C语言压缩文件和用MD5算法校验文件完整性的实例教程
使用lzma SDK对7z文件简单解压缩
有时候我们只需要单纯对lzma算法压缩的7z文件进行解压,有时需要在嵌入式设备上解压,使用p7zip虽然支持多种格式,但是不容易裁剪,使用lzma SDK是首选:
可以在这里找到各种版本:http://zh.sourceforge.jp/projects/sfnet_sevenzip/releases/
我下载了4.65版本,这个对文件名编码支持没有9.20的好,中文可能有问题,但是我的需求不需要支持中文文件名,所以足够用了。
解压后先看一下7z这个工程,这个示例只有文件解压操作,仿照就可以写一个更加精简的解压函数:
需要的文件可以参考实例:
修改7zMain.c即可。
我们的目的是写一个函数extract7z,接收参数是7z文件路径,输出文件路径,便可执行全部解压。
主要调用函数:
SRes SzArEx_Open(CSzArEx *p, ILookInStream *inStream, ISzAlloc *allocMain, ISzAlloc *allocTemp); SRes SzAr_Extract( const CSzArEx *p, ILookInStream *inStream, UInt32 fileIndex, UInt32 *blockIndex, Byte **outBuffer, size_t *outBufferSize, size_t *offset, size_t *outSizeProcessed, ISzAlloc *allocMain, ISzAlloc *allocTemp);
我们先在Windows下编译:
完整代码如下:
/* 7zMain.c - Test application for 7z Decoder
*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define LOGD printf
#define LOGE printf
#include "7zCrc.h"
#include "7zFile.h"
#include "7zVersion.h"
#include "7zAlloc.h"
#include "7zExtract.h"
#include "7zIn.h"
int MY_CDECL extract7z(const char* srcFile, const char* dstPath)
{
CFileInStream archiveStream;
CLookToRead lookStream;
CSzArEx db;
SRes res;
ISzAlloc allocImp;
ISzAlloc allocTempImp;
char outPath[1024] = { 0 };
LOGD("7z ANSI-C Decoder " MY_VERSION_COPYRIGHT_DATE "\n");
if (InFile_Open(&archiveStream.file, srcFile)) {//open 7z file
LOGE("can not open input file\n");
return 1;
}
FileInStream_CreateVTable(&archiveStream);
LookToRead_CreateVTable(&lookStream, False);
lookStream.realStream = &archiveStream.s;
LookToRead_Init(&lookStream);
allocImp.Alloc = SzAlloc;
allocImp.Free = SzFree;
allocTempImp.Alloc = SzAllocTemp;
allocTempImp.Free = SzFreeTemp;
CrcGenerateTable();
SzArEx_Init(&db);
res = SzArEx_Open(&db, &lookStream.s, &allocImp, &allocTempImp);
if(res == SZ_OK)
{
Int32 i;
UInt32 blockIndex = 0xFFFFFFFF; /* it can have any value before first call (if outBuffer = 0) */
Byte *outBuffer = 0; /* it must be 0 before first call for each new archive. */
size_t outBufferSize = 0; /* it can have any value before first call (if outBuffer = 0) */
LOGD("Total file/directory count[%d]\n", db.db.NumFiles);
for (i = db.db.NumFiles - 1; i >= 0; i--) {
size_t offset;
size_t outSizeProcessed;
CSzFileItem *f = db.db.Files + i;
strcpy(outPath, dstPath);
strcat(outPath, "/");
strcat(outPath, f->Name);
if (f->IsDir) { //dir
LOGD("dir [%s]\n", outPath);
mkdir(outPath);
continue;
}else{ //file
LOGD("file [%s]\n", outPath);
res = SzAr_Extract(&db, &lookStream.s, i, &blockIndex,
&outBuffer, &outBufferSize, &offset, &outSizeProcessed,
&allocImp, &allocTempImp);
if (res != SZ_OK){
break;
}else{
CSzFile outFile;
size_t processedSize;
if (OutFile_Open(&outFile, outPath)) {
LOGE("can not open output file\n");
res = SZ_ERROR_FAIL;
break;
}
processedSize = outSizeProcessed;
if (File_Write(&outFile, outBuffer + offset, &processedSize)
!= 0 || processedSize != outSizeProcessed) {
LOGE("can not write output file\n");
res = SZ_ERROR_FAIL;
break;
}
if (File_Close(&outFile)) {
LOGE("can not close output file\n");
res = SZ_ERROR_FAIL;
break;
}
}
}
}
IAlloc_Free(&allocImp, outBuffer);
}
SzArEx_Free(&db, &allocImp);
File_Close(&archiveStream.file);
if (res == SZ_OK)
{
LOGD("Everything is Ok\n");
return 0;
}
if (res == SZ_ERROR_UNSUPPORTED
)
LOGE("decoder doesn't support this archive\n");
else if (res == SZ_ERROR_MEM
)
LOGE("can not allocate memory\n");
else if (res == SZ_ERROR_CRC
)
LOGE("CRC error\n");
else
LOGE("ERROR #%d\n", res);
return 1;
}
int main(int numargs, char *args[])
{
