大型web站点缓存策略经验总结
缓存策略
浏览器端的缓存规则
对于浏览器端的缓存来讲,这些规则是在HTTP协议头和HTML页面的Meta标签中定义的。他们分别从新鲜度和校验值两个维度来规定浏览器是否可以直接使用缓存中的副本,还是需要去源服务器获取更新的版本。
新鲜度(过期机制):也就是缓存副本有效期。一个缓存副本必须满足以下条件,浏览器会认为它是有效的,足够新的:
含有完整的过期时间控制头信息(HTTP协议报头),并且仍在有效期内;
浏览器已经使用过这个缓存副本,并且在一个会话中已经检查过新鲜度
满足以上两个情况的一种,浏览器会直接从缓存中获取副本并渲染。
校验值(验证机制):服务器返回资源的时候有时在控制头信息带上这个资源的实体标签Etag(Entity Tag),它可以用来作为浏览器再次请求过程的校验标识。如过发现校验标识不匹配,说明资源已经被修改或过期,浏览器需求重新获取资源内容。
一个重要的概念
缓存命中率:一个缓存的有效性是依照缓存的命中率来度量。它是根据得到数据请求次数与所有请求次数的比率。缓存命中率高意味着有很高的比率数据是从缓存中获取到数据的。
Web缓存的作用
减少网络带宽消耗
降低服务器压力
减少网络延迟,加快页面打开速度
HTTP缓存机制
缓存行为主要由缓存策略决定,而缓存策略由内容拥有者设置。这些策略主要通过特定的HTTP头部来清晰地表达。
当一个用户发起一个静态资源请求的时候,浏览器会通过以下几步来获取资源:
本地缓存阶段:先在本地查找该资源,如果有发现该资源,而且该资源还没有过期,就使用这一个资源,完全不会发送http请求到服务器;
协商缓存阶段:如果在本地缓存找到对应的资源,但是不知道该资源是否过期或者已经过期,则发一个http请求到服务器,然后服务器判断这个请求,如果请求的资源在服务器上没有改动过,则返回304,让浏览器使用本地找到的那个资源;
缓存失败阶段:当服务器发现请求的资源已经修改过,或者这是一个新的请求(在本来没有找到资源),服务器则返回该资源的数据,并且返回200, 当然这个是指找到资源的情况下,如果服务器上没有这个资源,则返回404。
用户操作行为与缓存
浏览器中的操作对缓存的影响:
强制刷新 ? 当按下ctrl+F5来刷新页面的时候, 浏览器将绕过各种缓存(本地缓存和协商缓存), 直接让服务器返回最新的资源;
普通刷新 ? 当按下F5来刷新页面的时候,浏览器将绕过本地缓蹲来发送请求到服务器, 此时, 协商缓存是有效的
回车或转向 ? 当在地址栏上输入回车或者按下跳转按钮的时候, 所有缓存都生效
本地缓存阶段
Expires
指定缓存到期GMT的绝对时间,如果设了max-age,max-age就会覆盖expires。如果expires到期需要重新请求。
Cache-Control
Cache-Control:这个是http 1.1中为了弥补 Expires 缺陷新加入的。
对已缓存的内容进行控制:
Cache-control: public表示缓存的版本可以被代理服务器或者其他中间服务器识别。
Cache-control: private意味着这个文件对不同的用户是不同的。只有用户自己的浏览器能够进行缓存,公共的代理服务器不允许缓存。
Cache-control: no-cache意味着文件的内容不应当被缓存。这在搜索或者翻页结果中非常有用,因为同样的URL,对应的内容会发生变化。
其他相关控制字段:
max-age: 指定缓存过期的相对时间秒数,max-ag=0或者是负值,浏览器会在对应的缓存中把Expires设置为1970-01-01 08:00:00 。
s-maxage: 类似于max-age,只用在共享缓存上,比如proxy.
