MySQL备份恢复设计思路
背景
首先交代一下背景,由于某些因素的限制,我们公司目前的备份策略采用的是隔天全备的方案,增量备份则使用的是binlog server的方式,那么如何快速恢复就成为了我们需要思考的问题
恢复需求
根据我以往的一些经验来说,通常需要从备份恢复数据的场景有如下几种:
1.被误删库了
2.被误删表了,类型为TRUNCATE或者DROP
3.被误删列了,类型为ALTER ... DROP COLUMN
4.被误删数据了,类型为DELETE或者UPDATE或者REPLACE
5.表空间损坏或出现坏块了
根据场景来说,我们可以大致分为两类:
- 第一类为不可逆恢复,也就是通常的DDL,比如上述的1、2、3、5等场景
- 第二类为可逆的恢复,通常可以利用binlog进行回滚(要求binlog格式为ROW,binlog_image为FULL),也就是对应上述的场景4
对于第二类的恢复需求一般来说都比较容易处理,可以利用binlog回滚工具,例如业界比较著名的有binlog2sql以及MyFlash等,这里暂不赘述,我们重点来讨论第一类需求。
为了达到快速恢复的目的,业界DBA经常会采用的方式就是部署一个延迟从库来解决,我们公司目前 所有的核心DB都部署了延迟从库。但是即便有了延迟从库,假设我们错过了延迟的时间,或者在后续利用延迟从库恢复的时候指定错了位点,导致了误删DDL同样应用到了从库,这个时候我们就没有办法利用延迟从库这根救命稻草了。
全备恢复(异机恢复)
此时,我们只能通过备份来进行数据恢复了。首先我们需要恢复全备,通常来说就是xtrabackup备份的物理备份了。假设你的备份在远程的机器上,那么你可能需要做如下几步动作来进行全备恢复:
- 将备份scp或者rsync到目标实例机器上
- 假设备份文件是压缩的情况下,需要解压
- 解压完成后,需要apply redo log
- 更改文件权限
- 假设你直接将文件拷贝到的目标实例的datadir目录下,那么这一步你就可以直接启动mysqld,假设不是,那么你还需要将数据文件move-back或者copy-back到目标实例的datadir
- 实例启动
增备恢复
到这里,全备已经恢复完成了,接下来需要做的就是增量恢复了。按照我们之前的备份方案,我们需要通过binlog来完成增量数据的恢复。对于binlog恢复,我们通常需要以下几个步骤
- 确定全备对应的binlog位点,也就是需要恢复的起始点
- 解析主库的binlog,确定误删数据的位点,作为我们恢复的终点
- 利用mysqlbinlog —start-position —stop-position+管道的方式,将binlog恢复到目标实例上
binlog恢复的方式有很多种,你可以用的是原先master上的binlog,也可以用binlogserver上的binlog,需要做的就是找到binlog恢复的终点即可。
增备恢复优化
到这里,你可能会觉得,利用binlog恢复有点麻烦。确实是这样的,利用mysqlbinlog命令并没有办法指定恢复到哪个GTID,只能通过解析binlog,找到需要恢复到的GTID对应的pos位点才行,这对于自动化来说实现起来会比较麻烦。另外,如果利用mysqlbinlog命令恢复,属于单线程恢复,假设需要恢复的binlog量比较多的话,那么这个增量恢复的时间可想而知。
那么有什么办法能加速binlog应用呢?这里我们就想到了MySQL5.7的并行复制,如果我们能用到sql thread的并行复制,是不是这个问题就解决了呢?
