C#实现百度网站收录和排名查询功能思路及实例
一、前言
偶然一次在vs2012默认的项目文件夹里发现了以前自己做的一个关于SEO的类库,主要是用来查询某个网址的收录次数还有网站的排行数,后来重构了下,今天拿出来写篇文章,说说自己是如何思考的并完成的。
二、问题描述
首先需要考虑的是能够支持哪些搜索引擎的查询,首先是百度,然后是必应、搜狗、搜搜、360。本来想支持Google但是一想不对,根本不好访问的,所以暂时不算在内。而我们实际要做的就是根据一个网址能够检索出这个网址的在各个搜索引擎的收录次数以及在不同关键词下的网址排行,这里出入的只有网址还有若干的关键词,而输出则是该网址在不同搜索引擎下的收录次数以及在各个关键词下的排行数。
但是这里有个问题,就是排行数,如果检索的网址在前100还好,如果排名很后面,那么问题就来了,那样会让用户等待很长时间才能看到结果,但是用户可能只想知道排行前100的具体排名,而那些超过的则只要显示100以后就可以了,而这些就需要我们前期考虑好,这样后面的程序才好做。
三、解决思路
相信很多人都能够想到,就是利用WebClient将将需要的页面下载下来,然后用正则从中获取我们感兴趣的部分,然后利用程序去处理。而关键难度就是在这个正则的编写,首先我们先从简单的开始。
四、收录次数
首先是网站的收录次数,我们可以在百度中输入site:www.cnblogs.com/然后我们就可以看到如下的页面:

而我们所需要的收录次数就是 5,280,000 这段数字,我们接着查看页面元素:

接着我们再观察其他的搜索引擎可以发现都是类似的,所以我们的思路这个时候应该就得出了,最后就是如何组织网址,这部分我们看地址栏?wd=site%3Awww.cnblogs.com%2F这段就知道怎么写了。
稍等这个时候我们可能心急一个一个实现,这样后面我们就没法集中的调用,同时也会影响以后的新增,所以我们要规定一个要实现收录数功能的抽象类,这样就能够在不知晓具体实现的情况统一使用,并且还能够在以后轻松的新增新的搜索引擎,而这种方式属于策略模式(Stategry),下面我们来慢慢分析出这个抽象类的具体内容。
首先每个实现这个抽象类的具体类都应该是对应某个搜索引擎,那么就需要有一个基本网址,同时还要留下占位符,比如根据上面百度的这个我们就得出这样一个字符串
http://www.baidu.com/s?wd=site%3A{0}
其中{0}就是为真正需要检索网址的占位符,获取下载页面的路径是所有具体类都需要的所以我们直接将实现放在抽象类中,比如下面的代码:
/// <summary>
/// 服务提供者
/// </summary>
protected String SearchProvider { get; set; }
/// <summary>
/// 需要检索的网址
/// </summary>
protected String SiteUrl { get; set; }
/// <summary>
/// 搜索服务提供网址
/// </summary>
protected String BaseUrl { get; set; }
/// <summary>
/// 后页面网址
/// </summary>
/// <param name="site">需要查询的网址</param>
/// <returns>拼接后的网址</returns>
protected String GetDownUrl(string site)
{
return string.Format(BaseUrl, HttpUtility.UrlEncode(site));
}
其中SiteUrl和SearchProvider是用来保存检索网址和搜索引擎名称。
上面我们说了将会利用WebClient来下载页面,所以初始化WebClient的工作也在抽象类中完成,尽可能的减少重复代码,而为了防止阻塞当前线程所以我们采用了Async方法。
具体代码如下所示:
/// <summary>
/// 查询在该搜索引擎中的收录次数
/// </summary>
/// <param name="siteurl">网站URL</param>
public void SearchIncludeCount(string siteurl)
{
SiteUrl = siteurl;
WebClient client = new WebClient();
client.Encoding = Encoding.UTF8;
client.DownloadStringCompleted += DownloadStringCompleted;
client.DownloadStringAsync(new Uri(GetDownUrl(siteurl)));
}
/// <summary>
/// 检索收录次数的具体实现
/// 子类必须要实现该方法
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
protected abstract void DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e);
当WebClient完成下载后将会回调DownloadStringCompleted方法,而这个方法的是抽象方法也就意味着具体类必须要实现这个方法。
虽然我们内部的实现是异步的但是对于其他开发者调用这个方法还是同步的,所以我们就需要借助委托因此我们还要新建一个委托类型:
/// <summary>
/// 当完成一个网站的收录查询后回调
/// </summary>
public Action<SiteIncludeCountResult> OnComplatedOneSite { get; set; }
其中SiteIncludeCountResult的结构如下所示:
/// <summary>
/// 用于网站收录中委托的参数
/// </summary>
public class SiteIncludeCountResult
{
/// <summary>
/// 收录次数
/// </summary>
public long IncludeCount { get; set; }
/// <summary>
/// 搜索引擎类型
/// </summary>
public String SearchType { get; set; }