public: 通常情况下需要http身份验证的情况,响应是不可cahce的,加上public可以使它被cache。
no-cache: 强制浏览器在使用cache拷贝之前先提交一个http请求到源服务器进行确认。这对身份验证来说是非常有用的,能比较好的遵守 (可以结合public进行考虑)。它对维持一个资源总是最新的也很有用,与此同时还不完全丧失cache带来的好处),因为它在本地是有拷贝的,但是在用之前都进行了确认,这样http请求并未减少,但可能会减少一个响应体。
no-store: 告诉浏览器在任何情况下都不要进行cache,不在本地保留拷贝。
must-revalidate: 强制浏览器严格遵守你设置的cache规则。
proxy-revalidate: 强制proxy严格遵守你设置的cache规则。
用法举例: Cache-Control: max-age=3600, must-revalidate
cache:使用本地缓存,不发生请求。
协商缓存阶段
Last-Modified & if-modified-since
Last-Modified与If-Modified-Since是一对报文头,属于http 1.0。
last-modified是WEB服务器认为对象的最后修改时间,比如文件的最后修改时间,动态页面的最后产生时间。
ETag & If-None-Match
ETag与If-None-Match是一对报文,属于http 1.1。
ETag可以用来解决这种问题。ETag是一个文件的唯一标志符。就像一个哈希或者指纹,每个文件都有一个单独的标志,只要这个文件发生了改变,这个标志就会发生变化。
ETag机制类似于乐观锁机制,如果请求报文的ETag与服务器的不一致,则表示该资源已经被修改过来,需要发最新的内容给浏览器。
同时使用这两个报文头,在完全匹配If-Modified-Since和If-None-Match即检查完修改时间和Etag之后,如都与服务器的相符,服务器返回304,否则,发送最新内容给浏览器。
Etag/lastModified过程如下:
1.客户端请求一个页面(A)。
2.服务器返回页面A,并在给A加上一个Last-Modified/ETag。
3.客户端展现该页面,并将页面连同Last-Modified/ETag一起缓存。
4.客户再次请求页面A,并将上次请求时服务器返回的Last-Modified/ETag一起传递给服务器。
5.服务器检查该Last-Modified或ETag,并判断出该页面自上次客户端请求之后还未被修改,直接返回响应304和一个空的响应体。
304:通过If-Modified-Since If-Match判断资源是否修改,如未修改则返回304,发生了一次请求,但请求内容长度为0,节省了带宽。 如果有多台负载均衡的服务器,不同服务器计算出的Etag可能不同,这样就会造成资源的重复加载。
Etag 主要为了解决 Last-Modified 无法解决的一些问题:
1、一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
2、某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
3、某些服务器不能精确的得到文件的最后修改时间。
其他标签
Content-Length:尽管并没有在缓存中明确涉及,Content-Length头部在设置缓存策略时很重要。某些软件如果不提前获知内容的大小以留出足够空间,则会拒绝缓存该内容。
Vary:缓存系统通常使用请求的主机和路径作为存储该资源的键。当判断一个请求是否是请求同样内容时,Vary头部可以被用来提醒缓存系统需要注意另一个附加头部。它通常被用来告诉缓存系统同样注意Accept-Encoding头部,以便缓存系统能够区分压缩和未压缩的内容。
服务器端缓存
CDN缓存
CDN缓存,也叫网关缓存、反向代理缓存。浏览器先向CDN网关发起WEB请求,网关服务器后面对应着一台或多台负载均衡源服务器,会根据它们的负载请求,动态地请求转发到合适的源服务器上。
CDN缓存策略
CDN边缘节点缓存策略因服务商不同而不同,但一般都会遵循http标准协议,通过http响应头中的Cache-control: max-age的字段来设置CDN边缘节点数据缓存时间。
当客户端向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向源站发出回源请求(back to the source request),从源站拉取最新数据,更新本地缓存,并将最新数据返回给客户端。
CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理。
CDN缓存时间会对“回源率”产生直接的影响。若CDN缓存时间较短,CDN边缘节点上的数据会经常失效,导致频繁回源,增加了源站的负载,同时也增大的访问延时;若CDN缓存时间太长,会带来数据更新时间慢的问题。开发者需要增对特定的业务,来做特定的数据缓存时间管理。
CDN缓存刷新CDN边缘节点对开发者是透明的,相比于浏览器Ctrl+F5的强制刷新来使浏览器本地缓存失效,开发者可以通过CDN服务商提供的“刷新缓存”接口来达到清理CDN边缘节点缓存的目的。这样开发者在更新数据后,可以使用“刷新缓存”功能来强制CDN节点上的数据缓存过期,保证客户端在访问时,拉取到最新的数据。
CDN的优势
CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;
大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源站的负载。
CDN缓存的缺点
当网站更新时,如果CDN节点上数据没有及时更新,即便用户再浏览器使用Ctrl +F5的方式使浏览器端的缓存失效,也会因为CDN边缘节点没有同步最新数据而导致用户访问异常。
Combo服务
Combo服务,也就是我们在最终拼接生成页面资源引用的时候,并不是生成多个独立的link标签,而是将资源地址拼接成一个url路径,请求一种线上的动态资源合并服务,从而实现减少HTTP请求的需求。
/??fle1,file2,file3,...的url请求响应就是动态combo服务提供的,它的原理很简单,就是根据url找到对应的多个文件,合并成一个文件来响应请求,并将其缓存,以加快访问速度。
但它也存在一些缺陷:
浏览器有url长度限制,因此不能无限制的合并资源。
如果用户在网站内有公共资源的两个页面间跳转访问,由于两个页面的combo的url不一样导致用户不能利用浏览器缓存来加快对公共资源的访问速度。如果combo的url中任何一个文件发生改变,都会导致整个url缓存失效,从而导致浏览器缓存利用率降低。
HTML5缓存思路
HTML5离线应用缓存manifest
用户可离线访问你的应用,这对于无法随时保持联网状态的移动终端用户来说尤其重要
用户访问本地的缓存文件,通常意味着更快的访问速度
仅仅加载被修改过的资源,避免同一资源对服务器多次的请求,大大降低了对服务器的访问压力
manifest文件罗列了需要被缓存的文件清单。
CACHE MANIFEST # wanz app v1 # 指明缓存入口 CACHE: index.html style.css images/logo.png scripts/main.js # 以下资源必须在线访问 NETWORK: login.php # 如果index.php无法访问则用404.html代替 FALLBACK: /index.php /404.html
这个过程中有几个问题需要注意:
如果服务器对离线的资源进行了更新,那么必须更新manifest文件之后这些资源才能被浏览器重新下载,如果只是更新了资源而没有更新manifest文件的话,浏览器并不会重新下载资源,也就是说还是使用原来离线存储的资源。
对于manifest文件进行缓存的时候需要十分小心,因为可能出现一种情况就是你对manifest文件进行了更新,但是http的缓存规则告诉浏览器本地缓存的manifest文件还没过期,这个情况下浏览器还是使用原来的manifest文件,所以对于manifest文件最好不要设置缓存。
浏览器在下载manifest文件中的资源的时候,它会一次性下载所有资源,如果某个资源由于某种原因下载失败,那么这次的所有更新就算是失败的,浏览器还是会使用原来的资源。
在更新了资源之后,新的资源需要到下次再打开app才会生效,如果需要资源马上就能生效,那么可以使用window.applicationCache.swapCache()方法来使之生效,出现这种现象的原因是浏览器会先使用离线资源加载页面,然后再去检查manifest是否有更新,所以需要到下次打开页面才能生效。
localStorage
