ios开发之将中文转换成字符值引用 (numeric character reference, NCR)
1,什么是字符值引用
(1)字符值引用 (numeric character reference, NCR) 是在标记语言SGML以及派生的如HTML与XML中常见的一种转义序列结构,用来表示Unicode的通用字符集 (UCS)中的单个字符. NCR可以表示在一个特定文档中不能直接编码的字符,而该标记语言阅读器软件把每个NCR当作一个字符来处理。
(2)我们可以将其理解为HTML、XML 等 SGML 类语言的转义序列(escape sequence)。而不是一种编码或转码。
2,字符值引用的格式
以「&#x」开头的后接十六进制数字。或者以「&#」开头的后接十进制数字。
中国 //中国(16进制格式)
中国 //中国(10进制格式)
(不管哪种形式写在html页面中都会正常显示出“中国”)
3,将普通字符串转为字符值引用
由于Swift不提供原生的方法,那么我们通过扩展String类来实现
extension String {
//转译成字符值引用(NCR)
func toHtmlEncodedString() -> String {
var result:String = "";
for scalar in self.utf16 {
//将十进制转成十六进制,不足4位前面补0
let tem = String().stringByAppendingFormat("%04x",scalar)
result += "&#x\(tem);";
}
return result
}
}
使用:
let words = "欢迎来到 hangge.com"
print(words.toHtmlEncodedString())
//欢迎来到 hangge.com
4,将字符值引用转位普通字符串
同样先扩展String类
extension String {
init(htmlEncodedString: String) {
do {
let encodedData = htmlEncodedString.dataUsingEncoding(NSUTF8StringEncoding)!
let attributedOptions : [String: AnyObject] = [
NSDocumentTypeDocumentAttribute: NSHTMLTextDocumentType,
NSCharacterEncodingDocumentAttribute: NSUTF8StringEncoding
]
let attributedString = try NSAttributedString(data: encodedData,
options: attributedOptions, documentAttributes: nil)
self.init(attributedString.string)
} catch {
fatalError("Unhandled error: \(error)")
}
}
}
使用:
let words = String(htmlEncodedString: "欢迎来到 hangge.com")
print(words)
默认情况,导航栏UINavigationController的样式如下,如果想要使用代码修改样式也是比较简单的。

1,修改导航栏背景色

//修改导航栏背景色
self.navigationController?.navigationBar.barTintColor =
UIColor(red: 55/255, green: 186/255, blue: 89/255, alpha: 1)
2,修改导航栏文字颜色

//修改导航栏文字颜色
self.navigationController?.navigationBar.titleTextAttributes =
[NSForegroundColorAttributeName: UIColor.whiteColor()]

//修改导航栏按钮颜色
self.navigationController?.navigationBar.tintColor = UIColor.whiteColor()
4,修改导航栏背景图片
如果背景图片不需要延伸到状态栏后面,那么背景图片高度是44点(88像素)。

如果需要把导航栏也包含在背景图片下,那么背景图片高度改为64点(128像素)。

不管何种尺寸,设置代码如下:
self.navigationController?.navigationBar
.setBackgroundImage(UIImage(named: "bg5"), forBarMetrics: .Default)
内存泄漏产生的原因
当一个对象已经不需要再使用了,本该被回收时,而有另外一个正在使用的对象持有它的引用从而导致它不能被回收,这导致本该被回收的对象不能被回收而停留在堆内存中,这就产生了内存泄漏。
内存泄漏对程序的影响?
内存泄漏是造成应用程序OOM的主要原因之一!我们知道Android系统为每个应用程序分配的内存有限,而当一个应用中产生的内存泄漏比较多时,这就难免会导致应用所需要的内存超过这个系统分配的内存限额,这就造成了内存溢出而导致应用Crash。
Android中常见的内存泄漏汇总
单例造成的内存泄漏
单例模式非常受开发者的喜爱,不过使用的不恰当的话也会造成内存泄漏,由于单例的静态特性使得单例的生命周期和应用的生命周期一样长,这就说明了如果一个对象已经不需要使用了,而单例对象还持有该对象的引用,那么这个对象将不能被正常回收,这就导致了内存泄漏。如下这个典例:
public class AppManager {
private static AppManager instance;
private Context context;
private AppManager(Context context) {
this.context = context;
}
public static AppManager getInstance(Context context) {
if (instance != null) {
instance = new AppManager(context);
}
return instance;
}
}
这是一个普通的单例模式,当创建这个单例的时候,由于需要传入一个Context,所以这个Context的生命周期的长短至关重要:
1、传入的是Application的Context:这将没有任何问题,因为单例的生命周期和Application的一样长
2、传入的是Activity的Context:当这个Context所对应的Activity退出时,由于该Context和Activity的生命周期一样长(Activity间接继承于Context),所以当前Activity退出时它的内存并不会被回收,因为单例对象持有该Activity的引用。
所以正确的单例应该修改为下面这种方式:
public class AppManager {
private static AppManager instance;
private Context context;
private AppManager(Context context) {
this.context = context.getApplicationContext();
}
public static AppManager getInstance(Context context) {
if (instance != null) {
instance = new AppManager(context);
}
return instance;
}
}
这样不管传入什么Context最终将使用Application的Context,而单例的生命周期和应用的一样长,这样就防止了内存泄漏
非静态内部类创建静态实例造成的内存泄漏
有的时候我们可能会在启动频繁的Activity中,为了避免重复创建相同的数据资源,可能会出现这种写法:
public class MainActivity extends AppCompatActivity {
private static TestResource mResource = null;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
if(mManager == null){
mManager = new TestResource();
}
//...
}
class TestResource {
//...
}
}
这样就在Activity内部创建了一个非静态内部类的单例,每次启动Activity时都会使用该单例的数据,这样虽然避免了资源的重复创建,不过这种写法却会造成内存泄漏,因为非静态内部类默认会持有外部类的引用,而又使用了该非静态内部类创建了一个静态的实例,该实例的生命周期和应用的一样长,这就导致了该静态实例一直会持有该Activity的引用,导致Activity的内存资源不能正常回收。正确的做法为:将该内部类设为静态内部类或将该内部类抽取出来封装成一个单例,如果需要使用Context,请使用ApplicationContext
Handler造成的内存泄漏
Handler的使用造成的内存泄漏问题应该说最为常见了,平时在处理网络任务或者封装一些请求回调等api都应该会借助Handler来处理,对于Handler的使用代码编写一不规范即有可能造成内存泄漏,如下示例:
public class MainActivity extends AppCompatActivity {
private Handler mHandler = new Handler() {
@Override
public void handleMessage(Message msg) {
//...
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
loadData();
}
private void loadData(){
//...request
Message message = Message.obtain();
mHandler.sendMessage(message);
}
}
这种创建Handler的方式会造成内存泄漏,由于mHandler是Handler的非静态匿名内部类的实例,所以它持有外部类Activity的引用,我们知道消息队列是在一个Looper线程中不断轮询处理消息,那么当这个Activity退出时消息队列中还有未处理的消息或者正在处理消息,而消息队列中的Message持有mHandler实例的引用,mHandler又持有Activity的引用,所以导致该Activity的内存资源无法及时回收,引发内存泄漏,所以另外一种做法为:
public class MainActivity extends AppCompatActivity {
private MyHandler mHandler = new MyHandler(this);
private TextView mTextView ;
private static class MyHandler extends Handler {
private WeakReference<Context> reference;
public MyHandler(Context context) {
reference = new WeakReference<>(context);
}
@Override
public void handleMessage(Message msg) {
MainActivity activity = (MainActivity) reference.get();
if(activity != null){
activity.mTextView.setText("");
}
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mTextView = (TextView)findViewById(R.id.textview);
loadData();
}
private void loadData() {
//...request
Message message = Message.obtain();
mHandler.sendMessage(message);
}
}
创建一个静态Handler内部类,然后对Handler持有的对象使用弱引用,这样在回收时也可以回收Handler持有的对象,这样虽然避免了Activity泄漏,不过Looper线程的消息队列中还是可能会有待处理的消息,所以我们在Activity的Destroy时或者Stop时应该移除消息队列中的消息,更准确的做法如下:
public class MainActivity extends AppCompatActivity {
private MyHandler mHandler = new MyHandler(this);
private TextView mTextView ;
private static class MyHandler extends Handler {
private WeakReference<Context> reference;
public MyHandler(Context context) {
reference = new WeakReference<>(context);
}
@Override
public void handleMessage(Message msg) {
MainActivity activity = (MainActivity) reference.get();
if(activity != null){
activity.mTextView.setText("");
}
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mTextView = (TextView)findViewById(R.id.textview);
loadData();
}
private void loadData() {
//...request
Message message = Message.obtain();
mHandler.sendMessage(message);
}
@Override
protected void onDestroy() {
super.onDestroy();
mHandler.removeCallbacksAndMessages(null);
}
}
使用mHandler.removeCallbacksAndMessages(null);是移除消息队列中所有消息和所有的Runnable。当然也可以使用mHandler.removeCallbacks();或mHandler.removeMessages();来移除指定的Runnable和Message。
线程造成的内存泄漏
对于线程造成的内存泄漏,也是平时比较常见的,如下这两个示例可能每个人都这样写过:
//——————test1
new AsyncTask<Void, Void, Void>() {
@Override
protected Void doInBackground(Void... params) {
SystemClock.sleep(10000);
return null;
}
}.execute();
//——————test2
new Thread(new Runnable() {
@Override
public void run() {
SystemClock.sleep(10000);
}
}).start();
上面的异步任务和Runnable都是一个匿名内部类,因此它们对当前Activity都有一个隐式引用。如果Activity在销毁之前,任务还未完成,那么将导致Activity的内存资源无法回收,造成内存泄漏。正确的做法还是使用静态内部类的方式,如下:
static class MyAsyncTask extends AsyncTask<Void, Void, Void> {
private WeakReference<Context> weakReference;
public MyAsyncTask(Context context) {
weakReference = new WeakReference<>(context);
}
@Override
protected Void doInBackground(Void... params) {
SystemClock.sleep(10000);
return null;
}
@Override
protected void onPostExecute(Void aVoid) {
super.onPostExecute(aVoid);
MainActivity activity = (MainActivity) weakReference.get();
if (activity != null) {
//...
}
}
}
static class MyRunnable implements Runnable{
@Override
public void run() {
SystemClock.sleep(10000);
}
}
//——————
new Thread(new MyRunnable()).start();
new MyAsyncTask(this).execute();
这样就避免了Activity的内存资源泄漏,当然在Activity销毁时候也应该取消相应的任务AsyncTask::cancel(),避免任务在后台执行浪费资源。
资源未关闭造成的内存泄漏
对于使用了BraodcastReceiver,ContentObserver,File,Cursor,Stream,Bitmap等资源的使用,应该在Activity销毁时及时关闭或者注销,否则这些资源将不会被回收,造成内存泄漏。
一些建议
1、对于生命周期比Activity长的对象如果需要应该使用ApplicationContext
2、在涉及到Context时先考虑ApplicationContext,当然它并不是万能的,对于有些地方则必须使用Activity的Context,对于Application,Service,Activity三者的Context的应用场景如下:
**其中:**NO1表示Application和Service可以启动一个Activity,不过需要创建一个新的task任务队列。而对于Dialog而言,只有在Activity中才能创建
3、对于需要在静态内部类中使用非静态外部成员变量(如:Context、View ),可以在静态内部类中使用弱引用来引用外部类的变量来避免内存泄漏
4、对于生命周期比Activity长的内部类对象,并且内部类中使用了外部类的成员变量,可以这样做避免内存泄漏:
将内部类改为静态内部类
静态内部类中使用弱引用来引用外部类的成员变量
5、对于不再需要使用的对象,显示的将其赋值为null,比如使用完Bitmap后先调用recycle(),再赋为null6、保持对对象生命周期的敏感,特别注意单例、静态对象、全局性集合等的生命周期
Android性能优化之避免内存泄漏的建议
1、对于生命周期比Activity长的对象,如果需要应该使用ApplicationContext ;
2、在涉及到Context时先考虑ApplicationContext,当然它并不是万能的,对于有些地方则必须使用Activity的Context,对于Application,Service,Activity三者的Context的应用场景如下:

**其中:**NO1表示Application和Service可以启动一个Activity,不过需要创建一个新的task任务队列。而对于Dialog而言,只有在Activity中才能创建 。
3、对于需要在静态内部类中使用非静态外部成员变量(如:Context、View ),可以在静态内部类中使用弱引用来引用外部类的变量来避免内存泄漏 。
4、对于生命周期比Activity长的内部类对象,并且内部类中使用了外部类的成员变量,可以这样做避免内存泄漏:
1)将内部类改为静态内部类
2)静态内部类中使用弱引用来引用外部类的成员变量
5、对于不再需要使用的对象,显示的将其赋值为null,比如使用完Bitmap后先调用recycle(),再赋为null 。
6、保持对对象生命周期的敏感,特别注意单例、静态对象、全局性集合等的生命周期。
首先来看一下他们的基本概念:
px :是屏幕的像素点
dp :一个基于density的抽象单位,如果一个160dpi的屏幕,1dp=1px
dip :等同于dp
sp :同dp相似,文本的单位
下面来看一下手机屏幕类型和密度以及分辨率的对应关系
QVGA屏density=120 QVGA(240*320)
HVGA屏density=160 HVGA(320*480)
WVGA屏density=240 WVGA(480*800)
WQVGA屏density=120 WQVGA(240*400)
pixs =dips * (densityDpi/160).