/// <summary>
/// 网站URL
/// </summary>
public String SiteUrl { get; set; }
}
最后还有一个方法用于DownloadStringCompleted完成后回调OnComplatedOneSite委托:
/// <summary>
/// 完成处理后调用该方法将结果返回
/// </summary>
/// <param name="result">网址的收录数结果</param>
protected void SetCompleted(SiteIncludeCountResult result)
{
if (OnComplatedOneSite != null)
OnComplatedOneSite(result);
}
这样我们需要的抽象类就完成了,下面我们就可以开始实现第一个了,通过上面的截图我们可以发现要匹配这段字符串的正则表达式很简单:
百度为您找到相关结果约([\w,]+?)个
最后再将获取的字符串去掉逗号就可以强制转换了,这样结果就出来了,具体实现就像下面这样:
/// <summary>
/// 百度网站收录次数查询
/// </summary>
public class BaiDuSiteIncludeCount : SiteIncludeCountBase
{
public BaiDuSiteIncludeCount()
{
BaseUrl = "http://www.baidu.com/s?wd=site%3A{0}";
SearchProvider = "百度";
}
protected override void DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e)
{
var result = new SiteIncludeCountResult();
result.SiteUrl = SiteUrl;
result.SearchType = SearchProvider;
result.IncludeCount = 0;
Regex reg = new Regex(@"百度为您找到相关结果约([\w,]+?)个", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var matchs = reg.Matches(e.Result);
if (matchs.Count > 0)
{
string count = matchs[0].Groups[1].Value.Replace(",", "");
result.IncludeCount = long.Parse(count);
}
SetCompleted(result);
}
}
以此类推,其他的都是按照这种就可以了,有兴趣的可以下载我的源码查看。
五、关键词排名
我们按照之前的思路,还是要先规定一个抽象类,但是其结构跟上面的抽象类很相似,所以笔者这里直接给出具体的代码:
/// <summary>
/// 实现关键词查询必须继承该类
/// </summary>
public abstract class KeyWordsSeoBase
{
protected String BaseUrl { get; set; }
protected String SearchProvider { get; set; }
protected String GetDownUrl(string keyword, string site, long current)
{
return String.Format(BaseUrl, HttpUtility.UrlEncode(keyword), current);
}
protected void SetCompleted(KeyWordsSeoResult result)
{
if (OnComplatedOneKeyWord != null)
{
OnComplatedOneKeyWord(result);
}
}
/// <summary>
/// 完成一个关键词的查询后回调该委托
/// </summary>
public Action<KeyWordsSeoResult> OnComplatedOneKeyWord { get; set; }
/// <summary>
/// 查询指定关键词和网站在该搜索引擎中的排行
/// 子类需要重写该方法
/// </summary>
/// <param name="keywords">关键词</param>
/// <param name="site">网站URL</param>
public abstract void SearchRanking(IEnumerable<string> keywords, string site,long count);
}
最大的区别在于具体的实现全部集中在SearchRanking中,通过keywords参数可以看出我们会支持多个关键词的查询,最后不同的就是下载路径的组织,因为涉及到翻页所以多了一个参数。
其中KeyWordsSeoResult的结构如下所示:
/// <summary>
/// 用于关键词排行查询的委托参数
/// </summary>
public class KeyWordsSeoResult
{
/// <summary>
/// 搜索引擎类型
/// </summary>
public String SearchType { get; set; }
/// <summary>
/// 关键词
/// </summary>
public String KeyWord { get; set; }
/// <summary>
/// 排行
/// </summary>
public long Ranking { get; set; }
}
废话不多说,我们来看百度的搜索结果页:
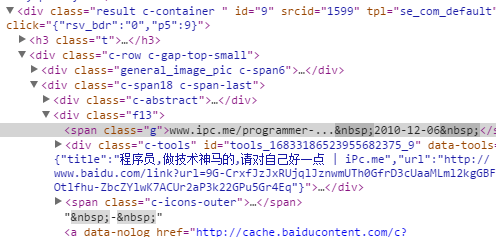
以上是笔者在百度中搜索程序员的排名第九个的html结构,或许你会觉得很简单只要获取div的id以及网址就可以了,但是很多搜索引擎的路径并不是直接的路径,而是会先链到百度然后重定向的,如果非要匹配我们就需要多做一件事就是访问这个路径得到真实的路径,那样就会加大这中间的等待时间,所以笔者采用的是直接截取上图中的<span class=”g”>后面的内容,这样就避免了一次请求。(不知道当初笔者怎么想的,实现的时候并没有采用id那个值而是在内部递增,估计这个id的序号在翻页后会出现问题吧),最后亮出我们神圣的正则表达式:
<span\s+class=""(?:g|c-showurl)"">([^/&]*)
以为这样就大公告成了?错了,在某些结果里面百度会给这个网址加上b标签,而笔者则采用全部赶尽杀绝的方式,利用正则全部删掉(反正又不看页面,只要拿到我想要的就OK了),实现的时候我们可不能直接实现多个关键词的判明,应该是实现一个关键词的,然后循环调用即可了,下面是笔者的单个关键词的实现:
protected KeyWordsSeoResult SearchFunc(string key, string siteurl, long total)
{
var result = new KeyWordsSeoResult();
result.KeyWord = key;
result.Ranking = total + 1;
var reg = new Regex(@"<span\s+class=""(?:g|c-showurl)"">([^/&]*)", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var replace = new Regex("</?b>", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var client = new WebClient();
long current = 0;
long pos = 0;
for (; ; )
{
String url = GetDownUrl(key, siteurl, current);
String downstr = client.DownloadString(url);
downstr = replace.Replace(downstr, "");
var matchs = reg.Matches(downstr);
foreach (Match match in matchs)
{
pos++;
string suburl = match.Groups[1].Value;
try
{
if (suburl.ToLower() == siteurl.ToLower())
{
result.Ranking = pos;
return result;
}
}
catch
{
continue;
}
}
current += 10;
if (current > total)
{
current -= 10;
if (current >= total)
{
break;
}
current = total;
}
}
return result;
}
注意for循环的结束部分,这里是用来处理分页的,以翻到下一页继续检索。其他的大体部分都跟笔者说的一样,下载页面->正则匹配->根据匹配结果判断。剩下的就是SearchRanking的实现,就是循环关键词,只是这里笔者为每个搜索引擎新建线程来实现,当然这不怎么好,所以读者可以改用更好的方式来做:
public override void SearchRanking(IEnumerable<string> keywords, string site, long count)
{
new Thread(() =>
{
foreach (string key in keywords)
{
KeyWordsSeoResult result = SearchFunc(key, site, count);
result.SearchType = SearchProvider;
SetCompleted(result);
}
}).Start();
}
六、统一管理
有了这些我们就可以写出一个简洁的类来负责管理,笔者这里直接给出代码:
/// <summary>
/// 查询网站的收录次数以及排行
/// </summary>
public class RankingAndIncludeSeo
{
/// <summary>
/// 关键词列表
/// </summary>
public IList<KeyWordsSeoBase> KeyWordsSeoList { get; private set; }
/// <summary>
/// 收录次数列表
/// </summary>
public IList<SiteIncludeCountBase> SiteIncludeCountList { get; private set; }
public RankingAndIncludeSeo()
{
KeyWordsSeoList = new List<KeyWordsSeoBase>();
SiteIncludeCountList = new List<SiteIncludeCountBase>();
}
/// <summary>
/// 当完成一个关键词的查询后回调该委托
/// </summary>
public Action<KeyWordsSeoResult> OnComplatedAnyKeyWordsSearch { get; set; }
/// <summary>
/// 当完成一个网站的收录次数查询后回调该委托
/// </summary>
public Action<SiteIncludeCountResult> OnComplatedAnySiteIncludeSearch { get; set; }
/// <summary>
/// 查询网址的排行
/// </summary>
/// <param name="keywords">关键词组</param>
/// <param name="siteurl">查询的网址</param>
/// <param name="count">最大限制排行数</param>
public void SearchKeyWordsRanking(IEnumerable<string> keywords, string siteurl, long count = 100)
{
if (keywords == null)
throw new ArgumentNullException("keywords", "必须存在关键词");
if (siteurl == null)
