Mysql join联表及id自增实例解析
join的写法
如果用left join 左边的表一定是驱动表吗?两个表的join包含多个条件的等值匹配,都要写道on还是只把一个写到on,其余写道where部分?
create table a(f1 int, f2 int, index(f1))engine=innodb; create table b(f1 int, f2 int)engine=innodb; insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6); insert into b values(3,3),(4,4),(5,5),(6,6),(7,7),(8,8); select * from a left join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q1*/ select * from a left join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q2*/
执行结果:
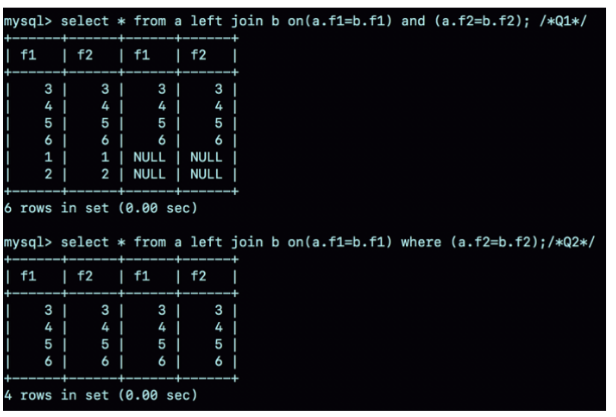
由于表b没有索引,使用的是Block Nexted Loop Join(BNL)算法
- 把表a的内容读入join_buffer中,因为select * ,所以字段f1,f2都被放入
- 顺序扫描b,对于每一行数据,判断join条件是否满足,满足条件的记录,作为结果集的一行,如果有where子句,判断where部分满足条件后再返回。
- 表b扫描完成后,对于没有匹配的表a的行,用null补上,放到结果集中。

Q2语句中,explain结果:

b为驱动表,如果一条语句EXTRA字段什么都没有的话,就是Index Nested_Loop Join算法,因此流程是:
顺序扫描b,每一行用b.f1到a中去查,匹配a.f2=b.f2是否满足,作为结果集返回。
Q1与Q2执行流程的差异是因为优化器基于Q2这个查询语义做了优化:在mysql里,null跟任何值执行等值判断和不等值判断的结果都是null,包括select null = null 也返回null。
在Q2中,where a.f2 = b.f2表示,查询结果里不会包含b.f2是null的行,这样left join语义就是找到两个表里f1 f2对应相同的行,如果a存在而b匹配不到,就放弃。因此优化器把这条语句的left join改写成了join,因为a的f1有索引,就把b作为驱动表,这样可以用NLJ算法,所以在使用left join时,左边的表不一定是驱动表。
如果需要left join的语义,就不能把被驱动表的字段放在where条件里做等值判断或不等值判断,必须写在on里面。
Nested Loop Join的性能问题
BLN算法的执行逻辑
- 将驱动表的数据全部读入join_buffer中,里面是无序数组。
- 顺序遍历被驱动表的所有行,每一行都跟join_buffer做匹配,成功则作为结果集的一部分返回。
Simple Nested Loop Join算法逻辑是:顺序去除驱动表的每一行数据,到被驱动表做全表匹配。
两者差异:
在对被驱动表做全表扫描时,如果数据没有在buffer pool中,需要等待部分数据从磁盘读入。会影响正常业务的buffer pool命中率,而且会对被驱动表做多次访问,更容易将这些数据页放到buffer pool头部。所以BNL算法性能会更好。自增id
mysql中自增id定义了初始值,不停的增长,但是有上限,2^32-1,自增的id用完了会怎么样呢。
表定义的自增值达到上限后,再申请下一个id时,得到的值保持不变。再次插入时会报主键冲突错误。所以在建表时,如果有频繁的增删改时,就应该创建8个字节的bigint unsigned。
innodb 系统自增row_id
如果创建了Innodb表没有指定主键,那么innodb会创建一个不可见的,长度为6个字节的row_id,所有无主键的innodb表,每插入一行数据,都将当前的dict_sys.row_id值作为要插入数据的row_id,然后自增1。
实际上,代码实现时,row_id是一个长度为8字节的无符号长整形,但是innodb在设计时,给row_id只是6个字节的长度,这样写道数据时只放了最后6个字节。所以:
- row_id写入表的范围是0到2^48-1;
- 当达到最大时,如果再有插入数据的行为来申请row_id,拿到以后再去最后6个字节就是0,然后继续循环。
- 再innodb的逻辑里,达到最大后循环,新数据会覆盖已经存在的数据。
从这个角度看,我们应该主动创建自增主键,这样达到上限后,插入数据会报错。数据的可靠性会更加有保障。
XID
redo log 和 binlog相互配合的时候,它们有一个共同的字段就是xid,在mysql中对应事务的。xid最大时2^64次方,用尽只存在理论。
thread_id
系统保存了全局变量thread_id_counter,每新建一个连接,就将thread_id_counter赋值给这个新连接的线程变量。thread_id_counter定义的大小是4个字节,因此到2^32-1就会重置为0,然后继续增加。但是show processlist里不会看到两个相同的thread_id,这是因为mysql设计了一个唯一数组逻辑,给新线程分配thread_id的时候:
do {
new_id= thread_id_counter++;
} while (!thread_ids.insert_unique(new_id).second);