dips=(pixs*160)/densityDpi
像素和dp之间的转换
| 代码如下 | 复制代码 |
|
public int Dp2Px(Context context, float dp) { public int Px2Dp(Context context, float px) { | |
这里我把获取屏幕高度的代码也贴上来吧:
| 代码如下 | 复制代码 |
|
DisplayMetrics dm = new DisplayMetrics();
getWindowManager().getDefaultDisplay().getMetrics(dm); int width = dm.widthPixels; int height = dm.heightPixels; | |
dp这个单位可能对web开发的人比较陌生,因为一般都是使用px(像素)
但是,现在在开始android应用和游戏后,基本上都转换成用dp作用为单位了,因为可以支持多种分辨率的手机.
下面我们来看一下如何对native层进行加密,从而增加破解难度。我们在使用native层的时候,我们都知道一般是和Java层调用native层函数,那么我们就需要对native层函数进行加密,把重要的功能实现存放到native层,加大破解难度,那么我们来看一下如何对so中的函数进行加密?
这里有两种方案:
1、我们知道so文件中有很多section,我们可以将我们的目标函数存到指定的section中,然后对section进行加密即可。
技术原理
加密:在之前的文章中我们介绍了so中的格式,那么对于找到一个section的base和size就可以对这段section进行加密了
解密:因为我们对section进行加密之后,肯定需要解密的,不然的话,运行肯定是报错的,那么这里的重点是什么时候去进行解密,对于一个so文件,我们load进程序之后,在运行程序之前我们可以从哪个时间点来突破?这里就需要一个知识点:
__attribute__((constructor));
关于这个,属性的用法这里就不做介绍了,网上有相关资料,他的作用很简单,就是优先于main方法之前执行,类似于Java中的构造函数,当然其实C++中的构造函数就是基于这个属性实现的,我们在之前介绍elf文件格式的时候,有两个section会引起我们的注意:
对于这两个section,其实就是用这个属性实现的函数存在这里,
在动态链接器构造了进程映像,并执行了重定位以后,每个共享的目标都获得执行 某些初始化代码的机会。这些初始化函数的被调用顺序是不一定的,不过所有共享目标 初始化都会在可执行文件得到控制之前发生。
类似地,共享目标也包含终止函数,这些函数在进程完成终止动作序列时,通过 atexit() 机制执行。动态链接器对终止函数的调用顺序是不确定的。
共享目标通过动态结构中的 DT_INIT 和 DT_FINI 条目指定初始化/终止函数。通常 这些代码放在.init 和.fini 节区中。
这个知识点很重要,我们后面在进行动态调试so的时候,还会用到这个知识点,所以一定要理解。
所以,在这里我们找到了解密的时机,就是自己定义一个解密函数,然后用上面的这个属性声明就可以了。
实现流程
第一、我们编写一个简单的native代码,这里我们需要做两件事:
1、将我们核心的native函数定义在自己的一个section中,这里会用到这个属性:__attribute__((section (".mytext")));
其中.mytext就是我们自己定义的section.
说到这里,还记得我们之前介绍的一篇文章中介绍了,动态的给so添加一个section:
http://www.lai18.com/content/1425305.html
2、需要编写我们的解密函数,用属性: __attribute__((constructor));声明
这样一个native程序就包含这两个重要的函数,使用ndk编译成so文件
第二、编写加密程序,在加密程序中我们需要做的是:
1、通过解析so文件,找到.mytext段的起始地址和大小,这里的思路是:
找到所有的Section,然后获取他的name字段,在结合String Section,遍历找到.mytext字段
2、找到.mytext段之后,然后进行加密,最后在写入到文件中。
技术实现
前面介绍了原理和实现方案,下面就开始coding吧,
第一、我们先来看看native程序
#include <jni.h>
#include <stdio.h>
#include <android/log.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <elf.h>
#include <sys/mman.h>
jstring getString(JNIEnv*) __attribute__((section (".mytext")));
jstring getString(JNIEnv* env){
return (*env)->NewStringUTF(env, "Native method return!");
};
void init_getString() __attribute__((constructor));
unsigned long getLibAddr();
void init_getString(){
char name[15];
unsigned int nblock;
unsigned int nsize;
unsigned long base;
unsigned long text_addr;
unsigned int i;
Elf32_Ehdr *ehdr;
Elf32_Shdr *shdr;
base = getLibAddr();
ehdr = (Elf32_Ehdr *)base;
text_addr = ehdr->e_shoff + base;
nblock = ehdr->e_entry >> 16;
nsize = ehdr->e_entry & 0xffff;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "nblock = 0x%x,nsize:%d", nblock,nsize);
__android_log_print(ANDROID_LOG_INFO, "JNITag", "base = 0x%x", text_addr);
printf("nblock = %d\n", nblock);
if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){
puts("mem privilege change failed");
__android_log_print(ANDROID_LOG_INFO, "JNITag", "mem privilege change failed");
}
for(i=0;i< nblock; i++){
char *addr = (char*)(text_addr + i);
*addr = ~(*addr);
}
if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC) != 0){
puts("mem privilege change failed");
}
puts("Decrypt success");
}
unsigned long getLibAddr(){
unsigned long ret = 0;
char name[] = "libdemo.so";
char buf[4096], *temp;
int pid;
FILE *fp;
pid = getpid();
sprintf(buf, "/proc/%d/maps", pid);
fp = fopen(buf, "r");
if(fp == NULL)
{
puts("open failed");
goto _error;
}
while(fgets(buf, sizeof(buf), fp)){
if(strstr(buf, name)){
temp = strtok(buf, "-");
ret = strtoul(temp, NULL, 16);
break;
}
}
_error:
fclose(fp);
return ret;
}
JNIEXPORT jstring JNICALL
Java_com_example_shelldemo_MainActivity_getString( JNIEnv* env,
jobject thiz )
{
#if defined(__arm__)
#if defined(__ARM_ARCH_7A__)
#if defined(__ARM_NEON__)
#define ABI "armeabi-v7a/NEON"
#else
#define ABI "armeabi-v7a"
#endif
#else
#define ABI "armeabi"
#endif
#elif defined(__i386__)
#define ABI "x86"
#elif defined(__mips__)
#define ABI "mips"
#else
#define ABI "unknown"
#endif
return getString(env);
}
下面来分析一下代码:
1、定义自己的段
jstring getString(JNIEnv*) __attribute__((section (".mytext")));
jstring getString(JNIEnv* env){
return (*env)->NewStringUTF(env, "Native method return!");
};
这里的getString返回一个字符串,提供给Android上层,然后将getString定义在.mytext段中。
2、获取so加载到内存中的起始地址
unsigned long getLibAddr(){
unsigned long ret = 0;
char name[] = "libdemo.so";
char buf[4096], *temp;
int pid;
FILE *fp;
pid = getpid();
sprintf(buf, "/proc/%d/maps", pid);
fp = fopen(buf, "r");
if(fp == NULL)
{
puts("open failed");
goto _error;
}
while(fgets(buf, sizeof(buf), fp)){
if(strstr(buf, name)){
temp = strtok(buf, "-");
ret = strtoul(temp, NULL, 16);
break;
}
}
_error:
fclose(fp);
return ret;
}
这里的代码其实就是读取设备的proc/<uid>/maps中的内容,因为这个maps中是程序运行的内存映像:
我们只有获取到so的起始地址,才能找到指定的Section然后进行解密。
3、解密函数
void init_getString(){
char name[15];
unsigned int nblock;
unsigned int nsize;
unsigned long base;
unsigned long text_addr;
unsigned int i;
Elf32_Ehdr *ehdr;
Elf32_Shdr *shdr;
//获取so的起始地址
base = getLibAddr();
//获取指定section的偏移值和size
ehdr = (Elf32_Ehdr *)base;
text_addr = ehdr->e_shoff + base;
nblock = ehdr->e_entry >> 16;
nsize = ehdr->e_entry & 0xffff;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "nblock = 0x%x,nsize:%d", nblock,nsize);
__android_log_print(ANDROID_LOG_INFO, "JNITag", "base = 0x%x", text_addr);
printf("nblock = %d\n", nblock);
//修改内存的操作权限
if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){
puts("mem privilege change failed");
__android_log_print(ANDROID_LOG_INFO, "JNITag", "mem privilege change failed");
}
//解密
for(i=0;i< nblock; i++){
char *addr = (char*)(text_addr + i);
*addr = ~(*addr);
}
if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC) != 0){
puts("mem privilege change failed");
}
puts("Decrypt success");
}
这里我们获取到so文件的头部,然后获取指定section的偏移地址和size
//获取so的起始地址
base = getLibAddr();
//获取指定section的偏移值和size
ehdr = (Elf32_Ehdr *)base;
text_addr = ehdr->e_shoff + base;
nblock = ehdr->e_entry >> 16;
nsize = ehdr->e_entry & 0xffff;
这里可能会有困惑?为什么这里是这么获取offset和size的,其实这里我们做了一点工作,就是我们在加密的时候顺便改写了so的头部信息,将offset和size值写到了头部中,这样加大破解难度。后面在说到加密的时候在详解。
text_addr是起始地址+偏移值,就是我们的section在内存中的绝对地址
nsize是我们的section占用的页数
然后修改这个section的内存操作权限
//修改内存的操作权限
if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){
puts("mem privilege change failed");
__android_log_print(ANDROID_LOG_INFO, "JNITag", "mem privilege change failed");
}
这里调用了一个系统函数:mprotect
第一个参数:需要修改内存的起始地址
必须需要页面对齐,也就是必须是页面PAGE_SIZE(0x1000=4096)的整数倍
第二个参数:需要修改的大小
占用的页数*PAGE_SIZE
第三个参数:权限值
最后读取内存中的section内容,然后进行解密,在将内存权限修改回去。
然后使用ndk编译成so即可,这里我们用到了系统的打印log信息,所以需要用到共享库,看一下编译脚本Android.mk
LOCAL_PATH := $(call my-dir)
include $(CLEAR_VARS)
LOCAL_MODULE := demo
LOCAL_SRC_FILES := demo.c
LOCAL_LDLIBS := -llog
include $(BUILD_SHARED_LIBRARY)
第二、加密程序
1、加密程序(Java版)
我们获取到上面的so文件,下面我们就来看看如何进行加密的:
package com.jiangwei.encodesection;
import com.jiangwei.encodesection.ElfType32.Elf32_Sym;
import com.jiangwei.encodesection.ElfType32.elf32_phdr;
import com.jiangwei.encodesection.ElfType32.elf32_shdr;
public class EncodeSection {
public static String encodeSectionName = ".mytext";
public static ElfType32 type_32 = new ElfType32();
public static void main(String[] args){
byte[] fileByteArys = Utils.readFile("so/libdemo.so");
if(fileByteArys == null){
System.out.println("read file byte failed...");
return;
}
/**
* 先解析so文件
* 然后初始化AddSection中的一些信息
* 最后在AddSection
*/
parseSo(fileByteArys);
encodeSection(fileByteArys);
