SparkSQL使用快速入门
一、SparkSQL的进化之路
1.0以前: Shark
1.1.x开始:SparkSQL(只是测试性的) SQL
1.3.x: SparkSQL(正式版本)+Dataframe
1.5.x: SparkSQL 钨丝计划
1.6.x: SparkSQL+DataFrame+DataSet(测试版本)
2.x:
- SparkSQL+DataFrame+DataSet(正式版本)
- SparkSQL:还有其他的优化
- StructuredStreaming(DataSet)
Spark on Hive和Hive on Spark
- Spark on Hive:Hive只作为储存角色,Spark负责sql解析优化,执行。
- Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
二、认识SparkSQL
2.1 什么是SparkSQL?
spark SQL是spark的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象就是DataFrame。
2.2 SparkSQL的作用
提供一个编程抽象(DataFrame) 并且作为分布式 SQL查询引擎
DataFrame:它可以根据很多源进行构建,包括:结构化的数据文件,hive中的表,外部的关系型数据库,以及RDD
2.3 运行原理
将Spark SQL转化为RDD,然后提交到集群执行
2.4 特点
(1)容易整合
(2)统一的数据访问方式
(3)兼容 Hive
(4)标准的数据连接
2.5 SparkSession
SparkSession是Spark 2.0引如的新概念。SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。
在spark的早期版本中,SparkContext是spark的主要切入点,由于RDD是主要的API,我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。例如,对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于Hive,使用hiveContext。但是随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext和SQLContext。为了向后兼容,SQLContext和HiveContext也被保存下来。
SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
特点:
---- 为用户提供一个统一的切入点使用Spark 各项功能
---- 允许用户通过它调用 DataFrame 和 Dataset 相关 API 来编写程序
---- 减少了用户需要了解的一些概念,可以很容易的与 Spark 进行交互
---- 与 Spark 交互之时不需要显示的创建 SparkConf, SparkContext 以及 SQlContext,这些对象已经封闭在 SparkSession 中
2.6 DataFrames
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。

三、RDD转换成为DataFrame
使用spark1.x版本的方式
测试数据目录:spark/examples/src/main/resources(spark的安装目录里面)
people.txt

3.1通过case class创建DataFrames(反射)
//定义case class,相当于表结构
case class People(var name:String,var age:Int)
object TestDataFrame1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDDToDataFrame").setMaster("local")
val sc = new SparkContext(conf)
val context = new SQLContext(sc)
// 将本地的数据读入 RDD, 并将 RDD 与 case class 关联
val peopleRDD = sc.textFile("E:\\666\\people.txt")
.map(line => People(line.split(",")(0), line.split(",")(1).trim.toInt))
import context.implicits._
// 将RDD 转换成 DataFrames
val df = peopleRDD.toDF
//将DataFrames创建成一个临时的视图
df.createOrReplaceTempView("people")
//使用SQL语句进行查询
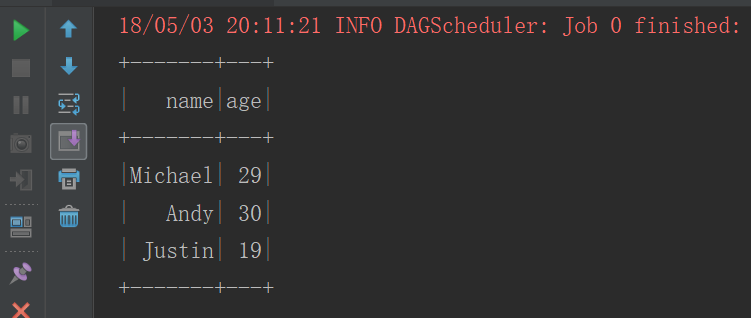
context.sql("select * from people").show()
}
}
运行结果
3.2通过structType创建DataFrames(编程接口)
object TestDataFrame2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val fileRDD = sc.textFile("E:\\666\\people.txt")
// 将 RDD 数据映射成 Row,需要 import org.apache.spark.sql.Row
val rowRDD: RDD[Row] = fileRDD.map(line => {
val fields = line.split(",")
Row(fields(0), fields(1).trim.toInt)
})
// 创建 StructType 来定义结构
val structType: StructType = StructType(
//字段名,字段类型,是否可以为空
StructField("name", StringType, true) ::
StructField("age", IntegerType, true) :: Nil
)
/**
* rows: java.util.List[Row],
* schema: StructType
* */
val df: DataFrame = sqlContext.createDataFrame(rowRDD,structType)
df.createOrReplaceTempView("people")
sqlContext.sql("select * from people").show()
}
}
运行结果

3.3通过 json 文件创建DataFrames
object TestDataFrame3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df: DataFrame = sqlContext.read.json("E:\\666\\people.json")
df.createOrReplaceTempView("people")
sqlContext.sql("select * from people").show()
}
}