localStorage.fresh = “vfresh.org”; //设置一个键值 var a = localStorage.fresh; //获取键值 //API //清空storage localStorage.clear(); //设置一个键值 localStorage.setItem(“fresh”,“vfresh.org”); //获取一个键值 localStorage.getItem(“fresh”); //return “vfresh.org” //获取指定下标的键的名称(如同Array) localStorage.key(0); //return “fresh” //删除一个键值 localStorage.removeItem(“fresh”);
与sessionStroage主要的区别是存储时间和作用域。
另外,严格说来localStorage更像是cookie一类的本地数据存储。但在标准缓存之外,开发人员可以用浏览器的一些功能来实现自定义的客户端“缓存”。
构建可缓存站点的建议
来自alloyteam:如何构建可缓存站点
同一个资源保证URL的稳定性
给Css、js、图片等资源增加HTTP缓存头,并强制入口Html不被缓存
减少对Cookie的依赖
减少对HTTPS加密协议的使用
多用Get方式请求动态Cgi
动态CGI也是可以被缓存

那么本文所探讨的伪原创又是什么类型呢?从本质上来说,伪原创实际上是对别人文章的一种再加工,如果加工非常出色,完全能够将这些伪原创文章当成高质量的原创文章使用,并能够给用户带来更多的帮助,但是做好这样的伪原创文章显然并不容易,具体可以从下面几个方面着手。
第一,伪原创需要将文字进行全部科学化的加工。这极为关键,事实上我们知道天下文章一大抄,就看你抄的有没有水平,李白曾经仿造崔颢的《黄鹤楼》写了一篇《登金陵凤凰台》就是在伪原创之后的一种再加工,在艺术水平上根本不低于崔颢的作品,甚至还有的专家认为是青出于蓝而胜于蓝。由此可见伪原创并不是简单的抄袭,而是根据原文进行重新构思,写出类似的文章。经过这种科学化加工之后,能够展现出伪原创文章的可读性和高质量属性。这样也有利于伪原创在SEO优化中作用的提升。
第二,伪原创文章可以适当增加一些图片。有些原创的文章更多是从理论上进行分析,这些分析的内容虽然具有一定的质量,对于用户也会起到一定的帮助作用,但是这些过于理论化的分析文字往往会让用户觉得比较高深,那么用户对于这些知识的掌握就变得较难。此时如果你在伪原创这些内容时,可以对这些具有一定高深文字内容进行重新使用比较容易理解的文字进行写作,然后再配合一定的图片引入一些案例分析,让用户能够对比案例来分析这些内容,这样就能够让用户能够更加简单的掌握内容,而这样的内容也更有利于百度的收录,因为图文并茂的网页内容已经开始受到百度的关注。
第三,可以对原创的内容进行去芜存菁。因为现在网上的内容极为丰富,而且有的内容往往存在着非常??碌南窒螅?芏嘤没г诳赐旰芏辔淖种?笠哺悴磺宄?飧瞿谌莸降资鞘裁匆馑迹?墒侨绻?亩镣瓿赏??峋醯靡欢ǖ挠么Γ?墒钦庋?脑亩料匀环浅@朔咽奔洹6源宋痹?纯梢越?庑??碌奈淖纸?芯?蚧??梢越?锩娴暮诵慕?兄匦率崂恚?馐绷狡?恼碌谋局室庖迕挥惺裁床钜欤?墒嵌杂谟没У淖饔孟匀皇蔷???砗蟮奈痹?茨谌莞?邮艿接没?囗??/p>
从上面高难度加工的伪原创方法来看,这样的伪原创内容的建设显然具有较高的难度,但是这也是伪原创的正确方法,也是发挥伪原创内容价值的核心途径,那些简单的抄袭伪原创不仅不会增加网站的权重,甚至会影响权重,甚至被惩罚。所以作为SEO优化人员,必须要注重科学伪原创,这样才能够起到较佳的伪原创优化效果。
淘宝网发空包是什么?现在大家开店就会要刷等级了,级别越高排名越好了,这样就有人会想到找人刷单了,现在淘宝对于刷单打击比较大,所以为了做到更真实我们会在刷单同时付款并且发快递了,这样就可以逃过淘宝的追查了,那么问题来了空包和单号的区别?空包是什么东西?具体我们来看看。空包是什么?
空包就如同您自己发货一样,您填写地址,快递公司按照您的地址来发货,只是到达终点了是快递员代签收而已,不过签收的名字会是,您填写的收件人名字;
空包和单号的区别
| 各种单号 | 本站空包 |
| 网上的单号无论是所谓的系统导出单号还是其他商城单号都有可能被重复使用 | 用户在下单购买空包后,系统马上打印快递单,并返回快递单号,绝对一单一用 |
| 网上的单号数量不稳定,不一定什么时候都有单 | 本站的空包全国任意指定发货收件区域,寄件无地域限制,随时随地随心发。 |
| 没有底单,遇到降权时只能自认倒霉 | 降权时免费提供真实扫描底单 |
如何刷信誉才能不被查
说一下卖家A的刷单操作过程吧。有如下安全措施,下面这些操作细节.