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持猪先飞。
相关文章
- 这篇文章主要介绍了MySQL性能监控软件Nagios的安装及配置教程,这里以CentOS操作系统为环境进行演示,需要的朋友可以参考下...2015-12-14
Spring Cloud 中@FeignClient注解中的contextId属性详解
这篇文章主要介绍了Spring Cloud 中@FeignClient注解中的contextId属性详解,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-09-25- 下面我们来看一篇关于Android子控件超出父控件的范围显示出来方法,希望这篇文章能够帮助到各位朋友,有碰到此问题的朋友可以进来看看哦。 <RelativeLayout xmlns:an...2016-10-02
- 新版 Mysql 中加入了对 JSON Document 的支持,可以创建 JSON 类型的字段,并有一套函数支持对JSON的查询、修改等操作,下面就实际体验一下...2016-08-23
c# WPF中通过双击编辑DataGrid中Cell的示例(附源码)
这篇文章主要介绍了c# WPF中通过双击编辑DataGrid中Cell的示例(附源码),帮助大家更好的理解和学习使用c#,感兴趣的朋友可以了解下...2021-03-03Android开发中findViewById()函数用法与简化
findViewById方法在android开发中是获取页面控件的值了,有没有发现我们一个页面控件多了会反复研究写findViewById呢,下面我们一起来看它的简化方法。 Android中Fin...2016-09-20深入研究mysql中的varchar和limit(容易被忽略的知识)
为什么标题要起这个名字呢?commen sence指的是那些大家都应该知道的事情,但往往大家又会会略这些东西,或者对这些东西一知半解,今天我总结下自己在mysql中遇到的一些commen sense类型的问题。 ...2015-03-15- 如果我们的项目需要做来电及短信的功能,那么我们就得在Android模拟器开发这些功能,本来就来告诉我们如何在Android模拟器上模拟来电及来短信的功能。 在Android模拟...2016-09-20
- 夜神android模拟器如何设置代理呢?对于这个问题其实操作起来是非常的简单,下面小编来为各位详细介绍夜神android模拟器设置代理的方法,希望例子能够帮助到各位。 app...2016-09-20
- 为了增强android应用的用户体验,我们可以在一些Button按钮上自定义动态的设置一些样式,比如交互时改变字体、颜色、背景图等。 今天来看一个通过重写Button来动态实...2016-09-20
- 这篇文章主要介绍了MySQL 字符串拆分操作(含分隔符的字符串截取),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-22
- 如果我们要在Android应用APP中加载html5页面,我们可以使用WebView,本文我们分享两个WebView加载html5页面实例应用。 实例一:WebView加载html5实现炫酷引导页面大多...2016-09-20
- 深入理解Android中View和ViewGroup从组成架构上看,似乎ViewGroup在View之上,View需要继承ViewGroup,但实际上不是这样的。View是基类,ViewGroup是它的子类。本教程我们深...2016-09-20
- 一、先说一下为什么要分表:当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。根据个人经验,mysql执行一个sql的过程如下:1...2014-05-31
- 下面我们来看一篇关于Android自定义WebView网络视频播放控件开发例子,这个文章写得非常的不错下面给各位共享一下吧。 因为业务需要,以下代码均以Youtube网站在线视...2016-10-02
- java开发的Android应用,性能一直是一个大问题,,或许是Java语言本身比较消耗内存。本文我们来谈谈Android 性能优化之MemoryFile文件读写。 Android匿名共享内存对外A...2016-09-20
- TextView默认是横着显示了,今天我们一起来看看Android设置TextView竖着显示如何来实现吧,今天我们就一起来看看操作细节,具体的如下所示。 在开发Android程序的时候,...2016-10-02
- 我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B。...2015-03-15
android.os.BinderProxy cannot be cast to com解决办法
本文章来给大家介绍关于android.os.BinderProxy cannot be cast to com解决办法,希望此文章对各位有帮助呀。 Android在绑定服务的时候出现java.lang.ClassCastExc...2016-09-20- 这几天在centos下装mysql,这里记录一下安装的过程,方便以后查阅Mysql5.5.37安装需要cmake,5.6版本开始都需要cmake来编译,5.5以后的版本应该也要装这个。安装cmake复制代码 代码如下: [root@local ~]# wget http://www.cm...2015-03-15