四、DataFrame的read和save和savemode
4.1 数据的读取
object TestRead {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//方式一
val df1 = sqlContext.read.json("E:\\666\\people.json")
val df2 = sqlContext.read.parquet("E:\\666\\users.parquet")
//方式二
val df3 = sqlContext.read.format("json").load("E:\\666\\people.json")
val df4 = sqlContext.read.format("parquet").load("E:\\666\\users.parquet")
//方式三,默认是parquet格式
val df5 = sqlContext.load("E:\\666\\users.parquet")
}
}
4.2 数据的保存
object TestSave {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df1 = sqlContext.read.json("E:\\666\\people.json")
//方式一
df1.write.json("E:\\111")
df1.write.parquet("E:\\222")
//方式二
df1.write.format("json").save("E:\\333")
df1.write.format("parquet").save("E:\\444")
//方式三
df1.write.save("E:\\555")
}
}
4.3 数据的保存模式
使用mode
df1.write.format("parquet").mode(SaveMode.Ignore).save("E:\\444")

五、数据源
5.1 数据源只json
参考4.1
5.2 数据源之parquet
参考4.1
5.3 数据源之Mysql
object TestMysql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestMysql").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val url = "jdbc:mysql://192.168.123.102:3306/hivedb"
val table = "dbs"
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","root")
//需要传入Mysql的URL、表明、properties(连接数据库的用户名密码)
val df = sqlContext.read.jdbc(url,table,properties)
df.createOrReplaceTempView("dbs")
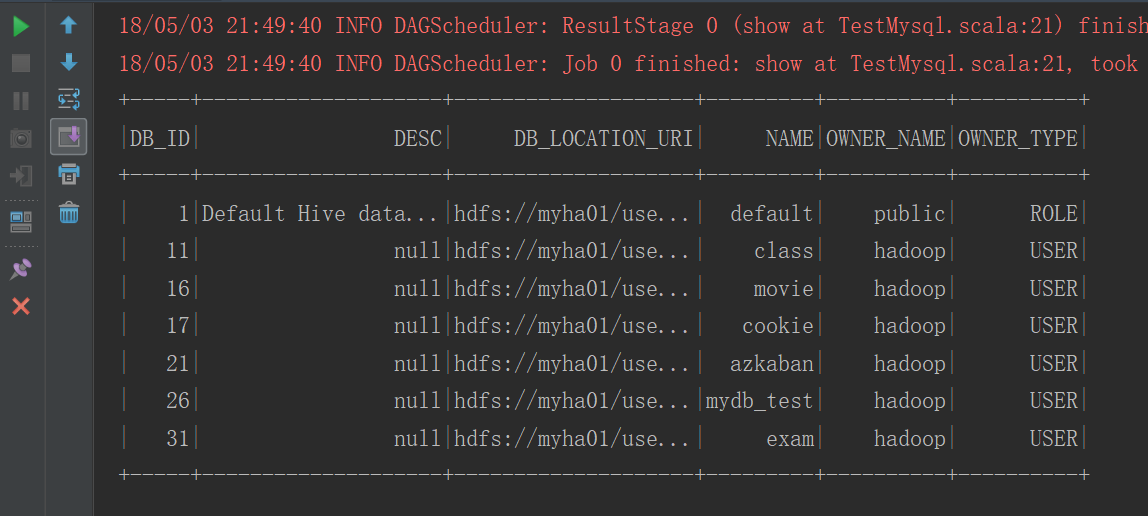
sqlContext.sql("select * from dbs").show()
}
}
运行结果
5.3 数据源之Hive
(1)准备工作
在pom.xml文件中添加依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.0</version>
</dependency>
开发环境则把resource文件夹下添加hive-site.xml文件,集群环境把hive的配置文件要发到$SPARK_HOME/conf目录下

<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
<!-- 如果 mysql 和 hive 在同一个服务器节点,那么请更改 hadoop02 为 localhost -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
</configuration>
(2)测试代码
object TestHive {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName(this.getClass.getSimpleName)
val sc = new SparkContext(conf)
val sqlContext = new HiveContext(sc)
sqlContext.sql("select * from myhive.student").show()
}
}
运行结果