①、流量入口,所有刷的单,都是通过关键词搜索,进来的。
②、页面停留时间,一般2分钟左右。
③、所有成交记录,在下单之前,都有聊天记录。
④、所有刷单成交的小号,都经过实名认证的小号。
⑤、快递单号。 卖家A本人在广州,所有单号,都是从当地申通快递购买的,然后让对方按照卖家A给的地址拍下,所以,物流信息这块,发货地址、收件地址、收件人姓名、电话,在物流记录里面,都可以匹配上。并且,时间方面,所有的物流记录,都是在客户拍下付款之后。
⑥、发货时间,卖家A一般在客户拍下付款后,2到5个小时之内发货,如果是晚上22点之后拍下的,则第二天上午12点之前点发货。
⑦、刷单时间 间隔,卖家A每天刷的单也不多,一般不超过三单,有时候隔三小时刷一单,有时候间隔5小时刷一单,有时候间隔一小时刷一单,尽量不形成规律性的痕迹。
⑧、收货确认时间,卖家A一般选的是三、四、五天不等,最短三天,最长五天。
⑨、转化率,单品不到1%,店铺整体转化率也不到1%。
⑩、评价,回评时间,这是让卖家A非常疑惑的一个地方,以前由于心急的原因,一般客户评价后,卖家A当时就立刻手动回评。后来,经过卖家A在网上查询,说是,一般刷单,客户评价后,最好不要回评,等15天后,系统自动默认,或者隔天手动分散回评。
淘宝测刷单异常现象的规律
1、支付宝关联。如在同一IP内,同一个电脑中登陆过的两个账号是关联账号,关联账号相互购买会被监控。
2、快递重量检测 。像快递公司查询重量,如你买了一斤的核桃,重量是0.1公斤,就会进行监控。
3、购物地址监控。如一个账号,它是经常购买东西的,但是常常发往不同的地方,而且货物信息不清楚,淘宝就会进行监控。
4、购物不稳定。如账号创建时间极端,但经常都会购买很多东西,收货速度也很快,全好评,淘宝也会进行监控。
5、转换率异常。像一个店铺转换率10%,刷单了后,转换率达到20%左右,淘宝发现其转换率异常,也会被列入监控范围。
以上五个异常现象,进行淘宝刷单的卖家们可要注意了,尽量避免进去这些误区,记得要模仿真实的交易流程噢!
宝贝降权十大禁忌须知
1、虚假销量、信用的宝贝给予三十天的单个宝贝搜索降权同时根据卖家店铺涉嫌虚假交易情节严重程度给予卖家七至九十天的全店宝贝搜索降权。
2、换宝贝降权,降权时间根据作弊的不同严重程度而不同,一般为30天左右,严重的可永久降权或屏蔽。
3、重复铺货式开店,保留其一个主营店铺,其余店铺屏蔽。
4、广告商品降权时间根据作弊的不同严重程度而不同,广告商品修改正确后最早可在5天内结束降权。
5、错放类目和属性降权时间根据作弊的不同严重程度而不同,错放类目和属性的商品调整正确后最早可在5天内结束降权。
6、标题滥用关键词降权时间根据作弊的不同严重程度而不同,标题滥用的商品修改正确后最早可在5天内结束降权。
7、SKU作弊降权时间根据作弊的不同严重程度而不同,SKU作弊的商品修改正确后最早可在5天内结束降权。
8、价格不符降权时间根据作弊的不同严重程度而不同,价格严重不符的商品调整正确后最早可在5天内结束降权。
9、邮费不符降权时间根据作弊的不同严重程度而不同,邮费、价格严重不符的商品调整正确后最早可在5天内结束降权。