throw new ArgumentNullException("siteurl", "必须存在网站URL");
foreach (KeyWordsSeoBase kwsb in KeyWordsSeoList)
{
kwsb.OnComplatedOneKeyWord = kwsb.OnComplatedOneKeyWord ?? OnComplatedAnyKeyWordsSearch;
kwsb.SearchRanking(keywords, siteurl, count);
}
}
/// <summary>
/// 查询网址的收录次数
/// </summary>
/// <param name="siteurl">查询的网址</param>
public void SearchSiteIncludeCount(string siteurl)
{
if (siteurl == null)
throw new ArgumentNullException("siteurl", "必须指定网站");
foreach (SiteIncludeCountBase sicb in SiteIncludeCountList)
{
sicb.OnComplatedOneSite = sicb.OnComplatedOneSite ?? OnComplatedAnySiteIncludeSearch;
sicb.SearchIncludeCount(siteurl);
}
}
}
RankingAndIncludeSeo中提供了公共的委托,如果单个搜索引擎没有提供委托那么就采用这个公共的,如果已经指定了单独的委托就不会被赋值了,而其他开发者调用的时候只要向KeyWordsSeoList和SiteIncludeCountList中添加已经实现的类就可以了,方面其他开发者开发出自己的实现并加入其中。
七、小节
这篇随笔总的来说并不是讲述什么高端技术的,仅仅只是提供一种大致的思路以及结构上的设计,如果读者需要应用于实际开发中,最好加以验证,笔者并不能保证关键词的排名没有任何误差,因为搜索的结果会由于任何因素发生改变。
^.^我是源码下载
相关文章
- 这篇文章主要介绍了C# 字段和属性的的相关资料,文中示例代码非常详细,供大家参考和学习,感兴趣的朋友可以了解下...2020-11-03
- 我们在使用C#做项目的时候,基本上都需要制作登录界面,那么今天我们就来一步步看看,如果简单的实现登录界面呢,本文给出2个例子,由简入难,希望大家能够喜欢。...2020-06-25
- 这篇文章主要介绍了C#中截取字符串的的基本方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-03
- 这篇文章主要介绍了C#实现简单的Http请求的方法,以实例形式较为详细的分析了C#实现Http请求的具体方法,需要的朋友可以参考下...2020-06-25
- 本文给大家分享C#连接SQL数据库和查询数据功能的操作技巧,本文通过图文并茂的形式给大家介绍的非常详细,需要的朋友参考下吧...2021-05-17
- 本文主要介绍了C#中new的几种用法,具有很好的参考价值,下面跟着小编一起来看下吧...2020-06-25
使用Visual Studio2019创建C#项目(窗体应用程序、控制台应用程序、Web应用程序)
这篇文章主要介绍了使用Visual Studio2019创建C#项目(窗体应用程序、控制台应用程序、Web应用程序),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2020-06-25- 这篇文章主要介绍了C#开发Windows窗体应用程序的简单操作步骤,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-04-12
- 专做了百度和google的网盟推广以作推广效果的评估比较。百度的周期为6天,google为4天。 从百度的统计数据可以看出这六天的点击次数总共为464,平均点击花费了0.30元...2017-07-06
- 这篇文章主要介绍了C#从数据库读取图片并保存的方法,帮助大家更好的理解和使用c#,感兴趣的朋友可以了解下...2021-01-16
- 最近做一个小项目不可避免的需要前端脚本与后台进行交互。由于是在asp.net中实现,故问题演化成asp.net中jiavascript与后台c#如何进行交互。...2020-06-25
- 本文通过例子,讲述了C++调用C#的DLL程序的方法,作出了以下总结,下面就让我们一起来学习吧。...2020-06-25
- 轻松学习C#的基础入门,了解C#最基本的知识点,C#是一种简洁的,类型安全的一种完全面向对象的开发语言,是Microsoft专门基于.NET Framework平台开发的而量身定做的高级程序设计语言,需要的朋友可以参考下...2020-06-25
- 本文主要介绍了C#变量命名规则小结,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-09-09
- 这篇文章主要介绍了C#绘制曲线图的方法,以完整实例形式较为详细的分析了C#进行曲线绘制的具体步骤与相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下...2020-06-25
- 本文主要介绍了C# 中取绝对值的函数。具有很好的参考价值。下面跟着小编一起来看下吧...2020-06-25
- 这篇文章主要介绍了c#自带缓存使用方法,包括获取数据缓存、设置数据缓存、移除指定数据缓存等方法,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了c#中(&&,||)与(&,|)的区别详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-06-25
- 下面小编就为大家带来一篇C#学习笔记- 随机函数Random()的用法详解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2020-06-25
- 这篇文章主要用实例讲解C#递归算法的概念以及用法,文中代码非常详细,帮助大家更好的参考和学习,感兴趣的朋友可以了解下...2020-06-25