parseSo(fileByteArys);
Utils.saveFile("so/libdemos.so", fileByteArys);
}
private static void encodeSection(byte[] fileByteArys){
//读取String Section段
System.out.println();
int string_section_index = Utils.byte2Short(type_32.hdr.e_shstrndx);
elf32_shdr shdr = type_32.shdrList.get(string_section_index);
int size = Utils.byte2Int(shdr.sh_size);
int offset = Utils.byte2Int(shdr.sh_offset);
int mySectionOffset=0,mySectionSize=0;
for(elf32_shdr temp : type_32.shdrList){
int sectionNameOffset = offset+Utils.byte2Int(temp.sh_name);
if(Utils.isEqualByteAry(fileByteArys, sectionNameOffset, encodeSectionName)){
//这里需要读取section段然后进行数据加密
mySectionOffset = Utils.byte2Int(temp.sh_offset);
mySectionSize = Utils.byte2Int(temp.sh_size);
byte[] sectionAry = Utils.copyBytes(fileByteArys, mySectionOffset, mySectionSize);
for(int i=0;i<sectionAry.length;i++){
sectionAry[i] = (byte)(sectionAry[i] ^ 0xFF);
}
Utils.replaceByteAry(fileByteArys, mySectionOffset, sectionAry);
}
}
//修改Elf Header中的entry和offset值
int nSize = mySectionSize/4096 + (mySectionSize%4096 == 0 ? 0 : 1);
byte[] entry = new byte[4];
entry = Utils.int2Byte((mySectionSize<<16) + nSize);
Utils.replaceByteAry(fileByteArys, 24, entry);
byte[] offsetAry = new byte[4];
offsetAry = Utils.int2Byte(mySectionOffset);
Utils.replaceByteAry(fileByteArys, 32, offsetAry);
}
private static void parseSo(byte[] fileByteArys){
//读取头部内容
System.out.println("+++++++++++++++++++Elf Header+++++++++++++++++");
parseHeader(fileByteArys, 0);
System.out.println("header:\n"+type_32.hdr);
//读取程序头信息
//System.out.println();
//System.out.println("+++++++++++++++++++Program Header+++++++++++++++++");
int p_header_offset = Utils.byte2Int(type_32.hdr.e_phoff);
parseProgramHeaderList(fileByteArys, p_header_offset);
//type_32.printPhdrList();
//读取段头信息
//System.out.println();
//System.out.println("+++++++++++++++++++Section Header++++++++++++++++++");
int s_header_offset = Utils.byte2Int(type_32.hdr.e_shoff);
parseSectionHeaderList(fileByteArys, s_header_offset);
//type_32.printShdrList();
//这种方式获取所有的Section的name
/*byte[] names = Utils.copyBytes(fileByteArys, offset, size);
String str = new String(names);
byte NULL = 0;//字符串的结束符
StringTokenizer st = new StringTokenizer(str, new String(new byte[]{NULL}));
System.out.println( "Token Total: " + st.countTokens() );
while(st.hasMoreElements()){
System.out.println(st.nextToken());
}
System.out.println("");*/
/*//读取符号表信息(Symbol Table)
System.out.println();
System.out.println("+++++++++++++++++++Symbol Table++++++++++++++++++");
//这里需要注意的是:在Elf表中没有找到SymbolTable的数目,但是我们仔细观察Section中的Type=DYNSYM段的信息可以得到,这个段的大小和偏移地址,而SymbolTable的结构大小是固定的16个字节
//那么这里的数目=大小/结构大小
//首先在SectionHeader中查找到dynsym段的信息
int offset_sym = 0;
int total_sym = 0;
for(elf32_shdr shdr : type_32.shdrList){
if(Utils.byte2Int(shdr.sh_type) == ElfType32.SHT_DYNSYM){
total_sym = Utils.byte2Int(shdr.sh_size);
offset_sym = Utils.byte2Int(shdr.sh_offset);
break;
}
}
int num_sym = total_sym / 16;
System.out.println("sym num="+num_sym);
parseSymbolTableList(fileByteArys, num_sym, offset_sym);
type_32.printSymList();
//读取字符串表信息(String Table)
System.out.println();
System.out.println("+++++++++++++++++++Symbol Table++++++++++++++++++");
//这里需要注意的是:在Elf表中没有找到StringTable的数目,但是我们仔细观察Section中的Type=STRTAB段的信息,可以得到,这个段的大小和偏移地址,但是我们这时候我们不知道字符串的大小,所以就获取不到数目了
//这里我们可以查看Section结构中的name字段:表示偏移值,那么我们可以通过这个值来获取字符串的大小
//可以这么理解:当前段的name值 减去 上一段的name的值 = (上一段的name字符串的长度)
//首先获取每个段的name的字符串大小
int prename_len = 0;
int[] lens = new int[type_32.shdrList.size()];
int total = 0;
for(int i=0;i<type_32.shdrList.size();i++){
if(Utils.byte2Int(type_32.shdrList.get(i).sh_type) == ElfType32.SHT_STRTAB){
int curname_offset = Utils.byte2Int(type_32.shdrList.get(i).sh_name);
lens[i] = curname_offset - prename_len - 1;
if(lens[i] < 0){
lens[i] = 0;
}
total += lens[i];
System.out.println("total:"+total);
prename_len = curname_offset;
//这里需要注意的是,最后一个字符串的长度,需要用总长度减去前面的长度总和来获取到
if(i == (lens.length - 1)){
System.out.println("size:"+Utils.byte2Int(type_32.shdrList.get(i).sh_size));
lens[i] = Utils.byte2Int(type_32.shdrList.get(i).sh_size) - total - 1;
}
}
}
for(int i=0;i<lens.length;i++){
System.out.println("len:"+lens[i]);
}
//上面的那个方法不好,我们发现StringTable中的每个字符串结束都会有一个00(传说中的字符串结束符),那么我们只要知道StringTable的开始位置,然后就可以读取到每个字符串的值了
*/
}
/**
* 解析Elf的头部信息
* @param header
*/
private static void parseHeader(byte[] header, int offset){
if(header == null){
System.out.println("header is null");
return;
}
/**
* public byte[] e_ident = new byte[16];
public short e_type;
public short e_machine;
public int e_version;
public int e_entry;
public int e_phoff;
public int e_shoff;
public int e_flags;
public short e_ehsize;
public short e_phentsize;
public short e_phnum;
public short e_shentsize;
public short e_shnum;
public short e_shstrndx;
*/
type_32.hdr.e_ident = Utils.copyBytes(header, 0, 16);//魔数
type_32.hdr.e_type = Utils.copyBytes(header, 16, 2);
type_32.hdr.e_machine = Utils.copyBytes(header, 18, 2);
type_32.hdr.e_version = Utils.copyBytes(header, 20, 4);
type_32.hdr.e_entry = Utils.copyBytes(header, 24, 4);
type_32.hdr.e_phoff = Utils.copyBytes(header, 28, 4);
type_32.hdr.e_shoff = Utils.copyBytes(header, 32, 4);
type_32.hdr.e_flags = Utils.copyBytes(header, 36, 4);
type_32.hdr.e_ehsize = Utils.copyBytes(header, 40, 2);
type_32.hdr.e_phentsize = Utils.copyBytes(header, 42, 2);
type_32.hdr.e_phnum = Utils.copyBytes(header, 44,2);
type_32.hdr.e_shentsize = Utils.copyBytes(header, 46,2);
type_32.hdr.e_shnum = Utils.copyBytes(header, 48, 2);
type_32.hdr.e_shstrndx = Utils.copyBytes(header, 50, 2);
}
/**
* 解析程序头信息
* @param header
*/
public static void parseProgramHeaderList(byte[] header, int offset){
int header_size = 32;//32个字节
int header_count = Utils.byte2Short(type_32.hdr.e_phnum);//头部的个数
byte[] des = new byte[header_size];
for(int i=0;i<header_count;i++){
System.arraycopy(header, i*header_size + offset, des, 0, header_size);
type_32.phdrList.add(parseProgramHeader(des));
}
}
private static elf32_phdr parseProgramHeader(byte[] header){
/**
* public int p_type;
public int p_offset;
public int p_vaddr;
public int p_paddr;
public int p_filesz;
public int p_memsz;
public int p_flags;
public int p_align;
*/
ElfType32.elf32_phdr phdr = new ElfType32.elf32_phdr();
phdr.p_type = Utils.copyBytes(header, 0, 4);
phdr.p_offset = Utils.copyBytes(header, 4, 4);
phdr.p_vaddr = Utils.copyBytes(header, 8, 4);
phdr.p_paddr = Utils.copyBytes(header, 12, 4);
phdr.p_filesz = Utils.copyBytes(header, 16, 4);
phdr.p_memsz = Utils.copyBytes(header, 20, 4);
phdr.p_flags = Utils.copyBytes(header, 24, 4);
phdr.p_align = Utils.copyBytes(header, 28, 4);
return phdr;
}
/**
* 解析段头信息内容
*/
public static void parseSectionHeaderList(byte[] header, int offset){
int header_size = 40;//40个字节
int header_count = Utils.byte2Short(type_32.hdr.e_shnum);//头部的个数
byte[] des = new byte[header_size];
for(int i=0;i<header_count;i++){
System.arraycopy(header, i*header_size + offset, des, 0, header_size);
type_32.shdrList.add(parseSectionHeader(des));
}
}
private static elf32_shdr parseSectionHeader(byte[] header){
ElfType32.elf32_shdr shdr = new ElfType32.elf32_shdr();
/**
* public byte[] sh_name = new byte[4];
public byte[] sh_type = new byte[4];
public byte[] sh_flags = new byte[4];
public byte[] sh_addr = new byte[4];
public byte[] sh_offset = new byte[4];
public byte[] sh_size = new byte[4];
public byte[] sh_link = new byte[4];
