PHP中排列组合及性能对比
需求是这样的:
找到数组中所有可能的指定长度的组合,要求没有重复。
方法一:
| 代码如下 | 复制代码 |
|
function getCombinationToString($arr,$m){ $temp_list2 = getCombinationToString($arr, $m); var_dump($t); |
|
执行时间:238ms。
方法二:
| 代码如下 | 复制代码 |
|
function getCombinAryByNum( $arr, $num,$t=array()) { $arr = array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18); var_dump($ss); |
|
执行时间:710ms。
提取内容是一个比较有意思的项目了,今天要做一个这样的小搜索引擎了,下面小编就给各位介绍一个php提取网页正文内容的例子,希望能给各位带来帮助。Html2Article-php实现的提取网页正文部分,最近研究百度结果页的资讯采集,其中关键环节就是从采集回的页面中提取出文章。
因为难点在于如何去识别并保留网页中的文章部分,而且删除其它无用的信息,并且要做到通用化,不能像火车头那样根据目标站来制定采集规则,因为搜索引擎结果中有各种的网页。
抓回一个页面的数据,如何匹配出正文部分,郑晓在下班路上想了个思路是:
1. 提取出body标签部分–>剔除所有链接–>剔除所有script、注释–>剔除所有空白标签(包括标签内不含中文的)–>获取结果。
2. 直接匹配出非链接的、 符合在div、p、h标签中的中文部分???
还是会有不少其它多余信息啊,比如底部信息等。。 如何搞?不知道大家有木有什么思路或建议?
这个类是从网上找到的一个php实现的提取网页正文部分的算法,郑晓在本地也测试了下,准确率非常高。
| 代码如下 | 复制代码 |
|
<?php class Readability { // DOM 解析类目前只支持 UTF-8 编码 // 当判定失败时显示的内容 // DOM 解析类(PHP5 已内置) // 需要解析的源代码 // 章节的父元素列表 // 需要删除的标签 private $junkTags = Array("style", "form", "iframe", "script", "button", "input", "textarea", // 需要删除的属性
// DOM 解析类只能处理 UTF-8 格式的字符 // 预处理 HTML 标签,剔除冗余的标签等 // 生成 DOM 解析类 foreach ($this->DOM->childNodes as $item) { // insert proper
// Replace all doubled-up <BR> tags with <P> tags, and remove fonts. // @see https://github.com/feelinglucky/php-readability/issues/7 return trim($string);
/** $i = 0; return $RootNode; /** // Study all the paragraphs and find the chunk that has the best score. // Look for a special classname // Look for a special ID // Add a point for the paragraph found // 保存父元素的判定得分 // 保存章节的父元素,以便下次快速获取 $topBox = null; if ($contentScore && $contentScore > $orgContentScore) {
if ($titleNodes->length return null;
if ($images->length && $leadImage = $images->item(0)) { return null;
// 获取页面标题 // 获取页面主内容 // 删除不需要的标签 // 删除不需要的属性 $content = mb_convert_encoding($Target->saveHTML(), Readability::DOM_DEFAULT_CHARSET, "HTML-ENTITIES"); // 多个数据,以数组的形式返回 function __destruct() { } |
|
使用起来也非常简单,实例化时传入网页的html源码和相应的编码,然后直接调用其getContent方法即可返回提取到的正文部分,提取出的文章中可能还会含有少部分链接,可以自己后期再修改
必要条件:
appid //公众号后台开发者中心获得(和邮件内的一样) mchid//邮件内获得 key//商户后台自己设置 appsecret //公众号开发者中心获得
两个证书文件,邮件内获得 apiclient_cert.pem apiclient_key.pem
注意事项:
公众号后台微信支付-》开发配置-》新增测试目录和测试个人微信号。
开发者中心-》网页授权获取用户基本信息-》修改成你的测试域名。否则会出现redirect_uri 参数错误
——————————后续待完善——————-
微信支付就绪页面后台自行了三次操作:
1.获取openid
//使用jsapi接口
| 代码如下 | 复制代码 |