master上binlog恢复
我们回到全备恢复的位点,我们将新实例作为原先的master的slave,然后恢复到指定的GTID位置就可以了呢?没错,这是一种非常简便又轻松还不容易出错的方式,并且还可以利用并行复制的原理来加速binlog应用的目的。但是这种方式的一个要求就是原先的master最老的binlog包含了我们需要的起始恢复位点,这个很容易想到,所以,这将成为我们首选的恢复方式。
binlogserver上binlog恢复
假设原先master上的binlog已经被purge了,那么我们那需要从binlog上去恢复。有人可能会想到将binlogserver上的binlog拷贝到原先的master上,然后通过修改binlog index来达到注册的目的,实际上这并不可取,具体原因可以见《手动注册binlog文件造成主从异常》。
我们可以采取的方式是什么呢?就是利用binlogserver做成伪装master,然后将从库change上去,其思想就是欺骗slave,让slave的io_thread将缺失的binlog拉取过来,sql_thread并行应用binlog event(我们将在下一节具体演示这种方式)。
优化后的恢复流程
经过优化以后,我们的增备恢复流程就变成了,首先通过master上的binlog进行恢复,如果发现master上的binlog已经被purge了,那么通过binlogserver上的binlog进行恢复,这样一来我认为是比较科学合理的恢复流程。
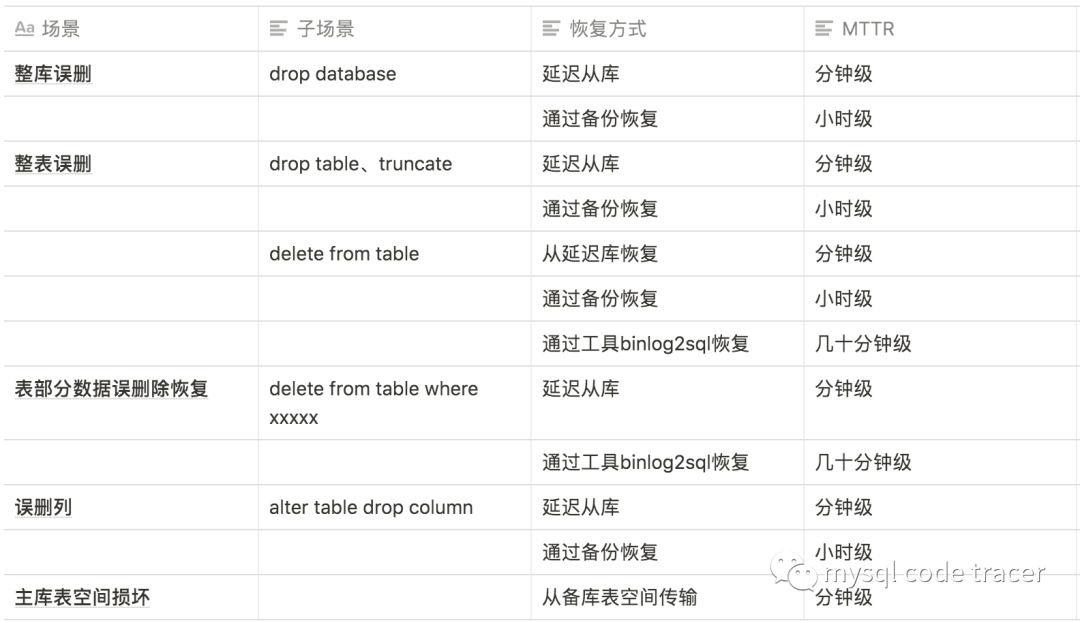
各种恢复方式时效性对比
业务恢复
到这里,我们已经完成了全量+增量的备份数据恢复,这个时候需要同研发确认数据,确认完成以后将对应的表恢复到原先的master,通常采用的方式有:
- mysqldump导出+导入目标实例
- 表空间传输
总结
本节主要介绍了备份恢复的设计流程,在我们没有办法优化全备恢复的情况下,我们通过优化增量备份方式和流程达到缩短恢复时间的目的。并且需要说明的一点是,本节介绍的目前我还没有完全测试,不保证每个点都是正确的,还需要进一步验证,验证通过以后我也会通知大家,并且结合到现有的数据库运维平台,做到自动化恢复
最后还是提醒几点:
- 数据是无形的财产,请广大DBA朋友务必做好备份并做好备份验证
- 如果有条件的情况下,尽量部署延迟从库
- 做好恢复预案,免得恢复的时候手忙脚乱,菊花打紧
- 根据场景选择合适的恢复手段,尽量缩短恢复时间
以上就是MySQL备份恢复设计思路的详细内容,更多关于MySQL备份恢复的资料请关注猪先飞其它相关文章!