public byte[] sh_info = new byte[4];
public byte[] sh_addralign = new byte[4];
public byte[] sh_entsize = new byte[4];
*/
shdr.sh_name = Utils.copyBytes(header, 0, 4);
shdr.sh_type = Utils.copyBytes(header, 4, 4);
shdr.sh_flags = Utils.copyBytes(header, 8, 4);
shdr.sh_addr = Utils.copyBytes(header, 12, 4);
shdr.sh_offset = Utils.copyBytes(header, 16, 4);
shdr.sh_size = Utils.copyBytes(header, 20, 4);
shdr.sh_link = Utils.copyBytes(header, 24, 4);
shdr.sh_info = Utils.copyBytes(header, 28, 4);
shdr.sh_addralign = Utils.copyBytes(header, 32, 4);
shdr.sh_entsize = Utils.copyBytes(header, 36, 4);
return shdr;
}
/**
* 解析Symbol Table内容
*/
public static void parseSymbolTableList(byte[] header, int header_count, int offset){
int header_size = 16;//16个字节
byte[] des = new byte[header_size];
for(int i=0;i<header_count;i++){
System.arraycopy(header, i*header_size + offset, des, 0, header_size);
type_32.symList.add(parseSymbolTable(des));
}
}
private static ElfType32.Elf32_Sym parseSymbolTable(byte[] header){
/**
* public byte[] st_name = new byte[4];
public byte[] st_value = new byte[4];
public byte[] st_size = new byte[4];
public byte st_info;
public byte st_other;
public byte[] st_shndx = new byte[2];
*/
Elf32_Sym sym = new Elf32_Sym();
sym.st_name = Utils.copyBytes(header, 0, 4);
sym.st_value = Utils.copyBytes(header, 4, 4);
sym.st_size = Utils.copyBytes(header, 8, 4);
sym.st_info = header[12];
//FIXME 这里有一个问题,就是这个字段读出来的值始终是0
sym.st_other = header[13];
sym.st_shndx = Utils.copyBytes(header, 14, 2);
return sym;
}
}
在这里,我需要解析so文件的头部信息,程序头信息,段头信息
//读取头部内容
System.out.println("+++++++++++++++++++Elf Header+++++++++++++++++");
parseHeader(fileByteArys, 0);
System.out.println("header:\n"+type_32.hdr);
//读取程序头信息
//System.out.println();
//System.out.println("+++++++++++++++++++Program Header+++++++++++++++++");
int p_header_offset = Utils.byte2Int(type_32.hdr.e_phoff);
parseProgramHeaderList(fileByteArys, p_header_offset);
//type_32.printPhdrList();
//读取段头信息
//System.out.println();
//System.out.println("+++++++++++++++++++Section Header++++++++++++++++++");
int s_header_offset = Utils.byte2Int(type_32.hdr.e_shoff);
parseSectionHeaderList(fileByteArys, s_header_offset);
//type_32.printShdrList();
获取这些信息之后,下面就来开始寻找我们的段了,只需要遍历Section列表,找到名字是.mytext的section即可,然后获取offset和size,对内容进行加密,回写到文件中。下面来看看核心方法:
private static void encodeSection(byte[] fileByteArys){
//读取String Section段
System.out.println();
int string_section_index = Utils.byte2Short(type_32.hdr.e_shstrndx);
elf32_shdr shdr = type_32.shdrList.get(string_section_index);
int size = Utils.byte2Int(shdr.sh_size);
int offset = Utils.byte2Int(shdr.sh_offset);
int mySectionOffset=0,mySectionSize=0;
for(elf32_shdr temp : type_32.shdrList){
int sectionNameOffset = offset+Utils.byte2Int(temp.sh_name);
if(Utils.isEqualByteAry(fileByteArys, sectionNameOffset, encodeSectionName)){
//这里需要读取section段然后进行数据加密
mySectionOffset = Utils.byte2Int(temp.sh_offset);
mySectionSize = Utils.byte2Int(temp.sh_size);
byte[] sectionAry = Utils.copyBytes(fileByteArys, mySectionOffset, mySectionSize);
for(int i=0;i<sectionAry.length;i++){
sectionAry[i] = (byte)(sectionAry[i] ^ 0xFF);
}
Utils.replaceByteAry(fileByteArys, mySectionOffset, sectionAry);
}
}
//修改Elf Header中的entry和offset值
int nSize = mySectionSize/4096 + (mySectionSize%4096 == 0 ? 0 : 1);
byte[] entry = new byte[4];
entry = Utils.int2Byte((mySectionSize<<16) + nSize);
Utils.replaceByteAry(fileByteArys, 24, entry);
byte[] offsetAry = new byte[4];
offsetAry = Utils.int2Byte(mySectionOffset);
Utils.replaceByteAry(fileByteArys, 32, offsetAry);
}
我们知道Section中的sh_name字段的值是这个section段的name在StringSection中的索引值,这里offset就是StringSection在文件中的偏移值。当然我们需要知道的一个知识点就是:StringSection中的每个name都是以\0结尾的,所以我们只需要判断字符串到结束符就可以了,判断方法是Utils.isEqualByteAry:
public static boolean isEqualByteAry(byte[] src, int start, String destStr){
if(destStr == null){
return false;
}
byte[] dest = destStr.getBytes();
if(src == null || dest == null){
return false;
}
if(dest.length == 0 || src.length == 0){
return false;
}
if(start >= src.length){
return false;
}
int len = 0;
byte temp = src[start];
while(temp != 0){
len++;
temp = src[start+len];
}
byte[] sonAry = copyBytes(src, start, len);
if(sonAry == null || sonAry.length == 0){
return false;
}
if(sonAry.length != dest.length){
return false;
}
String sonStr = new String(sonAry);
if(destStr.equals(sonStr)){
return true;
}
return false;
}
这里我们加密的方法很简单,加密完成之后,我们需要做的是回写到so文件中,当然这里我们还需要做一件事,就是将我们加密的.mytext段的偏移值和pageSize保存到头部信息中:
//修改Elf Header中的entry和offset值
int nSize = mySectionSize/4096 + (mySectionSize%4096 == 0 ? 0 : 1);
byte[] entry = new byte[4];
entry = Utils.int2Byte((mySectionSize<<16) + nSize);
Utils.replaceByteAry(fileByteArys, 24, entry);
这里又有一个知识点需要说明?大家可能会困惑,我们这样修改了so的头部信息的话,在加载运行so文件的时候不会报错吗?这个就要看看Android底层是如何解析so文件,然后将so文件映射到内存中的了,下面我们来看看系统是如何解析so文件的?
源代码的位置:Android linker源码:bionic\linker
在linker.h源码中有一个重要的结构体soinfo,下面列出一些字段:
struct soinfo{
const char name[SOINFO_NAME_LEN]; //so全名
Elf32_Phdr *phdr; //Program header的地址
int phnum; //segment 数量
unsigned *dynamic; //指向.dynamic,在section和segment中相同的
//以下4个成员与.hash表有关
unsigned nbucket;
unsigned nchain;
unsigned *bucket;
unsigned *chain;
//这两个成员只能会出现在可执行文件中
unsigned *preinit_array;
unsigned preinit_array_count;
指向初始化代码,先于main函数之行,即在加载时被linker所调用,在linker.c可以看到:__linker_init -> link_image ->
call_constructors -> call_array
unsigned *init_array;
unsigned init_array_count;
void (*init_func)(void);
//与init_array类似,只是在main结束之后执行
unsigned *fini_array;
unsigned fini_array_count;
void (*fini_func)(void);
}
另外,linker.c中也有许多地方可以佐证。其本质还是linker是基于装载视图解析的so文件的。
基于上面的结论,再来分析下ELF头的字段。
1) e_ident[EI_NIDENT] 字段包含魔数、字节序、字长和版本,后面填充0。对于安卓的linker,通过verify_elf_object函数检验魔数,判定是否为.so文件。那么,我们可以向位置写入数据,至少可以向后面的0填充位置写入数据。遗憾的是,我在fedora 14下测试,是不能向0填充位置写数据,链接器报非0填充错误。
2) 对于安卓的linker,对e_type、e_machine、e_version和e_flags字段并不关心,是可以修改成其他数据的(仅分析,没有实测)
3) 对于动态链接库,e_entry 入口地址是无意义的,因为程序被加载时,设定的跳转地址是动态连接器的地址,这个字段是可以被作为数据填充的。
4) so装载时,与链接视图没有关系,即e_shoff、e_shentsize、e_shnum和e_shstrndx这些字段是可以任意修改的。被修改之后,使用readelf和ida等工具打开,会报各种错误,相信读者已经见识过了。
5) 既然so装载与装载视图紧密相关,自然e_phoff、e_phentsize和e_phnum这些字段是不能动的。
从上面我们可以知道,so中的有些信息在运行的时候是没有用途的,有些东西是不能改的。
2、加密程序(C版)
上面说的是Java版本的,下面再来一个C版本的:
#include <stdio.h>
#include <fcntl.h>
#include "elf.h"
#include <stdlib.h>
#include <string.h>
int main(int argc, char** argv){
char *encodeSoName = "libdemo.so";
char target_section[] = ".mytext";
char *shstr = NULL;
char *content = NULL;
Elf32_Ehdr ehdr;
Elf32_Shdr shdr;
int i;
unsigned int base, length;
unsigned short nblock;
unsigned short nsize;
unsigned char block_size = 16;
int fd;
fd = open(encodeSoName, O_RDWR);
if(fd < 0){
printf("open %s failed\n", argv[1]);
goto _error;
}
if(read(fd, &ehdr, sizeof(Elf32_Ehdr)) != sizeof(Elf32_Ehdr)){
puts("Read ELF header error");
goto _error;
}
lseek(fd, ehdr.e_shoff + sizeof(Elf32_Shdr) * ehdr.e_shstrndx, SEEK_SET);
if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){
puts("Read ELF section string table error");
goto _error;
}
if((shstr = (char *) malloc(shdr.sh_size)) == NULL){
puts("Malloc space for section string table failed");
goto _error;
}
lseek(fd, shdr.sh_offset, SEEK_SET);
if(read(fd, shstr, shdr.sh_size) != shdr.sh_size){
puts("Read string table failed");
goto _error;
}
lseek(fd, ehdr.e_shoff, SEEK_SET);
for(i = 0; i < ehdr.e_shnum; i++){
if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){
puts("Find section .text procedure failed");
goto _error;