| $jsApi = new JsApi_pub(); //=========步骤1:网页授权获取用户openid============ //通过code获得openid if (!isset($_GET['code'])) { //触发微信返回code码 $url = $jsApi->createOauthUrlForCode(WxPayConf_pub::JS_API_CALL_URL); //echo $url; Header("Location: $url"); }else { //获取code码,以获取openid $code = $_GET['code']; $jsApi->setCode($code); $openid = $jsApi->getOpenid(); } |
|
刚开始的时候第一步也遇到问题,没饭获得openid这个和部分服务器有关,demo内用的是curl获取的方式。奇怪我的服务器curl一直无法获取到。后来改成file_get_contents可以正常获取了。可这并不是解决之道。因为后面还需要用到更多的curl操作。看到开发文档里面有一个地方写证书操作需要libcurl 7.20.1以上版本,然后我就一直在整服务器想把linux的php curl版本提高。最后面我是换到了另外一台windows服务器就好了。先暂时这样吧,下次需要用的时候再调试。
第二步:获取与支付订单号id
| 代码如下 | 复制代码 |
| $unifiedOrder = new UnifiedOrder_pub(); //var_dump($unifiedOrder); //设置统一支付接口参数 //设置必填参数 //appid已填,商户无需重复填写 //mch_id已填,商户无需重复填写 //noncestr已填,商户无需重复填写 //spbill_create_ip已填,商户无需重复填写 //sign已填,商户无需重复填写 $unifiedOrder->setParameter("openid","$openid");//商品描述 $unifiedOrder->setParameter("body","贡献一分钱");//商品描述 //自定义订单号,此处仅作举例 $timeStamp = time(); $out_trade_no = WxPayConf_pub::APPID."$timeStamp"; $unifiedOrder->setParameter("out_trade_no","$out_trade_no");//商户订单号 $unifiedOrder->setParameter("total_fee","1");//总金额 $unifiedOrder->setParameter("notify_url",WxPayConf_pub::NOTIFY_URL);//通知地址 $unifiedOrder->setParameter("trade_type","JSAPI");//交易类型 //非必填参数,商户可根据实际情况选填 //$unifiedOrder->setParameter("sub_mch_id","XXXX");//子商户号 //$unifiedOrder->setParameter("device_info","XXXX");//设备号 //$unifiedOrder->setParameter("attach","XXXX");//附加数据 //$unifiedOrder->setParameter("time_start","XXXX");//交易起始时间 //$unifiedOrder->setParameter("time_expire","XXXX");//交易结束时间 //$unifiedOrder->setParameter("goods_tag","XXXX");//商品标记 //$unifiedOrder->setParameter("openid","XXXX");//用户标识 //$unifiedOrder->setParameter("product_id","XXXX");//商品ID $prepay_id = $unifiedOrder->getPrepayId(); //echo 'prepay_id:'; var_dump($prepay_id); |
|
这一步也遇到非常多的问题。
首先微信支付测试比较困难,只有在微信内才可以测试。我就用手机刷来刷去。其次使用var_dump调试也不好使额。打印一些 xml格式的文件只显示字符长度,不显示内容。于是用log的形式写在服务器上调试,log代码:
| 代码如下 | 复制代码 |
| // 打印log function log_d($word) { $log_name="./logd.log";//log文件路径 $fp = fopen($log_name,"a"); flock($fp, LOCK_EX) ; fwrite($fp,"执行日期:".strftime("%Y-%m-%d-%H:%M:%S",time())."n".$word."nn"); flock($fp, LOCK_UN); fclose($fp); } |
|
在demo里面的 WxPayPubHelper.php 里面 用 $this->log_d(xxx);调用。
刚开始的时候由于给我的mchid和 appid不匹配一直报错。。是他们给错我账号了。刚开始我也不懂乱试。这一步的调试在 getPrepayId()内 var_dump($this->result); 就能看到错误代码。
第三步:生成支付前端 js代码就绪到网页上:
| 代码如下 | 复制代码 |
| $jsApi->setPrepayId($prepay_id); $jsApiParameters = $jsApi->getParameters(); ———————-点击前往支付————————- |
|
这部分又遇到了问题:
android返回“System:Access_denied”,ios返回”access_control:not_allowed”
搜了很多百度。其实早就看到了这个东西一直没注意!
