Java读取PDF中的表格的方法示例
更新时间:2021年10月22日 16:00 点击:2571 作者:E-iceblue
一、概述
本文以Java示例展示读取PDF中的表格的方法。这里导入Spire.PDF for Javah中的jar包,并使用其提供的相关及方法来实现获取表格中的文本内容。下表中整理了本次代码使用到的主要类、方法及解释,供参考:
| 类型 | 描述 |
| PdfDocument Class | Represents a pdf document model. |
| PdfDocument. loadFromFile (string filename) Method | Loads a PDF document. |
| PdfTableExtractor Class | Represents the PDF table extractor. |
| PdfTable Class | Defines a PDF table. |
| PdfTableExtractor. extractTable (int pageIndex) Method | Extracts table from page. |
| PdfTable.getText(int rowIndex,int columnIndex) Method | Gets Text in cell. |
| FileWriter. write() Method | Saves extracted text in table to a .txt file. |
二、环境配置
- IntelliJ IDEA 2018(JDK 1.8.0)
- PDF 测试文档
- PDF Jar包:Spire.PDF for Java Version: 4.10.2
Jar包的两种导入方法:
1. 手动导入
将jar包下载到本地,解压。然后执行如下步骤来手动导入:
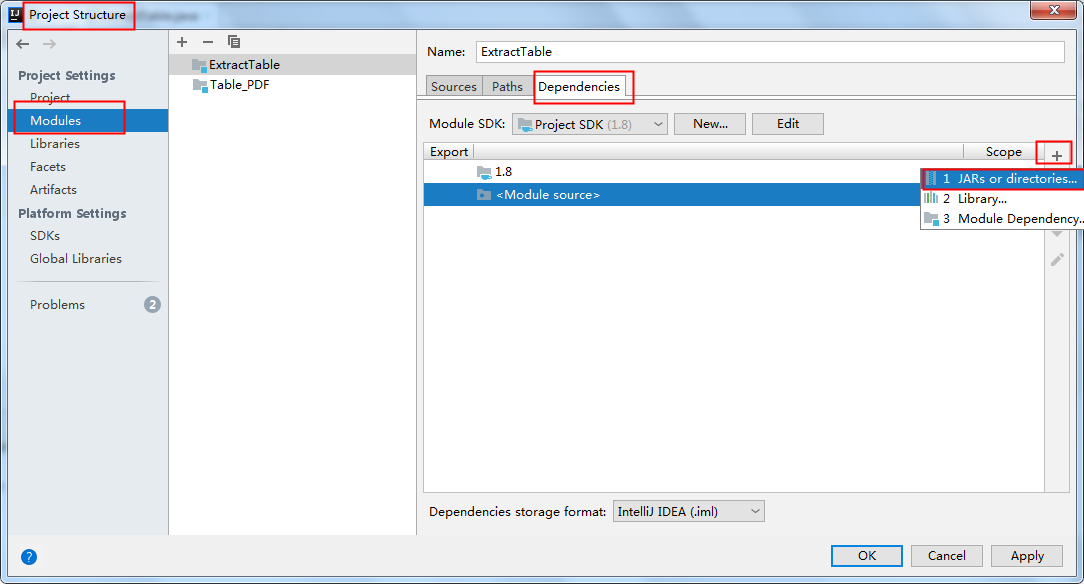
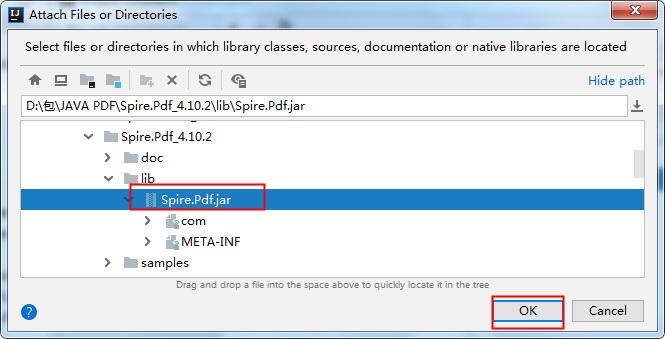
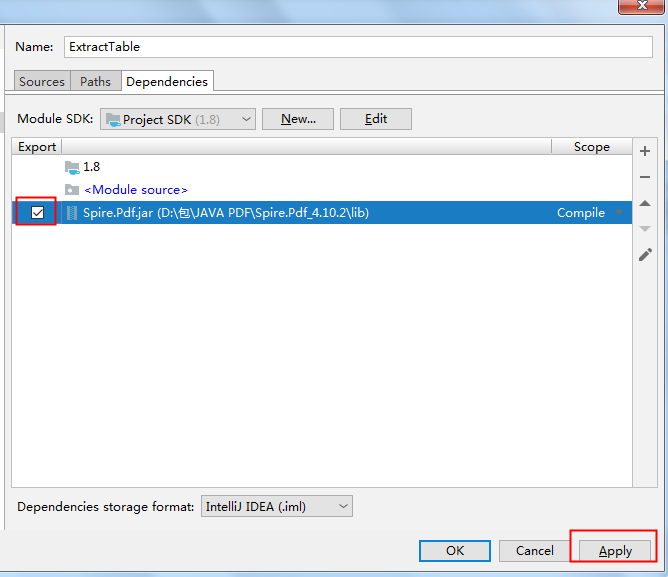
2. Maven仓库下载导入
如果使用maven,需在pom.xml中配置maven路径,指定依赖,如下:
<repositories>
<repository>
<id>com.e-iceblue</id>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>4.10.2</version>
</dependency>
</dependencies>
三、读取PDF中的表格
import com.spire.pdf.*;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTable {
public static void main(String[] args)throws IOException {
//加载PDF文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("test.pdf");
//创建StringBuilder类的实例
StringBuilder builder = new StringBuilder();
//抽取表格