}
if(strcmp(shstr + shdr.sh_name, target_section) == 0){
base = shdr.sh_offset;
length = shdr.sh_size;
printf("Find section %s\n", target_section);
break;
}
}
lseek(fd, base, SEEK_SET);
content = (char*) malloc(length);
if(content == NULL){
puts("Malloc space for content failed");
goto _error;
}
if(read(fd, content, length) != length){
puts("Read section .text failed");
goto _error;
}
nblock = length / block_size;
nsize = length / 4096 + (length % 4096 == 0 ? 0 : 1);
printf("base = %x, length = %x\n", base, length);
printf("nblock = %d, nsize = %d\n", nblock, nsize);
printf("entry:%x\n",((length << 16) + nsize));
ehdr.e_entry = (length << 16) + nsize;
ehdr.e_shoff = base;
for(i=0;i<length;i++){
content[i] = ~content[i];
}
lseek(fd, 0, SEEK_SET);
if(write(fd, &ehdr, sizeof(Elf32_Ehdr)) != sizeof(Elf32_Ehdr)){
puts("Write ELFhead to .so failed");
goto _error;
}
lseek(fd, base, SEEK_SET);
if(write(fd, content, length) != length){
puts("Write modified content to .so failed");
goto _error;
}
puts("Completed");
_error:
free(content);
free(shstr);
close(fd);
return 0;
}
这里就不做详细解释了
我们在上面加密完成之后,我们可以验证一下,使用readelf命令查看一下: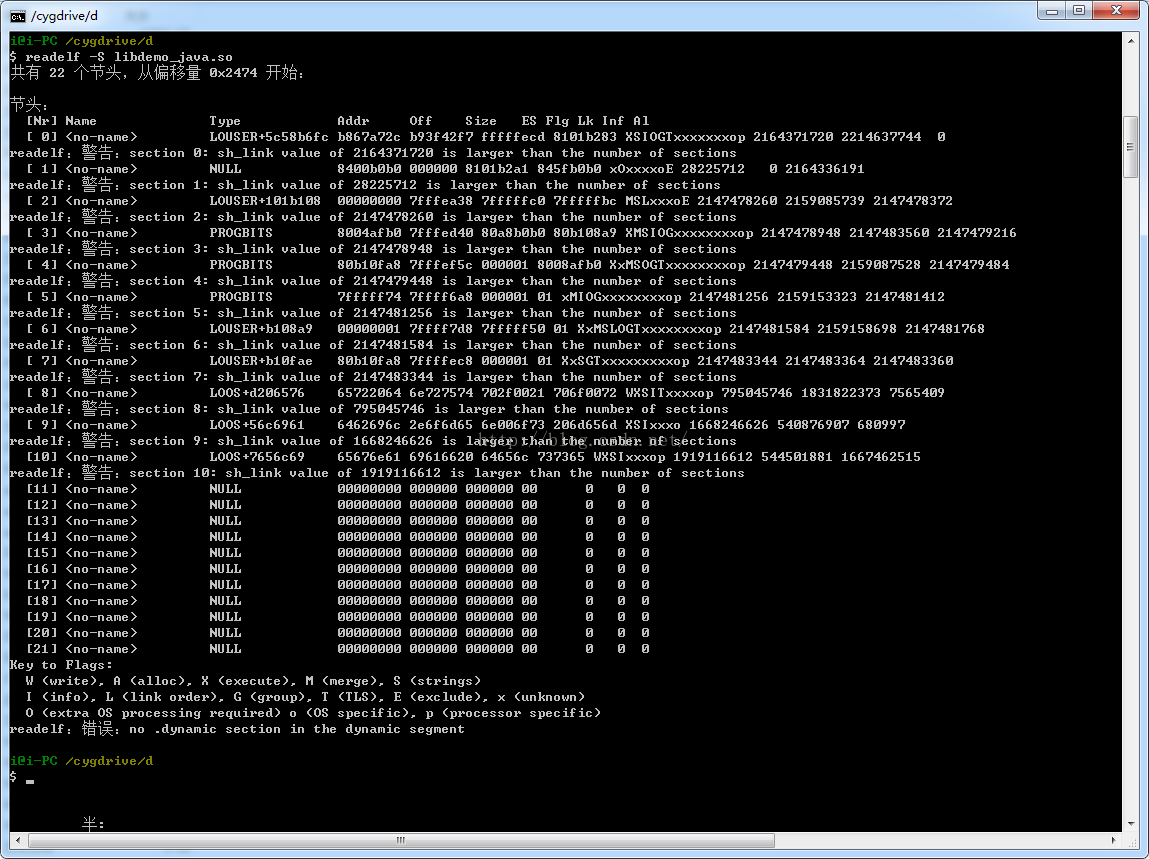
哈哈,加密成功,我们在用IDA查看一下: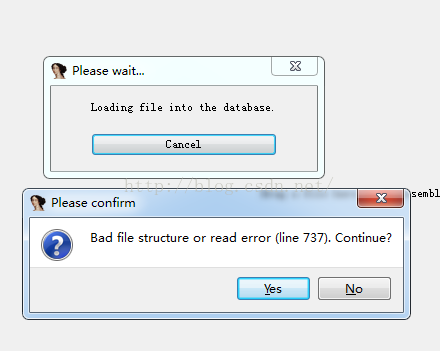
会有错误提示,但是我们点击OK,还是成功打开了so文件,但是我们ctrl+s查看段信息的时候:

也是没有看到我们的段信息,我们可以看一下我们没有加密前的效果: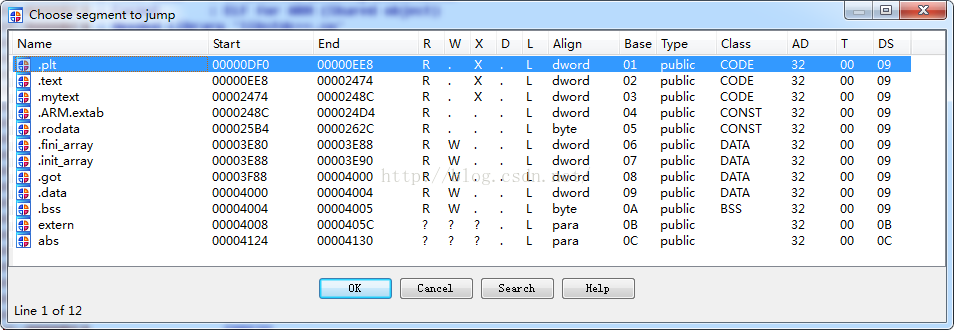
既然加密成功了,那么下面我们得验证一下能否运行成功
第三、Android测试demo
我们在获取加密之后的so文件之后,我们用Android工程测试一下:
package com.example.shelldemo;
import android.app.Activity;
import android.os.Bundle;
import android.view.Menu;
import android.view.MenuItem;
import android.widget.TextView;
public class MainActivity extends Activity {
private TextView tv;
private native String getString();
static{
System.loadLibrary("demo");
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
tv = (TextView) findViewById(R.id.tv);
tv.setText(getString());
}
}
运行结果:
看到了,运行成功了。
技术总结
1、Elf文件格式的深入了解
2、两个属性的了解:__attribute__((constructor)); __attribute__((section (".mytext")));
3、程序的maps内存映像了解
4、修改内存属性方法
5、Android系统如何解析so文件linker源码
六、梳理流程步骤
加密流程:
1) 从so文件头读取section偏移shoff、shnum和shstrtab
2) 读取shstrtab中的字符串,存放在str空间中
3) 从shoff位置开始读取section header, 存放在shdr
4) 通过shdr -> sh_name 在str字符串中索引,与.mytext进行字符串比较,如果不匹配,继续读取
5) 通过shdr -> sh_offset 和 shdr -> sh_size字段,将.mytext内容读取并保存在content中。
6) 为了便于理解,不使用复杂的加密算法。这里,只将content的所有内容取反,即 *content = ~(*content);
7) 将content内容写回so文件中
8) 为了验证第二节中关于section 字段可以任意修改的结论,这里,将shdr -> addr 写入ELF头e_shoff,将shdr -> sh_size 和 addr 所在内存块写入e_entry中,即ehdr.e_entry = (length << 16) + nsize。当然,这样同时也简化了解密流程,还有一个好处是:如果将so文件头修正放回去,程序是不能运行的。
解密时,需要保证解密函数在so加载时被调用,那函数声明为:init_getString __attribute__((constructor))。(也可以使用c++构造器实现, 其本质也是用attribute实现)
解密流程:
1) 动态链接器通过call_array调用init_getString
2) Init_getString首先调用getLibAddr方法,得到so文件在内存中的起始地址
3) 读取前52字节,即ELF头。通过e_shoff获得.mytext内存加载地址,ehdr.e_entry获取.mytext大小和所在内存块
4) 修改.mytext所在内存块的读写权限
5) 将[e_shoff, e_shoff + size]内存区域数据解密,即取反操作:*content = ~(*content);
6) 修改回内存区域的读写权限
(这里是对代码段的数据进行解密,需要写权限。如果对数据段的数据解密,是不需要更改权限直接操作的)
2、直接对目标函数进行加密
技术原理
这篇和之前的那篇文章唯一的不同点就是如何找到指定的函数的偏移地址和大小
那么我们先来了解一下so中函数的表现形式:
在so文件中,每个函数的结构描述是存放在.dynsym段中的。每个函数的名称保存在.dynstr段中的,类似于之前说过的每个section的名称都保存在.shstrtab段中,所以在前面的文章中我们找到指定段的时候,就是通过每个段的sh_name字段到.shstrtab中寻找名字即可,而且我们知道.shstrtab这个段在头文件中是有一个index的,就是在所有段列表中的索引值,所以很好定位.shstrtab.
但是在这篇文章我们可能遇到一个问题,就是不能按照这种方式去查找指定函数名了: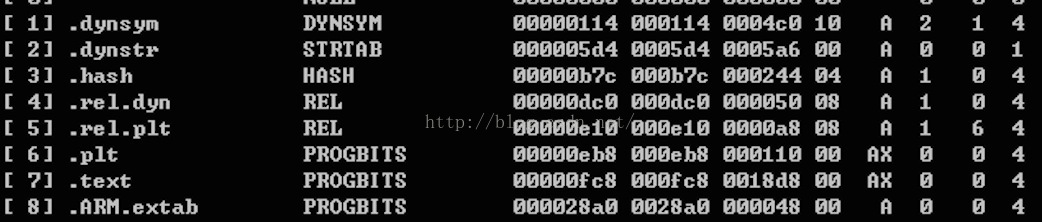
可能有的人意识到一个方法,就是我们可以通过section的type来获取.dynsym和.dynstr。我们看到上图中.dynsym类型是:DYNSYM,
.dynstr类型是STRTAB,但是这种方法是不行的,因为这个type不是唯一的,也就说不同的section,type可能相同,我们没办法区分,比如.shstrtab和.dynstr的type都是STRTAB.其实从这里我们就知道这两个段的区别了:
.shstrtab值存储段的名称,.dynstr是存储so中的所有符号名称。
那么我们该怎么办呢?这时候我们再去看一下elf的说明文档:
http://download.csdn.net/detail/jiangwei0910410003/9204051
我们看到有一个.hash段,在上图中我们也可以看到的:
由 Elf32_Word 对象组成的哈希表支持符号表访问。下面的例子有助于解释哈希表
组织,不过不是规范的一部分。bucket 数组包含 nbucket 个项目,chain 数组包含 nchain 个项目,下标都是从 0 开始。bucket 和 chain 中都保存符号表索引。Chain 表项和符号表存在对应。符号 表项的数目应该和 nchain 相等,所以符号表的索引也可用来选取 chain 表项。哈希 函数能够接受符号名并且返回一个可以用来计算 bucket 的索引。
因此,如果哈希函数针对某个名字返回了数值 X,则 bucket[X%nbucket] 给出了 一个索引 y,该索引可用于符号表,也可用于 chain 表。如果符号表项不是所需要的, 那么 chain[y] 则给出了具有相同哈希值的下一个符号表项。我们可以沿着 chain 链 一直搜索,直到所选中的符号表项包含了所需要的符号,或者 chain 项中包含值 STN_UNDEF。
上面的描述感觉有点复杂,其实说的简单点就是:
用目标函数名在用hash函数得到一个hash值,然后再做一些计算就可以得到这个函数在.dynsym段中这个函数对应的条目了。关于这个hash函数,是公用的,我们在Android中的bonic/linker.c源码中也是可以找到的:
unsigned long elf_hash (const unsigned char *name) {
unsigned long h = 0, g; while (*name)
{
h=(h<<4)+*name++; if (g = h & 0xf0000000)
h^=g>>24; h&=-g;
}
return h;
}
那么我们只要得到.hash段即可,但是我们怎么获取到这个section中呢?elf中并没有对这个段进行数据结构的描述,有人可能想到了我们在上图看到.hash段的type是HASH,那么我们再通过这个type来获取?但是之前说了,这个type不是唯一的,通过他来获取section是不靠谱的?那么我们该怎么办呢?这时候我们就要看一下程序头信息了: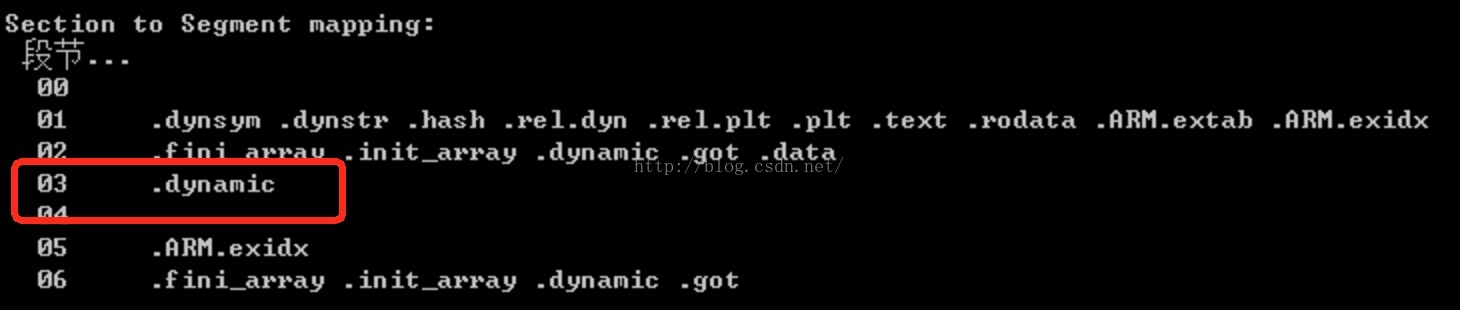
我们知道程序头信息是最后so被加载到内存中的映像描述,这里我们看到有一个.dynamic段。我们再看看so文件的装载视图和链接视图: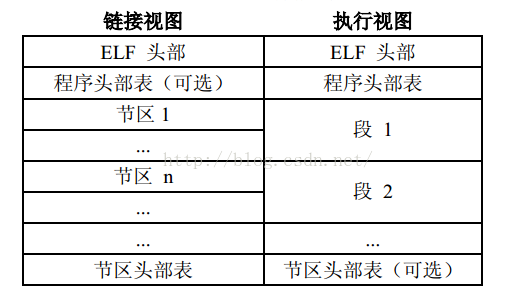
这个我们在之前也说过,在so被加载到内存之后,就没有section了,对应的是segment了,也就是程序头中描述的结构,而且一个segment可以包含多个section,相同的section可以被包含到不同的segment中。.dynamic段一般用于动态链接的,所以.dynsym和.dynstr,.hash肯定包含在这里。我们可以解析了程序头信息之后,通过type获取到.dynamic程序头信息,然后获取到这个segment的偏移地址和大小,在进行解析成elf32_dyn结构。下面两种图就是程序头的type类型和dyn结构描述,可以在elf.h中找到:
/**
* typedef struct dynamic{
Elf32_Sword d_tag;
union{
Elf32_Sword d_val;
Elf32_Addr d_ptr;
} d_un;
} Elf32_Dyn;
*/
public static class elf32_dyn{
public byte[] d_tag = new byte[4];
public byte[] d_val = new byte[4];
public byte[] d_ptr = new byte[4];
/*public static class d_un{
public static byte[] d_val = new byte[4];
public static byte[] d_ptr = new byte[4];
}*/
@Override
public String toString(){
return "d_tag:"+Utils.bytes2HexString(d_tag)+";d_un_d_val:"+Utils.bytes2HexString(d_val)+";d_un_d_ptr:"+Utils.bytes2HexString(d_ptr);
}
}
这里,需要注意的是,C语言中的union联合体结构,所以我们在Java解析的时候需要注意,后面会详细介绍。这里的三个字段很好理解:d_tag:标示,标示这个dyn是什么类型的,是.dynsym还是.dynstr等d_val:这个section的大小d_ptr:这个section的偏移地址细心的同学可能会发现一个问题,就是在这里寻找.dynamic也是通过类型的,然后再找到对应的section.这种方式和之前说的通过type来寻找section,有两个不同:第一、在程序头信息中,type标示.dynamic段是唯一的,所以可以通过type来进行寻找第二、我们看到上面的链接视图和装载视图发现,我们这种通过程序头中的信息来查找.dysym等section靠谱点,因为当so被加载到内存中,就不存在了section了,只有segment了。
实现方案
编写native程序,只是native直接返回字符串给UI。需要做的是对Java_com_example_shelldemo2_MainActivity_getString函数进行加密。加密和解密都是基于装载视图实现。需要注意的是,被加密函数如果用static声明,那么函数是不会出现在.dynsym中,是无法在装载视图中通过函数名找到进行解密的。当然,也可以采用取巧方式,类似上节,把地址和长度信息写入so头中实现。Java_com_example_shelldemo2_MainActivity_getString需要被调用,那么一定是能在.dynsym找到的。
加密流程:
1) 读取文件头,获取e_phoff、e_phentsize和e_phnum信息
2) 通过Elf32_Phdr中的p_type字段,找到DYNAMIC。从下图可以看出,其实DYNAMIC就是.dynamic section。从p_offset和p_filesz字段得到文件中的起始位置和长度
3) 遍历.dynamic,找到.dynsym、.dynstr、.hash section文件中的偏移和.dynstr的大小。在我的测试环境下,fedora 14和windows7 Cygwin x64中elf.h定义.hash的d_tag标示是:DT_GNU_HASH;而安卓源码中的是:DT_HASH。
4) 根据函数名称,计算hash值
5) 根据hash值,找到下标hash % nbuckets的bucket;根据bucket中的值,读取.dynsym中的对应索引的Elf32_Sym符号;从符号的st_name所以找到在.dynstr中对应的字符串与函数名进行比较。若不等,则根据chain[hash % nbuckets]找下一个Elf32_Sym符号,直到找到或者chain终止为止。这里叙述得有些复杂,直接上代码。
for(i = bucket[funHash % nbucket]; i != 0; i = chain[i]){
if(strcmp(dynstr + (funSym + i)->st_name, funcName) == 0){
flag = 0;
break;
}
}
6) 找到函数对应的Elf32_Sym符号后,即可根据st_value和st_size字段找到函数的位置和大小
7) 后面的步骤就和上节相同了,这里就不赘述
解密流程为加密逆过程,大体相同,只有一些细微的区别,具体如下:
1) 找到so文件在内存中的起始地址
2) 也是通过so文件头找到Phdr;从Phdr找到PT_DYNAMIC后,需取p_vaddr和p_filesz字段,并非p_offset,这里需要注意。
3) 后续操作就加密类似,就不赘述。对内存区域数据的解密,也需要注意读写权限问题。
上面就介绍了完了,下面我们就可以来开始coding了。
代码实现
第一、native程序
#include <jni.h>
#include <android/log.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <elf.h>
#include <sys/mman.h>
#define DEBUG
typedef struct _funcInfo{
Elf32_Addr st_value;