发起授权请求的页面必须是在授权目录下的页面,而不能是存在与子目录中。否则会返回错误
支付文件我放在了/域名/pay/demo/
刚开始的时候我一直是到/域名/pay/结尾以为就可以了。支持子目录,结果是不行的!。
—————————最后看下图—————
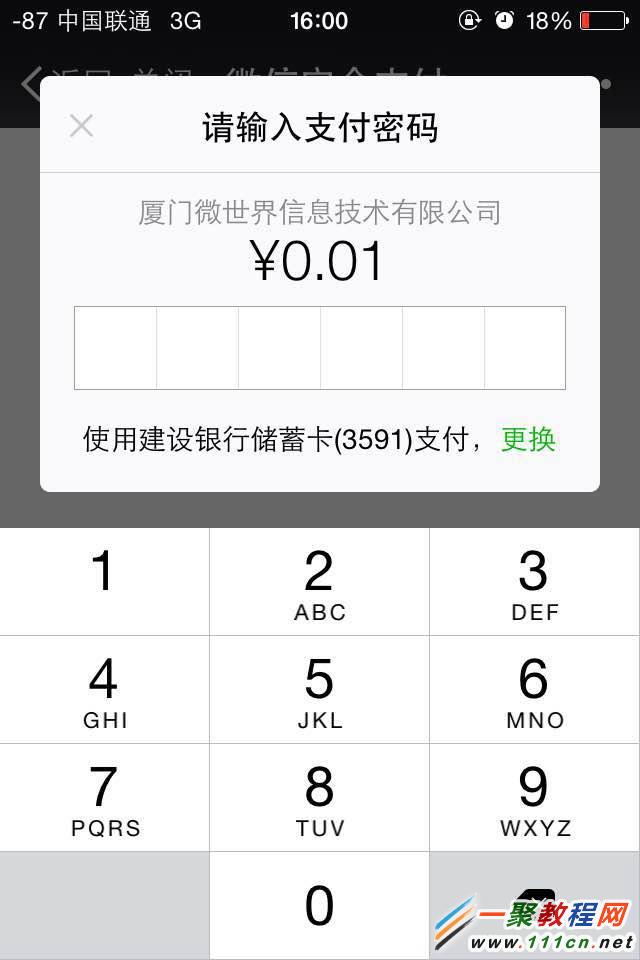
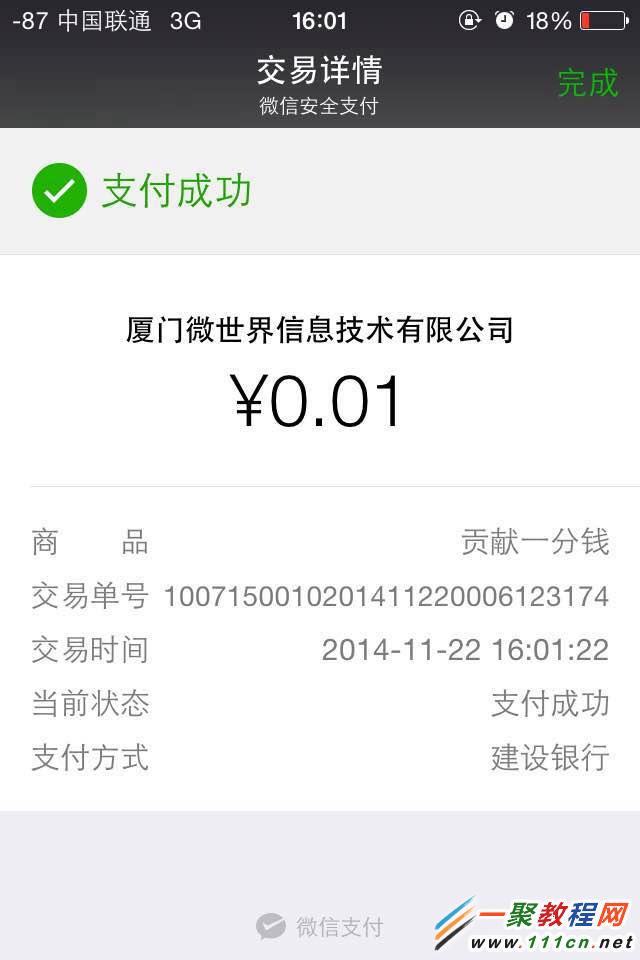

—————–流程中的xmljs——————–
待提交生成与支付订单id:
| 代码如下 | 复制代码 |
| <xml> <openid><![CDATA[ou9dHt0L8qFLI1foP-kj5x1mDWsM]]></openid> <body><![CDATA[贡献一下]]></body> <out_trade_no><![CDATA[wx88888888888888881414411779]]></out_trade_no> <total_fee>1</total_fee> <notify_url><![CDATA[http://shanmao.me/wxpay/notify_url.php]]></notify_url> <trade_type><![CDATA[JSAPI]]></trade_type> <appid><![CDATA[wx8888888888888888]]></appid> <mch_id>10012345</mch_id> <spbill_create_ip><![CDATA[61.50.221.43]]></spbill_create_ip> <nonce_str><![CDATA[60uf9sh6nmppr9azveb2bn7arhy79izk]]></nonce_str> <sign><![CDATA[2D8A96553672D56BB2908CE4B0A23D0F]]></sign> </xml> 提交后返回正确,其中包含了perpay_id: <xml> <return_code><![CDATA[SUCCESS]]></return_code> <return_msg><![CDATA[OK]]></return_msg> <appid><![CDATA[wx8888888888888888]]></appid> <mch_id><![CDATA[10012345]]></mch_id> <nonce_str><![CDATA[Be8YX7gjCdtCT7cr]]></nonce_str> <sign><![CDATA[885B6D84635AE6C020EF753A00C8EEDB]]></sign> <result_code><![CDATA[SUCCESS]]></result_code> <prepay_id><![CDATA[wx201410272009395522657a690389285100]]></prepay_id> <trade_type><![CDATA[JSAPI]]></trade_type> </xml> 生成支付用的js : { "appId": "wx8888888888888888", "timeStamp": "1414411784", "nonceStr": "gbwr71b5no6q6ne18c8up1u7l7he2y75", "package": "prepay_id=wx201410272009395522657a690389285100", "signType": "MD5", "paySign": "9C6747193720F851EB876299D59F6C7D" } 支付成功后返回的通知xml: <xml><appid><![CDATA[wx8888888888]]></appid> <bank_type><![CDATA[CCB_DEBIT]]></bank_type> <fee_type><![CDATA[CNY]]></fee_type> <is_subscribe><![CDATA[Y]]></is_subscribe> <mch_id><![CDATA[1011111]]></mch_id> <nonce_str><![CDATA[38gt0ffgsvfsdfsdfbt1981duv63p7]]></nonce_str> <openid><![CDATA[o4p3SjfdsfdsfdsdCE5Y2XHw4]]></openid> <out_trade_no><![CDATA[wx4b56d1fsdfdsf416643247]]></out_trade_no> <result_code><![CDATA[SUCCESS]]></result_code> <return_code><![CDATA[SUCCESS]]></return_code> <sign><![CDATA[356EfsdfdsfsdsfE69509EDA344]]></sign> <sub_mch_id><![CDATA[10018826]]></sub_mch_id> <time_end><![CDATA[20141122160122]]></time_end> <total_fee>1</total_fee> <trade_type><![CDATA[JSAPI]]></trade_type> <transaction_id><![CDATA[100715001020fsdfsd1220006123174]]></transaction_id> </xml> |
|
这其中的数据我随意了的,大家就参考下格式吧。注意大小写敏感。 在php中GET和POST请求发送有很多方法,一直都没有仔细的去总结过,今天看到一站长分享的GET和POST请求发送几种方法下面整理一下。
无论是畅言还是多说,我都需要从远程抓取文章的评论数,然后存入本地数据库。对于多说,请求的格式如下:
| 代码如下 | 复制代码 |
|
// 获取评论次数,参数是文章ID |
|
对于远程请求,有很多种方法。今天,LZ就搜罗了六种,供大家参考。
1、用file_get_contents 以get方式获取内容:
| 代码如下 | 复制代码 |
| <?php $url='http://www.111cn.net/'; $html = file_get_contents($url); echo $html; ?> |
|
2、用fopen打开url,用get方式获取
| 代码如下 | 复制代码 |
| $fp = fopen($url, 'r'); stream_get_meta_data($fp); while(!feof($fp)) { $result .= fgets($fp, 1024); } echo "url body: $result"; fclose($fp); |
|
3、用file_get_contents 以post方式获取内容:
| 代码如下 | 复制代码 |
| $data = array ('foo' => 'bar'); $data = http_build_query($data); $opts = array ( 'http' => array ( 'method' => 'POST', 'header'=> "Content-type: application/x-www-form-urlencodedrn" . 'Content-Length: ' . strlen($data) . 'rn', 'content' => $data ) ); $context = stream_context_create($opts); $html = file_get_contents('http://localhost/e/admin/test.html', false, $context); echo $html; |
|
4、用fsockopen函数打开url,以get方式获取完整的数据,包括header和body,fsockopen需要 PHP.ini 中 allow_url_fopen 选项开启
| 代码如下 | 复制代码 |
|