10、标题、图片、价格、描述等不一致降权时间根据作弊的不同严重程度而不同,标题、图片、价格、描述等不一致的商品修改正确后最早可在5天内结束降权。
今日头条对于各位做推广的朋友来讲是非常的好的一个推广平台了,今日头条的流量不用说大得很了,今天我们来看看今日头条文章发布方法,这个对新手会有所帮助了。今日头条怎么发文章
1、要在今日头条发信息我们必须先得有一个 今日头条媒体平台的账号了。
这个可以百度搜索或进入到 今日头条官网 如下图所示。

2、有了账号了,我们只要登录自己的帐号。
3、然后我们再打开进入媒体平台就可以了,如下所示。
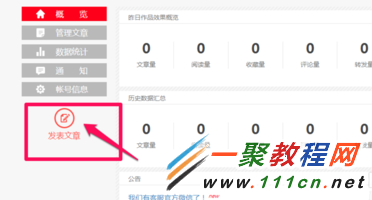
4、然后在后台点击发表文章。
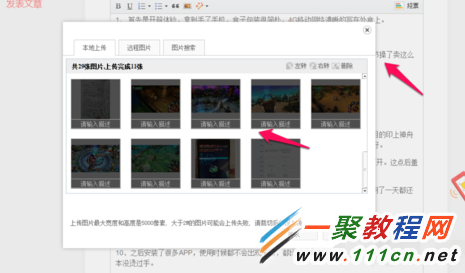
5、在文章发布的编辑器中,我们可以对 编辑文章,上传图片。提交发布,等待审核通过即可发布成功。
注意发的内容不要有外连或违规的内容否则会把号给封了的哦。
网站运营数据分析
要想运营好网站,你首先需要了解你的网站运营状况,比如:网友都是从哪里来访问你的网站?网友最喜欢看的都是什么内容?持续关注哪些页面?还有访问网页的网友们的年龄层次怎样?性别比例怎样?。你或许会问:我怎么知道这些?不要紧,网络巨头们早就发明了一整套网站流量的分析系统,用以定位网站用户进行有针对性的网络广告投放。这方面翘楚就是谷歌公司,事实他们就是靠这项技术的应用获得大量收益而成为全球的it巨头。我们作为案例的这个发行版本也是自带谷歌分析的对接模块。
不过如大家知道的原因,谷歌分析在国内是不好用的。所以我在这里就讲下作为国内替代品的百度分析对接模块,这样更符合“中国特色”。
好先说下 百度分析(Baidu Analytics )对接模块的安装
1、先到百度分析的模块页面下载模块压缩包, 页面地址https://www.drupal.org/project/baidu_analytics
2、然后将模块安装到自己的drupal网站上去,具体操作方法可参考第四课讲到的“如何新增模块和主题”http://www.drupalla.com/node/3137
3、当模块安装好后,就可以将其开启。这样就可以进入管理后台设置百度分析模块了。访问方式从后台进入管理设置再进入系统设置点击进百度分析,对应的路径:admin/config/system/baidu_analytics
4、进入百度分析模块后,就需要将你的百度分析账号对应的id填到Web Property ID的框内。
如果你还没有,就到百度统计的首页注册申请一个帐号就有了(地址:http://tongji.baidu.com/)
5、填好后就可以对百度分析模块进行一些细节上的设置,比如是否只针对某些页面、用户角色、用户行为进行跟踪。甚至可以跟踪分析下载链接和邮件链接被点的情况,还有站内搜索也可以设置监控。此外还提供高级模式,允许你进行百度代码调用的修改。如下图

6、都设置好之后你就可以过段时间后,就能上百度统计的后台看到网站的分析结果了。
网站原创内容的编写
作为一个站长,要想自己的网站有更多人访问,网站就要发布原创内容。现在流行自媒体,作为自媒体最重要的就是要有自己的原创内容,这不仅可以带来流量还有可能额外的商业收益呢。所以网站日常运营中原创内容的发布就是头等大事。