Elf32_Word st_size;
}funcInfo;
void init_getString() __attribute__((constructor));
static void print_debug(const char *msg){
#ifdef DEBUG
__android_log_print(ANDROID_LOG_INFO, "JNITag", "%s", msg);
#endif
}
static unsigned elfhash(const char *_name)
{
const unsigned char *name = (const unsigned char *) _name;
unsigned h = 0, g;
while(*name) {
h = (h << 4) + *name++;
g = h & 0xf0000000;
h ^= g;
h ^= g >> 24;
}
return h;
}
static unsigned int getLibAddr(){
unsigned int ret = 0;
char name[] = "libdemo.so";
char buf[4096], *temp;
int pid;
FILE *fp;
pid = getpid();
sprintf(buf, "/proc/%d/maps", pid);
fp = fopen(buf, "r");
if(fp == NULL)
{
puts("open failed");
goto _error;
}
while(fgets(buf, sizeof(buf), fp)){
if(strstr(buf, name)){
temp = strtok(buf, "-");
ret = strtoul(temp, NULL, 16);
break;
}
}
_error:
fclose(fp);
return ret;
}
static char getTargetFuncInfo(unsigned long base, const char *funcName, funcInfo *info){
char flag = -1, *dynstr;
int i;
Elf32_Ehdr *ehdr;
Elf32_Phdr *phdr;
Elf32_Off dyn_vaddr;
Elf32_Word dyn_size, dyn_strsz;
Elf32_Dyn *dyn;
Elf32_Addr dyn_symtab, dyn_strtab, dyn_hash;
Elf32_Sym *funSym;
unsigned funHash, nbucket;
unsigned *bucket, *chain;
ehdr = (Elf32_Ehdr *)base;
phdr = (Elf32_Phdr *)(base + ehdr->e_phoff);
// __android_log_print(ANDROID_LOG_INFO, "JNITag", "phdr = 0x%p, size = 0x%x\n", phdr, ehdr->e_phnum);
for (i = 0; i < ehdr->e_phnum; ++i) {
// __android_log_print(ANDROID_LOG_INFO, "JNITag", "phdr = 0x%p\n", phdr);
if(phdr->p_type == PT_DYNAMIC){
flag = 0;
print_debug("Find .dynamic segment");
break;
}
phdr ++;
}
if(flag)
goto _error;
dyn_vaddr = phdr->p_vaddr + base;
dyn_size = phdr->p_filesz;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "dyn_vadd = 0x%x, dyn_size = 0x%x", dyn_vaddr, dyn_size);
flag = 0;
for (i = 0; i < dyn_size / sizeof(Elf32_Dyn); ++i) {
dyn = (Elf32_Dyn *)(dyn_vaddr + i * sizeof(Elf32_Dyn));
if(dyn->d_tag == DT_SYMTAB){
dyn_symtab = (dyn->d_un).d_ptr;
flag += 1;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "Find .dynsym section, addr = 0x%x\n", dyn_symtab);
}
if(dyn->d_tag == DT_HASH){
dyn_hash = (dyn->d_un).d_ptr;
flag += 2;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "Find .hash section, addr = 0x%x\n", dyn_hash);
}
if(dyn->d_tag == DT_STRTAB){
dyn_strtab = (dyn->d_un).d_ptr;
flag += 4;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "Find .dynstr section, addr = 0x%x\n", dyn_strtab);
}
if(dyn->d_tag == DT_STRSZ){
dyn_strsz = (dyn->d_un).d_val;
flag += 8;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "Find strsz size = 0x%x\n", dyn_strsz);
}
}
if((flag & 0x0f) != 0x0f){
print_debug("Find needed .section failed\n");
goto _error;
}
dyn_symtab += base;
dyn_hash += base;
dyn_strtab += base;
dyn_strsz += base;
funHash = elfhash(funcName);
funSym = (Elf32_Sym *) dyn_symtab;
dynstr = (char*) dyn_strtab;
nbucket = *((int *) dyn_hash);
bucket = (int *)(dyn_hash + 8);
chain = (unsigned int *)(dyn_hash + 4 * (2 + nbucket));
flag = -1;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "hash = 0x%x, nbucket = 0x%x\n", funHash, nbucket);
int mod = (funHash % nbucket);
__android_log_print(ANDROID_LOG_INFO, "JNITag", "mod = %d\n", mod);
__android_log_print(ANDROID_LOG_INFO, "JNITag", "i = 0x%d\n", bucket[mod]);
for(i = bucket[mod]; i != 0; i = chain[i]){
__android_log_print(ANDROID_LOG_INFO, "JNITag", "Find index = %d\n", i);
if(strcmp(dynstr + (funSym + i)->st_name, funcName) == 0){
flag = 0;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "Find %s\n", funcName);
break;
}
}
if(flag) goto _error;
info->st_value = (funSym + i)->st_value;
info->st_size = (funSym + i)->st_size;
__android_log_print(ANDROID_LOG_INFO, "JNITag", "st_value = %d, st_size = %d", info->st_value, info->st_size);
return 0;
_error:
return -1;
}
void init_getString(){
const char target_fun[] = "Java_com_example_shelldemo2_MainActivity_getString";
funcInfo info;
int i;
unsigned int npage, base = getLibAddr();
__android_log_print(ANDROID_LOG_INFO, "JNITag", "base addr = 0x%x", base);
if(getTargetFuncInfo(base, target_fun, &info) == -1){
print_debug("Find Java_com_example_shelldemo2_MainActivity_getString failed");
return ;
}
npage = info.st_size / PAGE_SIZE + ((info.st_size % PAGE_SIZE == 0) ? 0 : 1);
__android_log_print(ANDROID_LOG_INFO, "JNITag", "npage = 0x%d", npage);
__android_log_print(ANDROID_LOG_INFO, "JNITag", "npage = 0x%d", PAGE_SIZE);
if(mprotect((void *) ((base + info.st_value) / PAGE_SIZE * PAGE_SIZE), 4096*npage, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){
print_debug("mem privilege change failed");
}
for(i=0;i< info.st_size - 1; i++){
char *addr = (char*)(base + info.st_value -1 + i);
*addr = ~(*addr);
}
if(mprotect((void *) ((base + info.st_value) / PAGE_SIZE * PAGE_SIZE), 4096*npage, PROT_READ | PROT_EXEC) != 0){
print_debug("mem privilege change failed");
}
}
JNIEXPORT jstring JNICALL
Java_com_example_shelldemo2_MainActivity_getString( JNIEnv* env,
jobject thiz )
{
#if defined(__arm__)
#if defined(__ARM_ARCH_7A__)
#if defined(__ARM_NEON__)
#define ABI "armeabi-v7a/NEON"
#else
#define ABI "armeabi-v7a"
#endif
#else
#define ABI "armeabi"
#endif
#elif defined(__i386__)
#define ABI "x86"
#elif defined(__mips__)
#define ABI "mips"
#else
#define ABI "unknown"
#endif
return (*env)->NewStringUTF(env, "Native method return!");
}
这里就不想做太多解释了,代码逻辑和之前文章中的加密section中的代码类似,只有在寻找函数的地方有点不同,这个也不再这里说明了,在加密的代码中我在说明一下。
第二、加密程序1、Java版本加密程序
private static void encodeFunc(byte[] fileByteArys){
//寻找Dynamic段的偏移值和大小
int dy_offset = 0,dy_size = 0;
for(elf32_phdr phdr : type_32.phdrList){
if(Utils.byte2Int(phdr.p_type) == ElfType32.PT_DYNAMIC){
dy_offset = Utils.byte2Int(phdr.p_offset);
dy_size = Utils.byte2Int(phdr.p_filesz);
}
}
System.out.println("dy_size:"+dy_size);
int dynSize = 8;
int size = dy_size / dynSize;
System.out.println("size:"+size);
byte[] dest = new byte[dynSize];
for(int i=0;i<size;i++){
System.arraycopy(fileByteArys, i*dynSize + dy_offset, dest, 0, dynSize);
type_32.dynList.add(parseDynamic(dest));
}
//type_32.printDynList();
byte[] symbolStr = null;
int strSize=0,strOffset=0;
int symbolOffset = 0;
int dynHashOffset = 0;
int funcIndex = 0;
int symbolSize = 16;
for(elf32_dyn dyn : type_32.dynList){
if(Utils.byte2Int(dyn.d_tag) == ElfType32.DT_HASH){
dynHashOffset = Utils.byte2Int(dyn.d_ptr);
}else if(Utils.byte2Int(dyn.d_tag) == ElfType32.DT_STRTAB){
System.out.println("strtab:"+dyn);
strOffset = Utils.byte2Int(dyn.d_ptr);
}else if(Utils.byte2Int(dyn.d_tag) == ElfType32.DT_SYMTAB){
System.out.println("systab:"+dyn);
symbolOffset = Utils.byte2Int(dyn.d_ptr);
}else if(Utils.byte2Int(dyn.d_tag) == ElfType32.DT_STRSZ){
System.out.println("strsz:"+dyn);
strSize = Utils.byte2Int(dyn.d_val);
}
}
symbolStr = Utils.copyBytes(fileByteArys, strOffset, strSize);
//打印所有的Symbol Name,注意用0来进行分割,C中的字符串都是用0做结尾的
/*String[] strAry = new String(symbolStr).split(new String(new byte[]{0}));
for(String str : strAry){
System.out.println(str);
}*/
for(elf32_dyn dyn : type_32.dynList){
if(Utils.byte2Int(dyn.d_tag) == ElfType32.DT_HASH){
//这里的逻辑有点绕
/**
* 根据hash值,找到下标hash % nbuckets的bucket;根据bucket中的值,读取.dynsym中的对应索引的Elf32_Sym符号;
* 从符号的st_name所以找到在.dynstr中对应的字符串与函数名进行比较。若不等,则根据chain[hash % nbuckets]找下一个Elf32_Sym符号,
* 直到找到或者chain终止为止。这里叙述得有些复杂,直接上代码。
for(i = bucket[funHash % nbucket]; i != 0; i = chain[i]){
if(strcmp(dynstr + (funSym + i)->st_name, funcName) == 0){
flag = 0;
break;
}
}
*/