function get_url ($url,$cookie=false) |
|
5、用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
| 代码如下 | 复制代码 |
| function HTTP_Post($URL,$data,$cookie, $referrer='') { // parsing the given URL $URL_Info=parse_url($URL); // Building referrer if($referrer=='') // if not given use this script as referrer $referrer='111'; // making string from $data foreach($data as $key=>$value) $values[]='$key='.urlencode($value); $data_string=implode('&',$values); // Find out which port is needed – if not given use standard (=80) if(!isset($URL_Info['port'])) $URL_Info['port']=80; // building POST-request: $request.="POST ".$URL_Info['path']." HTTP/1.1n"; $request.="Host: ".$URL_Info['host']."n"; $request.="Referer: $referern"; $request.="Content-type: application/x-www-form-urlencodedn"; $request.='Content-length: '.strlen($data_string)."n"; $request.='Connection: closen'; $request.='Cookie: $cookien'; $request.='n'; $request.=$data_string.'n'; $fp = fsockopen($URL_Info['host'],$URL_Info['port']); fputs($fp, $request); while(!feof($fp)) { $result .= fgets($fp, 1024); } fclose($fp); return $result; } |
|
6、使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
| 代码如下 | 复制代码 |
|
$ch = curl_init(); |
|
电商网站开发过程中购物车实现是必要的功能,本文为大家介绍php 购物车代码的实现。
原理:cookie存购物车ID,数据库存购物车数据。
| 代码如下 | 复制代码 |
|
<?php //---------------------------------------------------- |
|
相关文章
- 这篇文章主要介绍了源码分析系列之json_encode()如何转化一个对象,对json_encode()感兴趣的同学,可以参考下...2021-04-22
- PHP去除html、css样式、js格式的方法很多,但发现,它们基本都有一个弊端:空格往往清除不了 经过不断的研究,最终找到了一个理想的去除html包括空格css样式、js 的PHP函数。...2013-08-02
- index.php怎么打开?初学者可能不知道如何打开index.php,不会的同学可以参考一下本篇教程 打开编辑:右键->打开方式->经文本方式打开打开运行:首先你要有个支持运行PH...2017-07-06
PHP中func_get_args(),func_get_arg(),func_num_args()的区别