由于网站内容发布流程在第二节课:了解drupal的基本功能 (http://www.drupalla.com/node/2124) 中已经说过了,这里就不复述了。
我在这里说下日常发布原创文章的一些小提示:
1、当你在准备创作一篇原创内容时候,你应该先构想下该文能用的关键词。而这个关键词应该是网络上的热词,怎么找到网络热词呢?你可以上百度风云榜上找到(http://top.baidu.com/buzz?b=396&c=12&fr=topbuzz_b396_c12),使用里面那些高流量低竞争的关键词将会很有利提高网站文章链接的排名。
2、在文章的标题里面置入关键词,也是能够起到很大作用的(怎么能够保证既有关键词,标题又读起来顺就看你的语文水平了)
3、写作文章的字数应该保持在500字以上,最少也别少于300字。并且尽量让关键字多在文章里面出现,此外还要记得给文章打上关键志的标签。
这样你的原创内容就能更易于被搜索引擎发现,并且排到更前的位置,带来更多的流量。
消息信件的设置和使用
电子邮件是一个很老的互联网产品了,但是今日仍是人们常用到的信息产品服务。所以使用消息信件推送信息给用户,很利于提高用户对网站的忠诚度。特别是你可以搞一些特色专题或者活动策划,透过消息信件告知订阅用户,引发关注。
本发行版本已经内置了一个简单消息信件发布模块(simplenews),使你可以发布消息信件给订阅列表里的用户。而无论一般用户或授权用户都能选择不同的邮件列表。
1、创建消息信件
第一步:在后台选择内容管理中的添加内容,再在里面选择简单消息信件(Simplenews newsletter),对应路径:Admin > Content > Add Content。参照下图:
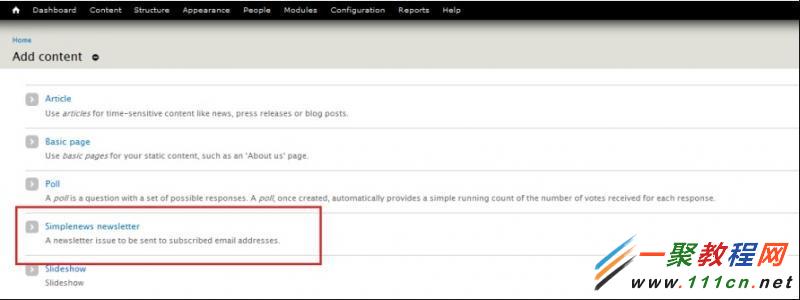
第二步:输入消息信件的所需信息和文字内容然后按保存(save)参照下图:
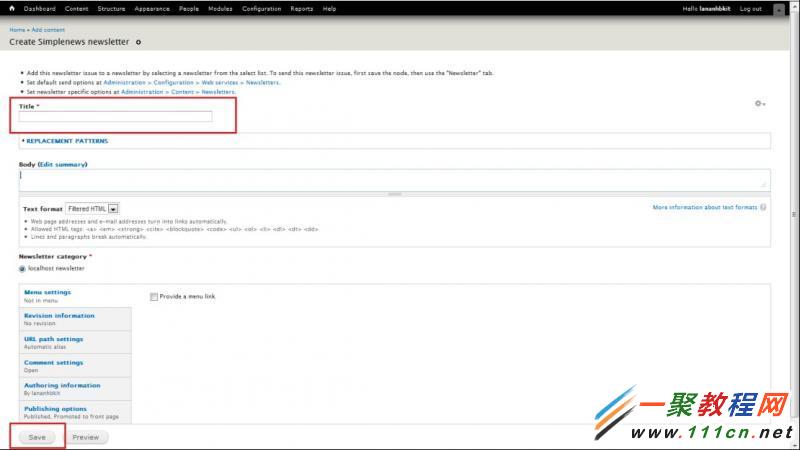
2、管理消息信件
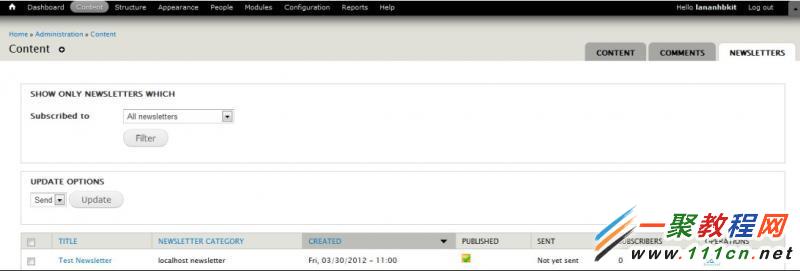
进入管理后台内容管理的消息信件管理,你即可选择操作哪些信件可以寄出。
对应路径:Admin > Content > Newsletters,参照下图。
3、消息信件的系统设置
在管理后台的系统设置里面的网络服务(Web services) 有消息信件的设置,对应路径:
• Administration > Configuration > Web services > Newsletters.
在这个系统设置界面里,你可以对消息信件做详细的系统设置。允许你建立不同的消息邮件类型,并针对不同类型可以设置其标题格式、内容格式,用户订阅方式、确认订阅的步骤、邮件署名等。另外还可以设置邮件服务的运行机制等,参照下图:

评论的管理
网站如果提供评论功能的话,就很容易出现各种垃圾信息了。要怎么消除它们呢?
下面就来说下评论的管理。
第一步 : 进入内容管理里面的评论管理,对应路径: Admin > Content > Comments.