int nbucket = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset, 4));
int nchian = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset+4, 4));
int hash = (int)elfhash(funcName.getBytes());
hash = (hash % nbucket);
//这里的8是读取nbucket和nchian的两个值
funcIndex = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset+hash*4 + 8, 4));
System.out.println("nbucket:"+nbucket+",hash:"+hash+",funcIndex:"+funcIndex+",chian:"+nchian);
System.out.println("sym:"+Utils.bytes2HexString(Utils.int2Byte(symbolOffset)));
System.out.println("hash:"+Utils.bytes2HexString(Utils.int2Byte(dynHashOffset)));
byte[] des = new byte[symbolSize];
System.arraycopy(fileByteArys, symbolOffset+funcIndex*symbolSize, des, 0, symbolSize);
Elf32_Sym sym = parseSymbolTable(des);
System.out.println("sym:"+sym);
boolean isFindFunc = Utils.isEqualByteAry(symbolStr, Utils.byte2Int(sym.st_name), funcName);
if(isFindFunc){
System.out.println("find func....");
return;
}
while(true){
/**
* lseek(fd, dyn_hash + 4 * (2 + nbucket + funIndex), SEEK_SET);
if(read(fd, &funIndex, 4) != 4){
puts("Read funIndex failed\n");
goto _error;
}
*/
//System.out.println("dyHash:"+Utils.bytes2HexString(Utils.int2Byte(dynHashOffset))+",nbucket:"+nbucket+",funIndex:"+funcIndex);
funcIndex = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset+4*(2+nbucket+funcIndex), 4));
System.out.println("funcIndex:"+funcIndex);
System.arraycopy(fileByteArys, symbolOffset+funcIndex*symbolSize, des, 0, symbolSize);
sym = parseSymbolTable(des);
isFindFunc = Utils.isEqualByteAry(symbolStr, Utils.byte2Int(sym.st_name), funcName);
if(isFindFunc){
System.out.println("find func...");
int funcSize = Utils.byte2Int(sym.st_size);
int funcOffset = Utils.byte2Int(sym.st_value);
System.out.println("size:"+funcSize+",funcOffset:"+funcOffset);
//进行目标函数代码部分进行加密
//这里需要注意的是从funcOffset-1的位置开始
byte[] funcAry = Utils.copyBytes(fileByteArys, funcOffset-1, funcSize);
for(int i=0;i<funcAry.length-1;i++){
funcAry[i] = (byte)(funcAry[i] ^ 0xFF);
}
Utils.replaceByteAry(fileByteArys, funcOffset-1, funcAry);
break;
}
}
break;
}
}
}
这里的解密程序,需要说明一下。1)、定位到.dynamic的segment,解析成elf32_dyn结构信息
//寻找Dynamic段的偏移值和大小
int dy_offset = 0,dy_size = 0;
for(elf32_phdr phdr : type_32.phdrList){
if(Utils.byte2Int(phdr.p_type) == ElfType32.PT_DYNAMIC){
dy_offset = Utils.byte2Int(phdr.p_offset);
dy_size = Utils.byte2Int(phdr.p_filesz);
}
}
System.out.println("dy_size:"+dy_size);
int dynSize = 8;
int size = dy_size / dynSize;
System.out.println("size:"+size);
byte[] dest = new byte[dynSize];
for(int i=0;i<size;i++){
System.arraycopy(fileByteArys, i*dynSize + dy_offset, dest, 0, dynSize);
type_32.dynList.add(parseDynamic(dest));
}
这里有一个解析elf32_dyn结构:
[cpp] view plaincopy
private static elf32_dyn parseDynamic(byte[] src){
elf32_dyn dyn = new elf32_dyn();
dyn.d_tag = Utils.copyBytes(src, 0, 4);
dyn.d_ptr = Utils.copyBytes(src, 4, 4);
dyn.d_val = Utils.copyBytes(src, 4, 4);
return dyn;
}
这里需要注意的是,elf32_dyn中用到了联合体union结构,Java中是不存在这个类型的,所以我们需要了解这个联合体的含义,这里虽然是三个字段,但是大小是8个字节,而不是12字节,这个需要注意的。dyn.d_val和dyn.d_val是在一个联合体中的。2)、计算目标函数的hash值,得到函数的偏移值和大小
[java] view plaincopy
for(elf32_dyn dyn : type_32.dynList){
if(Utils.byte2Int(dyn.d_tag) == ElfType32.DT_HASH){
//这里的逻辑有点绕
/**
* 根据hash值,找到下标hash % nbuckets的bucket;根据bucket中的值,读取.dynsym中的对应索引的Elf32_Sym符号;
* 从符号的st_name所以找到在.dynstr中对应的字符串与函数名进行比较。若不等,则根据chain[hash % nbuckets]找下一个Elf32_Sym符号,
* 直到找到或者chain终止为止。这里叙述得有些复杂,直接上代码。
for(i = bucket[funHash % nbucket]; i != 0; i = chain[i]){
if(strcmp(dynstr + (funSym + i)->st_name, funcName) == 0){
flag = 0;
break;
}
}
*/
int nbucket = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset, 4));
int nchian = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset+4, 4));
int hash = (int)elfhash(funcName.getBytes());
hash = (hash % nbucket);
//这里的8是读取nbucket和nchian的两个值
funcIndex = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset+hash*4 + 8, 4));
System.out.println("nbucket:"+nbucket+",hash:"+hash+",funcIndex:"+funcIndex+",chian:"+nchian);
System.out.println("sym:"+Utils.bytes2HexString(Utils.int2Byte(symbolOffset)));
System.out.println("hash:"+Utils.bytes2HexString(Utils.int2Byte(dynHashOffset)));
byte[] des = new byte[symbolSize];
System.arraycopy(fileByteArys, symbolOffset+funcIndex*symbolSize, des, 0, symbolSize);
Elf32_Sym sym = parseSymbolTable(des);
System.out.println("sym:"+sym);
boolean isFindFunc = Utils.isEqualByteAry(symbolStr, Utils.byte2Int(sym.st_name), funcName);
if(isFindFunc){
System.out.println("find func....");
return;
}
while(true){
/**
* lseek(fd, dyn_hash + 4 * (2 + nbucket + funIndex), SEEK_SET);
if(read(fd, &funIndex, 4) != 4){
puts("Read funIndex failed\n");
goto _error;
}
*/
//System.out.println("dyHash:"+Utils.bytes2HexString(Utils.int2Byte(dynHashOffset))+",nbucket:"+nbucket+",funIndex:"+funcIndex);
funcIndex = Utils.byte2Int(Utils.copyBytes(fileByteArys, dynHashOffset+4*(2+nbucket+funcIndex), 4));
System.out.println("funcIndex:"+funcIndex);
System.arraycopy(fileByteArys, symbolOffset+funcIndex*symbolSize, des, 0, symbolSize);
sym = parseSymbolTable(des);
isFindFunc = Utils.isEqualByteAry(symbolStr, Utils.byte2Int(sym.st_name), funcName);
if(isFindFunc){
System.out.println("find func...");
int funcSize = Utils.byte2Int(sym.st_size);
int funcOffset = Utils.byte2Int(sym.st_value);
System.out.println("size:"+funcSize+",funcOffset:"+funcOffset);
//进行目标函数代码部分进行加密
//这里需要注意的是从funcOffset-1的位置开始
byte[] funcAry = Utils.copyBytes(fileByteArys, funcOffset-1, funcSize);
for(int i=0;i<funcAry.length-1;i++){
funcAry[i] = (byte)(funcAry[i] ^ 0xFF);
}
Utils.replaceByteAry(fileByteArys, funcOffset-1, funcAry);
break;
}
}
break;
}
}
这里的寻找逻辑有点饶人,但是我们知道了解原理即可:
结合上面的这张图就可以理解了。其中nbucket和nchain,bucket[i]和chain[i]都是4个字节。他们的值就是目标函数在.dynsym中的位置。
2、C版加密程序
#include <stdio.h>
#include <fcntl.h>
#include "elf.h"
#include <stdlib.h>
#include <string.h>
typedef struct _funcInfo{
Elf32_Addr st_value;
Elf32_Word st_size;
}funcInfo;
Elf32_Ehdr ehdr;
//For Test
static void print_all(char *str, int len){
int i;
for(i=0;i<len;i++)
{
if(str[i] == 0)
puts("");
else
printf("%c", str[i]);
}
}
static unsigned elfhash(const char *_name)
{
const unsigned char *name = (const unsigned char *) _name;
unsigned h = 0, g;
while(*name) {
h = (h << 4) + *name++;
g = h & 0xf0000000;
h ^= g;
h ^= g >> 24;
}
return h;
}
static Elf32_Off findTargetSectionAddr(const int fd, const char *secName){
Elf32_Shdr shdr;
char *shstr = NULL;
int i;
lseek(fd, 0, SEEK_SET);
if(read(fd, &ehdr, sizeof(Elf32_Ehdr)) != sizeof(Elf32_Ehdr)){
puts("Read ELF header error");
goto _error;
}
lseek(fd, ehdr.e_shoff + sizeof(Elf32_Shdr) * ehdr.e_shstrndx, SEEK_SET);
if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){
puts("Read ELF section string table error");
goto _error;
}
if((shstr = (char *) malloc(shdr.sh_size)) == NULL){
puts("Malloc space for section string table failed");
goto _error;
}
lseek(fd, shdr.sh_offset, SEEK_SET);
if(read(fd, shstr, shdr.sh_size) != shdr.sh_size){
puts(shstr);
puts("Read string table failed");
goto _error;
}
lseek(fd, ehdr.e_shoff, SEEK_SET);
for(i = 0; i < ehdr.e_shnum; i++){
if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){
puts("Find section .text procedure failed");
goto _error;
}
if(strcmp(shstr + shdr.sh_name, secName) == 0){
printf("Find section %s, addr = 0x%x\n", secName, shdr.sh_offset);
break;
}
}
free(shstr);
return shdr.sh_offset;
_error:
return -1;
}
static char getTargetFuncInfo(int fd, const char *funcName, funcInfo *info){