复制代码 代码如下:<?php function jb51(){ print_r(func_get_args()); echo "<br>"; echo func_get_arg(1); echo "<br>"; echo func_num_args(); } jb51("www","j...2013-10-04- 20岁老牌网页程序语言PHP,最快将在10月底释出PHP 7新版,这是十年来的首次大改版,最大特色是在性能上的大突破,能比前一版PHP 5快上一倍,PHP之父Rasmus Lerdorf表示,甚至能比HHVM虚拟机下的PHP程序性能更快。HHVM 是脸书为自...2015-11-24
- 这篇文章主要介绍了PHP编程 SSO详细介绍及简单实例的相关资料,这里介绍了三种模式跨子域单点登陆、完全跨单点域登陆、站群共享身份认证,需要的朋友可以参考下...2017-01-25
- 这篇文章主要介绍了PHP实现创建以太坊钱包转账等功能,对以太坊感兴趣的同学,可以参考下...2021-04-20
利用 Chrome Dev Tools 进行页面性能分析的步骤说明(前端性能优化)
这篇文章主要介绍了利用 Chrome Dev Tools 进行页面性能分析的步骤说明(前端性能优化),本文给大家介绍的非常想详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-02-24- 这篇文章主要介绍了JavaScript提高网站性能优化的建议(二)的相关资料,需要的朋友可以参考下...2016-07-29
- 这篇文章主要为大家详细介绍了php微信公众账号开发之五个坑,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2016-10-02
ThinkPHP使用心得分享-ThinkPHP + Ajax 实现2级联动下拉菜单
首先是数据库的设计。分类表叫cate.我做的是分类数据的二级联动,数据需要的字段有:id,name(中文名),pid(父id). 父id的设置: 若数据没有上一级,则父id为0,若有上级,则父id为上一级的id。数据库有内容后,就可以开始写代码,进...2014-05-31- 这篇文章主要介绍了PHP如何通过date() 函数格式化显示时间,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-11-13
- 这篇文章主要介绍了提升jQuery的性能需要做好的七件事,希望真的帮助大家提升jQuery性能,需要的朋友可以参考下...2016-01-14
- 这篇文章主要介绍了golang与php实现计算两个经纬度之间距离的方法,结合实例形式对比分析了Go语言与php进行经纬度计算的相关数学运算技巧,需要的朋友可以参考下...2016-07-29
- 今天我给大家分享的是在不刷新页面的前提下,使用PHP+jQuery+Ajax实现多图片上传的效果。用户只需要点击选择要上传的图片,然后图片自动上传到服务器上并展示在页面上。...2015-03-15
- 这篇文章主要介绍了PHP正则表达式过滤html标签属性的相关内容,实用性非常,感兴趣的朋友参考下吧...2016-05-06
- 这篇文章主要为大家详细介绍了php构造方法中析构方法在继承中的表现,感兴趣的小伙伴们可以参考一下...2016-04-15
- 这篇文章主要介绍了thinkPHP中多维数组的遍历方法,以简单实例形式分析了thinkPHP中foreach语句的使用技巧,需要的朋友可以参考下...2016-01-12
- 这篇文章主要介绍了PHP如何使用cURL实现Get和Post请求,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-07-11
- php测试性能代码 function microtime_float () { list ($usec, $sec) = explode(" ", microtime()); return ((float) $usec + (float) $sec); } functio...2016-11-25