六、SparkSQL 的元数据
1.1元数据的状态
SparkSQL 的元数据的状态有两种:
1、in_memory,用完了元数据也就丢了
2、hive , 通过hive去保存的,也就是说,hive的元数据存在哪儿,它的元数据也就存在哪儿。
换句话说,SparkSQL的数据仓库在建立在Hive之上实现的。我们要用SparkSQL去构建数据仓库的时候,必须依赖于Hive。
2.2Spark-SQL脚本
如果用户直接运行bin/spark-sql命令。会导致我们的元数据有两种状态:
1、in-memory状态:如果SPARK-HOME/conf目录下没有放置hive-site.xml文件,元数据的状态就是in-memory
2、hive状态:如果我们在SPARK-HOME/conf目录下放置了,hive-site.xml文件,那么默认情况下,spark-sql的元数据的状态就是hive.
到此这篇关于SparkSQL使用快速入门的文章就介绍到这了,更多相关SparkSQL使用内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 有时为了网站安全和版权问题,会对自己写的php源码进行加密,在php加密技术上最常用的是zend公司的zend guard 加密软件,现在我们来图文讲解一下。 下面就简单说说如何...2016-11-25
- ps软件是现在很多人都会使用到的,HSL面板在ps软件中又有着非常独特的作用。这次文章就给大家介绍下ps怎么使用HSL面板,还不知道使用方法的下面一起来看看。  ...2017-07-06
- 许多的朋友对于Plesk控制面板应用不是非常的了解特别是英文版的Plesk控制面板,在这里小编整理了一些关于Plesk控制面板常用的使用方案整理,具体如下。 本文基于Linu...2016-10-10
使用insertAfter()方法在现有元素后添加一个新元素
复制代码 代码如下: //在现有元素后添加一个新元素 function insertAfter(newElement, targetElement){ var parent = targetElement.parentNode; if (parent.lastChild == targetElement){ parent.appendChild(newEl...2014-05-31- 大概有如下步骤 新建项目Bejs 新建文件package.json 新建文件Gruntfile.js 命令行执行grunt任务 一、新建项目Bejs源码放在src下,该目录有两个js文件,selector.js和ajax.js。编译后代码放在dest,这个grunt会...2014-06-07
使用percona-toolkit操作MySQL的实用命令小结
1.pt-archiver 功能介绍: 将mysql数据库中表的记录归档到另外一个表或者文件 用法介绍: pt-archiver [OPTION...] --source DSN --where WHERE 这个工具只是归档旧的数据,不会对线上数据的OLTP查询造成太大影响,你可以将...2015-11-24如何使用php脚本给html中引用的js和css路径打上版本号
在搜索引擎中搜索关键字.htaccess 缓存,你可以搜索到很多关于设置网站文件缓存的教程,通过设置可以将css、js等不太经常更新的文件缓存在浏览器端,这样访客每次访问你的网站的时候,浏览器就可以从浏览器的缓存中获取css、...2015-11-24jQuery 1.9使用$.support替代$.browser的使用方法
jQuery 从 1.9 版开始,移除了 $.browser 和 $.browser.version , 取而代之的是 $.support 。 在更新的 2.0 版本中,将不再支持 IE 6/7/8。 以后,如果用户需要支持 IE 6/7/8,只能使用 jQuery 1.9。 如果要全面支持 IE,并混合...2014-05-31安装和使用percona-toolkit来辅助操作MySQL的基本教程
一、percona-toolkit简介 percona-toolkit是一组高级命令行工具的集合,用来执行各种通过手工执行非常复杂和麻烦的mysql和系统任务,这些任务包括: 检查master和slave数据的一致性 有效地对记录进行归档 查找重复的索...2015-11-24- C#注释的一些使用方法浅谈,需要的朋友可以参考一下...2020-06-25
- 一、下载 mysqlsla [root@localhost tmp]# wget http://hackmysql.com/scripts/mysqlsla-2.03.tar.gz--19:45:45-- http://hackmysql.com/scripts/mysqlsla-2.03.tar.gzResolving hackmysql.com... 64.13.232.157Conn...2015-11-24
- 目前,JSON已经成为最流行的数据交换格式之一,各大网站的API几乎都支持它。我写过一篇《数据类型和JSON格式》,探讨它的设计思想。今天,我想总结一下PHP语言对它的支持,这是开发互联网应用程序(特别是编写API)必须了解的知识...2015-10-30
- 无限级分类在开发中经常使用,例如:部门结构、文章分类。无限级分类的难点在于“输出”和“查询”,例如 将文章分类输出为<ul>列表形式; 查找分类A下面所有分类包含的文章。1.实现原理 几种常见的实现方法,各有利弊。其中...2015-10-23
- php类的使用实例教程 <?php /** * Class program for yinghua05-2 * designer :songsong */ class Template { var $tpl_vars; var $tpl_path; var $_deb...2016-11-25
- 前几天在百度知道里面看到有人问PHP中双冒号::的用法,当时给他的回答比较简洁因为手机打字不大方便!今天突然想起来,所以在这里总结一下我遇到的双冒号::在PHP中使用的情况!双冒号操作符即作用域限定操作符Scope Resoluti...2015-11-08
- Promise是异步编程的一种解决方案,在ES6中Promise被列为了正式规范,统一了用法,原生提供了Promise对象。接下来通过本文给大家介绍Promise的介绍及基本用法,感兴趣的朋友一起看看吧...2021-10-21
- 基本思路: 通过使用jquery选择器得到对应表单的jquery对象,然后使用attr方法修改对应的action 示例程序一: 默认情况下,该表单会提交到page_one.html 点击button之后,表单的提交地址就会修改为page_two.html 复制...2014-06-07
- mysqli封装了诸如事务等一些高级操作,同时封装了DB操作过程中的很多可用的方法。应用比较多的地方是 mysqli的事务。...2013-10-02
Postman安装与使用详细教程 附postman离线安装包
这篇文章主要介绍了Postman安装与使用详细教程 附postman离线安装包,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-05- 这篇文章主要介绍了vs2019安装和使用详细图文教程,本文通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-06-25