module, 'hook_name'); } ?> |
|
例3:使用 drupal_alter() 改变内容
| 代码如下 | 复制代码 |
| <?php $data = array( 'key1' => 'value1', 'key2' => 'value2', ); // will call all modules implementing hook_my_data_alter drupal_alter('my_data', $data); ?> |
|
例4:引用传参,不能使用 module_invoke
| 代码如下 | 复制代码 |
| <?php // @see user_module_invoke() foreach (module_implements('hook_name') as $module) { $function = $module . '_hook_name'; // will call all modules implementing hook_hook_name // and can pass each argument as reference determined // by the function declaration $function($arg1, $arg2); } ?> |
|
php的curl函数
基本例子
| 代码如下 | 复制代码 |
|
??php // 设置你需要抓取的URL // 设置header // 设置cURL 参数,要求结果保存到字符串中还是输出到屏幕上。 // 运行cURL,请求网页 // 关闭URL请求 // 显示获得的数据 |
|
php fopen函数
| 代码如下 | 复制代码 |
|
<? // open a file using http protocol while(!feof($myFile)) // close the file print("<H1>FTP</H1>n"); // open a file using ftp protocol while(!feof($myFile)) // close the file print("<H1>Local</H1>n"); // open a local file while(!feof($myFile)) // close the file |
|
file_get_contents函数
| 代码如下 | 复制代码 |
|
?php file_get_contents('http://www.111cn.net/'); ?> |
|
抓取远程网页源码类
| 代码如下 | 复制代码 |
|
<?php |
|
相关文章
- php语言实现redis的客户端与服务端有一些区别了因为前面介绍过服务端了这里我们来介绍客户端吧,希望文章对各位有帮助。 为了更好的了解redis协议,我们用php来实现...2016-11-25
PHP分布式框架如何使用Memcache同步SESSION教程
本教程主要讲解PHP项目如何用实现memcache分布式,配置使用memcache存储session数据,以及memcache的SESSION数据如何同步。 至于Memcache的安装配置,我们就不讲了,以前...2016-11-25- 这篇文章主要介绍了微信小程序(应用号)开发新闻客户端实例的相关资料,需要的朋友可以参考下...2016-10-25
- 这篇文章主要介绍了在页面中输出当前客户端时间javascript实例代码的相关资料,需要的朋友可以参考下...2016-03-03
- 网上有关蓝牙接收的资料很多,使用起来也很简单,但是我觉得还是有必要把这些知识总结下来,蓝牙开发需要用到一个第三方的库InTheHand.Net.Personal.dll,感兴趣的朋友可以了解下,或许对你有所帮助...2020-06-25
- memche消息队列的原理就是在key上做文章,用以做一个连续的数字加上前缀记录序列化以后消息或者日志。然后通过定时程序将内容落地到文件或者数据库。php实现消息队列的用处比如在做发送邮件时发送大量邮件很费时间的问...2014-05-31
- 这篇文章主要介绍了C#获取客户端相关信息的方法,以实例形式总结了C#获取客户端IP地址、网络连接、硬件信息等相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下...2020-06-25
js根据手机客户端浏览器类型,判断跳转官网/手机网站多个实例代码
这篇文章主要介绍了js根据手机客户端浏览器类型,判断跳转官网手机网站多个实例代码,需要的朋友可以参考下...2016-05-04- 这篇文章主要介绍了spring cloud 配置中心客户端启动遇到的问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-09-25
- 我们知道,DropDownList下拉框是一个服务器控件,有时候,有些朋友为了方便绑定DropDownList下拉框的选项,但又想在DropDownList实现客户端的下拉事件,那该怎么实现呢?...2021-09-22
- 这篇文章主要介绍了c# socket编程实现udp客户端,大家参考使用吧...2020-06-25
- 很多phper不知道如何在Windows下搭建Memcache的开发调试环境,最近个人也在研究Memcache,记录下自己安装搭建的过程。 ...2016-01-27
在Mac OS的PHP环境下安装配置MemCache的全过程解析
这篇文章主要介绍了在Mac OS的PHP环境下安装配置MemCache的全过程解析,MemCache是一套分布式的高速缓存系统,需要的朋友可以参考下...2016-02-18- 如果想别人在看你的主页时,每次都刷新,而不是读取缓存里旧的数据,可以这样来做。 用鼠标右键单击页面,选择“页面属性”,弹出“网页属性”对话框。单击“自...2016-09-20
php memcache和php memcached比较以及问题
php memcache和php memcached是php的memcache分布式的高速缓存系统的两个客户端,php memcache是老客户端,php memcached是功能更加完善的新的代替php memcached的。...2016-11-25- 下面小编就为大家带来一篇完美解决mysql客户端授权后连接失败的问题。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2017-04-03
PHP中加速、缓存扩展的区别和作用详解(eAccelerator、memcached、xcache、APC )
这篇文章主要介绍了PHP中eAccelerator、memcached、xcache、APC 4个加速、缓存扩展的区别的相关资料,非常不错,具有参考借鉴价值,需要的朋友可以参考下...2016-07-25- 这里给大家汇总了使用asp.net实现识别客户端浏览器或操作系统的方法和示例代码,有需要的小伙伴可以参考下。...2021-09-22
- 这篇文章主要介绍了使用cmd根据WSDL网址生成java客户端代码的实现方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-29
- memcache的官方主页:php教程.net/package/memcache">http://pecl.php.net/package/memcache memcached的官方主页:http://pecl.php.net/package/memcached 以下是我安装...2016-11-25