char flag = -1, *dynstr;
int i;
Elf32_Sym funSym;
Elf32_Phdr phdr;
Elf32_Off dyn_off;
Elf32_Word dyn_size, dyn_strsz;
Elf32_Dyn dyn;
Elf32_Addr dyn_symtab, dyn_strtab, dyn_hash;
unsigned funHash, nbucket, nchain, funIndex;
lseek(fd, ehdr.e_phoff, SEEK_SET);
for(i=0;i < ehdr.e_phnum; i++){
if(read(fd, &phdr, sizeof(Elf32_Phdr)) != sizeof(Elf32_Phdr)){
puts("Read segment failed");
goto _error;
}
if(phdr.p_type == PT_DYNAMIC){
dyn_size = phdr.p_filesz;
dyn_off = phdr.p_offset;
flag = 0;
printf("Find section %s, size = 0x%x, addr = 0x%x\n", ".dynamic", dyn_size, dyn_off);
break;
}
}
if(flag){
puts("Find .dynamic failed");
goto _error;
}
flag = 0;
printf("dyn_size:%d\n",dyn_size);
printf("count:%d\n",(dyn_size/sizeof(Elf32_Dyn)));
printf("off:%x\n",dyn_off);
lseek(fd, dyn_off, SEEK_SET);
for(i=0;i < dyn_size / sizeof(Elf32_Dyn); i++){
int sizes = read(fd, &dyn, sizeof(Elf32_Dyn));
if(sizes != sizeof(Elf32_Dyn)){
puts("Read .dynamic information failed");
//goto _error;
break;
}
if(dyn.d_tag == DT_SYMTAB){
dyn_symtab = dyn.d_un.d_ptr;
flag += 1;
printf("Find .dynsym, addr = 0x%x, val = 0x%x\n", dyn_symtab, dyn.d_un.d_val);
}
if(dyn.d_tag == DT_HASH){
dyn_hash = dyn.d_un.d_ptr;
flag += 2;
printf("Find .hash, addr = 0x%x\n", dyn_hash);
}
if(dyn.d_tag == DT_STRTAB){
dyn_strtab = dyn.d_un.d_ptr;
flag += 4;
printf("Find .dynstr, addr = 0x%x\n", dyn_strtab);
}
if(dyn.d_tag == DT_STRSZ){
dyn_strsz = dyn.d_un.d_val;
flag += 8;
printf("Find .dynstr size, size = 0x%x\n", dyn_strsz);
}
}
if((flag & 0x0f) != 0x0f){
puts("Find needed .section failed\n");
goto _error;
}
dynstr = (char*) malloc(dyn_strsz);
if(dynstr == NULL){
puts("Malloc .dynstr space failed");
goto _error;
}
lseek(fd, dyn_strtab, SEEK_SET);
if(read(fd, dynstr, dyn_strsz) != dyn_strsz){
puts("Read .dynstr failed");
goto _error;
}
funHash = elfhash(funcName);
printf("Function %s hashVal = 0x%x\n", funcName, funHash);
lseek(fd, dyn_hash, SEEK_SET);
if(read(fd, &nbucket, 4) != 4){
puts("Read hash nbucket failed\n");
goto _error;
}
printf("nbucket = %d\n", nbucket);
if(read(fd, &nchain, 4) != 4){
puts("Read hash nchain failed\n");
goto _error;
}
printf("nchain = %d\n", nchain);
funHash = funHash % nbucket;
printf("funHash mod nbucket = %d \n", funHash);
lseek(fd, funHash * 4, SEEK_CUR);
if(read(fd, &funIndex, 4) != 4){
puts("Read funIndex failed\n");
goto _error;
}
printf("funcIndex:%d\n", funIndex);
lseek(fd, dyn_symtab + funIndex * sizeof(Elf32_Sym), SEEK_SET);
if(read(fd, &funSym, sizeof(Elf32_Sym)) != sizeof(Elf32_Sym)){
puts("Read funSym failed");
goto _error;
}
if(strcmp(dynstr + funSym.st_name, funcName) != 0){
while(1){
printf("hash:%x,nbucket:%d,funIndex:%d\n",dyn_hash,nbucket,funIndex);
lseek(fd, dyn_hash + 4 * (2 + nbucket + funIndex), SEEK_SET);
if(read(fd, &funIndex, 4) != 4){
puts("Read funIndex failed\n");
goto _error;
}
printf("funcIndex:%d\n", funIndex);
if(funIndex == 0){
puts("Cannot find funtion!\n");
goto _error;
}
lseek(fd, dyn_symtab + funIndex * sizeof(Elf32_Sym), SEEK_SET);
if(read(fd, &funSym, sizeof(Elf32_Sym)) != sizeof(Elf32_Sym)){
puts("In FOR loop, Read funSym failed");
goto _error;
}
if(strcmp(dynstr + funSym.st_name, funcName) == 0){
break;
}
}
}
printf("Find: %s, offset = 0x%x, size = 0x%x\n", funcName, funSym.st_value, funSym.st_size);
info->st_value = funSym.st_value;
info->st_size = funSym.st_size;
free(dynstr);
return 0;
_error:
free(dynstr);
return -1;
}
int main(int argc, char **argv){
char secName[] = ".text";
char funcName[] = "Java_com_example_shelldemo2_MainActivity_getString";
char *soName = "libdemo.so";
char *content = NULL;
int fd, i;
Elf32_Off secOff;
funcInfo info;
unsigned a = elfhash(funcName);
printf("a:%d\n", a);
fd = open(soName, O_RDWR);
if(fd < 0){
printf("open %s failed\n", argv[1]);
goto _error;
}
secOff = findTargetSectionAddr(fd, secName);
if(secOff == -1){
printf("Find section %s failed\n", secName);
goto _error;
}
if(getTargetFuncInfo(fd, funcName, &info) == -1){
printf("Find function %s failed\n", funcName);
goto _error;
}
content = (char*) malloc(info.st_size);
if(content == NULL){
puts("Malloc space failed");
goto _error;
}
lseek(fd, info.st_value - 1, SEEK_SET);
if(read(fd, content, info.st_size) != info.st_size){
puts("Malloc space failed");
goto _error;
}
for(i=0;i<info.st_size -1;i++){
content[i] = ~content[i];
}
lseek(fd, info.st_value-1, SEEK_SET);
if(write(fd, content, info.st_size) != info.st_size){
puts("Write modified content to .so failed");
goto _error;
}
puts("Complete!");
_error:
free(content);
close(fd);
return 0;
}
这里就不做介绍了。
上面对so中的函数加密成功了,那么下面我们来验证加密,我们使用IDA进行查看:
看到我们加密的函数内容已经面目全非了,看不到信息了。比较加密前的:

哈哈,加密成功了~~
第三、测试Android项目我们用加密之后的so文件来测试一下:
package com.example.shelldemo;
import android.app.Activity;
import android.os.Bundle;
import android.view.Menu;
import android.view.MenuItem;
import android.widget.TextView;
public class MainActivity extends Activity {
private TextView tv;
private native String getString();
static{
System.loadLibrary("demo");
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
tv = (TextView) findViewById(R.id.tv);
tv.setText(getString());
}
}
运行结果:

运行成功啦。
这里详细介绍了具体的实现方案和原理,这里就不做太多的介绍了,后续我将开始介绍破解的相关知识,那时候我们会发现,我们做的这些加固其实并没有什么卵用,所以在研究逆向的时候,弄不好会变疯的,因为在你研究完了加固之后,还要去破解它,没有绝对的安全,只有相对的攻防。
相关文章
js URLdecode()与urlencode方法支持中文解码
下面来介绍在js中来利用urlencode对中文编码与接受到数据后利用URLdecode()对编码进行解码,有需要学习的机友可参考参考。 代码如下 复制代码 ...2016-09-20使用PHP+JavaScript将HTML页面转换为图片的实例分享
这篇文章主要介绍了使用PHP+JavaScript将HTML元素转换为图片的实例分享,文后结果的截图只能体现出替换的字体,也不能说将静态页面转为图片可以加快加载,只是这种做法比较interesting XD需要的朋友可以参考下...2016-04-19- 在开发过程中,我们经常会将日期时间的毫秒数存放到数据库,但是它对应的时间看起来就十分不方便,我们可以使用一些函数将毫秒转换成date格式。 一、 在MySQL中,有内置的函数from_unixtime()来做相应的转换,使用如下: 复制...2014-05-31
- 今天在写一个vbs的时候,发现中文乱码,后来写好代码正常运行的代码压缩一下给了同事,发现报无效字符,经过验证后发现原来是编码的问题导致,这里就为大家分享一下...2020-06-30
- 这篇文章主要介绍了Javascript类型转换的规则实例解析,涉及到javascript类型转换相关知识,对本文感兴趣的朋友一起学习吧...2016-02-27
- 今天小编在这里就来给美图秀秀的这一款软件的使用者们来说下把普通照片快速转换成卡通效果的教程,各位想知道具体制作步骤的使用者们,那么下面就快阿里跟着小编一起看一...2016-09-14
关于Mysql中文乱码问题该如何解决(乱码问题完美解决方案)
最近两天做项目总是被乱码问题困扰着,这不刚把mysql中文乱码问题解决了,下面小编把我的解决方案分享给大家,供大家参考,也方便以后自己查阅。首先:用show variables like “%colla%”;show varables like “%char%”;这两条...2015-11-24- 这篇文章主要介绍了C#读取中文文件出现乱码的解决方法,涉及C#中文编码的操作技巧,非常具有实用价值,需要的朋友可以参考下...2020-06-25
- 在debian环境下,彻底解决mysql无法插入和显示中文的问题Linux下Mysql插入中文显示乱码解决方案mysql -uroot -p 回车输入密码进入mysql查看状态如下:默认的是客户端和服务器都用了latin1,所以会乱码。解决方案:mysql>use...2013-10-04
- 一.mysql默认不支持中文,它的server和db默认是latin1编码.所以我们要将其改变为utf-8编码,因为utf-8包含了地球上大部分语言的二进制编码 1.关闭mysql服务 sudo /etc/init.d/mysql stop 2.修改mysql配置文件 mysql配...2015-10-21
- 我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B。...2015-03-15
- 小编分享了一段简单的php中文转拼音的实现代码,代码简单易懂,适合初学php的同学参考学习。 代码如下 复制代码 <?phpfunction Pinyin($_String...2017-07-06
- 本篇文章是对C#中数据类型转换的几种形式进行了详细的分析介绍,需要的朋友参考下...2020-06-25
PHP编码转换函数mb_convert_encoding与iconv用法
文章来实现一个PHP编码转换函数mb_convert_encoding与iconv用法,希望例子能帮助到各位。 将一个短信接口代码从apache迁移到nginx+php-fpm后,发现无法发出短信了,查...2016-11-25- 这篇文章主要介绍了c#的类型转换详解,类型转换分两种形式:隐式转换、显示转换,下面是详细介绍...2020-06-25
- 这篇文章主要为大家详细介绍了JavaScript实现数据类型的相互转换,感兴趣的朋友可以参考一下...2016-03-09
- 这篇文章主要介绍了JavaScript实现Base64编码转换的相关资料,非常简单实用,需要的朋友可以参考下...2016-04-25
- 这篇文章主要介绍了Java连接数据库oracle中文乱码解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-05-16
- 这篇文章主要介绍了C#将数字转换成字节数组的方法,涉及C#字符串操作的技巧,非常具有实用价值,需要的朋友可以参考下...2020-06-25
java中JSONObject转换为HashMap(方法+main方法调用实例)
这篇文章主要介绍了java中JSONObject转换为HashMap(方法+main方法调用实例),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-14