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists ;
for (int page = 0; page < pdf.getPages().getCount(); page++)
{
tableLists = extractor.extractTable(page);
if (tableLists != null && tableLists.length > 0)
{
for (PdfTable table : tableLists)
{
int row = table.getRowCount();
int column = table.getColumnCount();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
String text = table.getText(i, j);
builder.append(text+" ");
}
builder.append("\r\n");
}
}
}
}
//将提取的表格内容写入txt文档
FileWriter fileWriter = new FileWriter("ExtractedTable.txt");
fileWriter.write(builder.toString());
fileWriter.flush();
fileWriter.close();
}
}
表格内容读取结果:
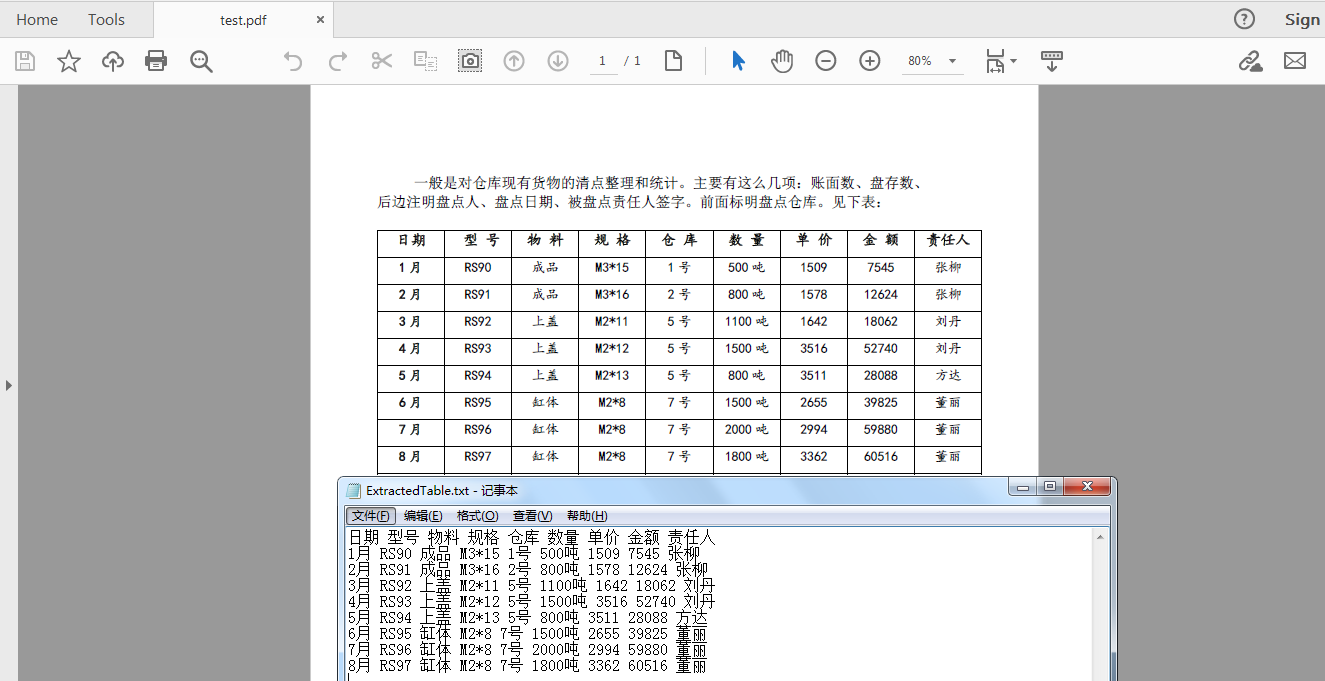
注意事项:
1. 注意使用的PDF Jar包版本为4.10.2,低于此版本的jar包不支持读取表格;
2. 代码中的文件路径为 F:\IDEAProject\Table_PDF\test.pdf 和 F:\IDEAProject\Table_PDF\ExtractedTable.txt , 文件路径可自定义为其他路径。
到此这篇关于Java读取PDF中的表格的方法示例的文章就介绍到这了,更多相关Java读取PDF表格内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
原文出处:https://www.cnblogs.com/Yesi/p/15437619.html
相关文章
- 这篇文章主要介绍了如何利用java语言实现经典《复杂迷宫》游戏,文中采用了swing技术进行了界面化处理,感兴趣的小伙伴可以动手试一试...2022-02-01
java 运行报错has been compiled by a more recent version of the Java Runtime
java 运行报错has been compiled by a more recent version of the Java Runtime (class file version 54.0)...2021-04-01- 这篇文章主要介绍了在java中获取List集合中最大的日期时间操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-15
- 这篇文章主要介绍了C#从数据库读取图片并保存的方法,帮助大家更好的理解和使用c#,感兴趣的朋友可以了解下...2021-01-16