相关文章
- 这篇文章主要介绍了MySQL性能监控软件Nagios的安装及配置教程,这里以CentOS操作系统为环境进行演示,需要的朋友可以参考下...2015-12-14
- 新版 Mysql 中加入了对 JSON Document 的支持,可以创建 JSON 类型的字段,并有一套函数支持对JSON的查询、修改等操作,下面就实际体验一下...2016-08-23
- 华为手机怎么恢复已卸载的应用?有时候我们在使用华为手机的时候,想知道卸载的应用怎么恢复,这篇文章主要介绍了华为手机恢复应用教程,需要的朋友可以参考下...2020-06-29
深入研究mysql中的varchar和limit(容易被忽略的知识)
为什么标题要起这个名字呢?commen sence指的是那些大家都应该知道的事情,但往往大家又会会略这些东西,或者对这些东西一知半解,今天我总结下自己在mysql中遇到的一些commen sense类型的问题。 ...2015-03-15- 这篇文章主要介绍了MySQL 字符串拆分操作(含分隔符的字符串截取),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-22
- 一、先说一下为什么要分表:当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。根据个人经验,mysql执行一个sql的过程如下:1...2014-05-31
- 深入解析Linux下MySQL数据库的备份与还原...2013-09-11
- 我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B。...2015-03-15
- 这几天在centos下装mysql,这里记录一下安装的过程,方便以后查阅Mysql5.5.37安装需要cmake,5.6版本开始都需要cmake来编译,5.5以后的版本应该也要装这个。安装cmake复制代码 代码如下: [root@local ~]# wget http://www.cm...2015-03-15
- 宿主机使用网线的时候,客户机在Bridged Adapter模式下,使用Atheros AR8131 PCI-E Gigabit Ethernet Controller上网没问题。 宿主机使用无线的时候,客户机在Bridged Adapter模式下,使用可选项里唯一一个WIFI选项,Microsoft Virtual Wifi Miniport Adapter也无法上网,故弃之。...2013-09-19
- 首先要声明一点,大部分情况下,修改MySQL密码是需要有mysql里的root权限的...2013-09-11
- MySQL命令行导出数据库: 1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录 如我输入的命令行:cd C:/Program Files/MySQL/MySQL Server 4.1/bin (或者直接将windows的环境变量path中添加该目录) ...2013-09-26
- 一、连接Mysql格式: mysql -h主机地址 -u用户名 -p用户密码1、连接到本机上的MYSQL。首先打开DOS窗口,然后进入目录mysql/bin,再键入命令mysql -u root -p,回车后提示你输密码.注意用户名前可以有空格也可以没有空格,但是密...2015-11-08
- Navicat for MySQL注册码用来激活 Navicat for MySQL 软件,只要拥有 Navicat 注册码就能激活相应的 Navicat 产品。这篇文章主要介绍了Navicat for MySQL 11注册码\激活码汇总,需要的朋友可以参考下...2020-11-23
- 这篇文章主要介绍了mysql IS NULL使用索引案例讲解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下...2021-08-14
- 这篇文章主要介绍了基于PostgreSQL和mysql数据类型对比兼容,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-12-25
- 一、准备编译环境,安装所需依赖包yum groupinstall 'Development' -y yum install openssl openssl-devel zlib zlib-devel -y yum install readline-devel pcre-devel ncurses-devel bison-devel cmake -y二、编译安...2015-10-21
Mysql中 show table status 获取表信息的方法
这篇文章主要介绍了Mysql中 show table status 获取表信息的方法的相关资料,需要的朋友可以参考下...2016-03-12- 这篇文章主要为大家分享了20分钟MySQL基础入门教程,快速掌握MySQL基础知识,真正了解MySQL,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2016-12-02
- 一、备份的目的做灾难恢复:对损坏的数据进行恢复和还原需求改变:因需求改变而需要把数据还原到改变以前测试:测试新功能是否可用二、备份需要考虑的问题可以容忍丢失多长时间的数据;恢复数据要在多长时间内完; 恢复的时候...2013-10-04