第二步:选择你要处理的一个或多个评论
第三步:从上面的下拉框里面选择发布或者是不发布
第四步:按下更新(update)
参照下图

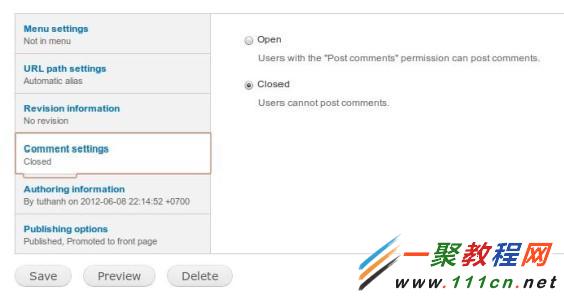
2、不同内容的评论设置
你或许希望某个内容不要有评论功能,比如你的网站简介页面。
那你可以这样做
第一步:选择内容管理里面你要设置的内容文章点编辑(edit)。对应路径:Admin > Content > Edit
参照下图
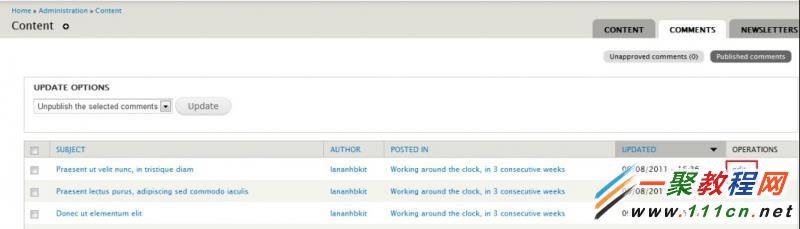
第二步:你可以发现文章底部的属性设置有个评论设置。
你可以点击打开或者关闭该文章的评论功能,选好后点保存 参照下图:
相关文章
- 这篇文章主要介绍了python如何实现b站直播自动发送弹幕,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下...2021-02-20
- 这篇文章主要介绍了c#自带缓存使用方法,包括获取数据缓存、设置数据缓存、移除指定数据缓存等方法,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了IDEA中的clean,清除项目缓存图文教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-09-25
- 这篇文章主要给大家介绍了关于iOS蓝牙设备名称缓存问题的解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-12-08
- 这篇文章主要介绍了AngularJS实现Model缓存的方式,分享了多种AngularJS实现Model缓存的方法,感兴趣的小伙伴们可以参考一下...2016-02-05
- 这篇文章主要介绍了@CacheEvict + redis实现批量删除缓存方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-10-12
- 本文给大家一起探讨nodejs下dns的缓存问题,本文给大家介绍的非常详细,感兴趣的朋友一起看看吧...2016-11-22
- 在本篇文章里小编给大家整理的是一篇关于python删除缓存文件方法,需要的朋友们可以学习下。...2020-07-19
- 这篇文章主要介绍了IIS7、iis7.5中禁止缓存单个静态文件的配置方法,需要的朋友可以参考下...2017-07-06
- 这篇文章主要介绍了vue项目中禁用浏览器缓存配置案例,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下...2021-09-12
- 页面不缓存可以让我们有更新就立即更新出来用户不需要清除浏览器缓存或不停的按f5刷新了,这里整理了解一些关于页面不缓存的方法,具体的如下。 一,js,css,图片文件不...2016-09-20
- 小编给大家带来一篇关于安卓手机缓存怎么清理的问题解答,有需要的可以参考一下   安卓手机怎么清理缓存 android清除程序缓存的方法  一,...2017-07-06
SpringCache 分布式缓存的实现方法(规避redis解锁的问题)
这篇文章主要介绍了SpringCache 分布式缓存的实现方法(规避redis解锁的问题),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-11-20- C#生成sitemap站点地图的方法,需要的朋友可以参考一下...2020-06-25
- PHP缓存的方法有很多种,常用的有memcache, memcached。现在我们来学习一个php缓存集成库phpFastCache,就是开源的,只有一个简单的php文件,就可以支持包括apc, memcache, m...2016-11-25
详解AngularJS中$http缓存以及处理多个$http请求的方法
$http 是 AngularJS 中的一个核心服务,用于读取远程服务器的数据,通过本文给大家介绍AngularJS中$http缓存以及处理多个$http请求的方法,希望的朋友一起学习吧...2016-02-12- 这篇文章主要介绍了如何管理Vue中的缓存页面,帮助大家更好的理解和学习使用vue框架,感兴趣的朋友可以了解下...2021-02-06
- 这篇文章主要介绍了PHP之深入学习Yii2缓存Cache组件详细讲解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下...2021-07-27
- 本文着重介绍如何在XCODE中,通过C++开发在IOS环境下运行的缓存功能。算法基于LRU,最近最少使用,需要的朋友可以参考下...2020-04-25
- 这篇文章主要介绍了phpstudy2020搭建站点的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-10-30