- 这篇文章主要介绍了教你怎么用Java获取国家法定节假日,文中有非常详细的代码示例,对正在学习java的小伙伴们有非常好的帮助,需要的朋友可以参考下...2021-04-23
- 这篇文章主要介绍了Java如何发起http请求的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-31
- 说起C#和Java这两门语言(语法,数据类型 等),个人以为,大概有90%以上的相似,甚至可以认为几乎一样。但是在工作中,我也发现了一些细微的差别...2020-06-25
- 在php中解析xml文档用专门的函数domdocument来处理,把json在php中也有相关的处理函数,我们要把数据xml 数据存到一个数据再用json_encode直接换成json数据就OK了。...2016-11-25
- 这篇文章主要介绍了解决Java处理HTTP请求超时的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-29
- 这篇文章主要介绍了java 判断两个时间段是否重叠的案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-15
- 这篇文章主要介绍了超简洁java实现双色球若干注随机号码生成(实例代码),本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-04-02
- 这篇文章主要介绍了Java生成随机姓名、性别和年龄的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-10-01
java 画pdf用itext调整表格宽度、自定义各个列宽的方法
这篇文章主要介绍了java 画pdf用itext调整表格宽度、自定义各个列宽的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-31- 这篇文章主要介绍了C#实现动态生成表格的方法,是C#程序设计中非常实用的技巧,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了java正则表达式判断前端参数修改表中另一个字段的值,需要的朋友可以参考下...2021-05-07
Java使用ScriptEngine动态执行代码(附Java几种动态执行代码比较)
这篇文章主要介绍了Java使用ScriptEngine动态执行代码,并且分享Java几种动态执行代码比较,需要的朋友可以参考下...2021-04-15- 这篇文章主要介绍了Java开发实现人机猜拳游戏,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-08-03
- 这篇文章主要介绍了Java List集合返回值去掉中括号('[ ]')的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-29
- 这篇文章主要介绍了c# 如何对CSV文件操作,帮助大家更好的理解和学习C#,感兴趣的朋友可以了解下...2020-11-03
Java中lombok的@Builder注解的解析与简单使用详解
这篇文章主要介绍了Java中lombok的@Builder注解的解析与简单使用,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-01-06