return extract7z(args[1], args[2]);
}
我用的是Eclipse,使用Mingw编译。

执行效果,能正确解压。
这样的解压只能适用简单的解压,不支持加密,参数2的输出文件路径中的所有文件夹都必须存在,压缩包中文件夹不需要存在,解压时会自动创建。
压缩包中的文件夹不能为中文,否则乱码。
使用MD5算法验证文件完整性或密码正确性
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),主流编程语言普遍已有MD5实现。
将数据(如汉字)运算为另一固定长度值,是杂凑算法的基础原理,MD5的前身有MD2、MD3和MD4。
MD5的作用是让大容量信息在用数字签名软件签署私人密钥前被"压缩"成一种保密的格式(就是把一个任意长度的字节串变换成一定长的十六进制数字串)。
MD5在实际应用中通常有两种用法,一种是计算一个字符串的MD5值,常用于密码相关的操作;另一种是用于计算一个文件的MD5值,一般用于网络传输中验证文件是否出错。
下面是C语言的MD5计算程序,来自Stardict,网上流行的代码都大同小异:
md5.h
#ifndef MD5_H
#define MD5_H
#ifdef __cplusplus
extern "C"
{
#endif /* __cplusplus */
#ifdef HAVE_CONFIG_H
# include "config.h"
#endif
#ifdef HAVE_STDINT_H
#include <stdint.h>
typedef uint32_t uint32;
#else
/* A.Leo.: this wont work on 16 bits platforms ;) */
typedef unsigned uint32;
#endif
#define MD5_FILE_BUFFER_LEN 1024
struct MD5Context {
uint32 buf[4];
uint32 bits[2];
unsigned char in[64];
};
void MD5Init(struct MD5Context *context);
void MD5Update(struct MD5Context *context, unsigned char const *buf,
unsigned len);
void MD5Final(unsigned char digest[16], struct MD5Context *context);
void MD5Transform(uint32 buf[4], uint32 const in[16]);
int getBytesMD5(const unsigned char* src, unsigned int length, char* md5);
int getStringMD5(const char* src, char* md5);
int getFileMD5(const char* path, char* md5);
/*
* This is needed to make RSAREF happy on some MS-DOS compilers.
*/
typedef struct MD5Context MD5_CTX;
#ifdef __cplusplus
}
#endif /* __cplusplus */
#endif /* !MD5_H */
源文件:
md5.c
#include <string.h> /* for memcpy() */
#include <stdio.h>
#include "md5.h"
#ifndef HIGHFIRST
#define byteReverse(buf, len) /* Nothing */
#else
void byteReverse(unsigned char *buf, unsigned longs);
#ifndef ASM_MD5
/*
* Note: this code is harmless on little-endian machines.
*/
void byteReverse(unsigned char *buf, unsigned longs)
{
uint32 t;
do {
t = (uint32) ((unsigned) buf[3] << 8 | buf[2]) << 16 |
((unsigned) buf[1] << 8 | buf[0]);
*(uint32 *) buf = t;
buf += 4;
}while (--longs);
}
#endif
#endif
static void putu32(uint32 data, unsigned char *addr) {
addr[0] = (unsigned char) data;
addr[1] = (unsigned char) (data >> 8);
addr[2] = (unsigned char) (data >> 16);
addr[3] = (unsigned char) (data >> 24);
}
/*
* Start MD5 accumulation. Set bit count to 0 and buffer to mysterious
* initialization constants.
*/
void MD5Init(struct MD5Context *ctx) {
ctx->buf[0] = 0x67452301;
ctx->buf[1] = 0xefcdab89;
ctx->buf[2] = 0x98badcfe;
ctx->buf[3] = 0x10325476;
ctx->bits[0] = 0;
ctx->bits[1] = 0;
}
/*
* Update context to reflect the concatenation of another buffer full
* of bytes.
*/
void MD5Update(struct MD5Context *ctx, unsigned char const *buf, unsigned len) {
uint32 t;
/* Update bitcount */
t = ctx->bits[0];
if ((ctx->bits[0] = t + ((uint32) len << 3)) < t)
ctx->bits[1]++; /* Carry from low to high */
ctx->bits[1] += len >> 29;
t = (t >> 3) & 0x3f; /* Bytes already in shsInfo->data */
/* Handle any leading odd-sized chunks */
if (t) {
unsigned char *p = (unsigned char *) ctx->in + t;
t = 64 - t;
if (len < t) {
memcpy(p, buf, len);
return;
}
memcpy(p, buf, t);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
buf += t;
len -= t;
}
/* Process data in 64-byte chunks */
while (len >= 64) {
memcpy(ctx->in, buf, 64);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
buf += 64;
len -= 64;
}
/* Handle any remaining bytes of data. */
memcpy(ctx->in, buf, len);
}
/*
* Final wrapup - pad to 64-byte boundary with the bit pattern
* 1 0* (64-bit count of bits processed, MSB-first)
*/
void MD5Final(unsigned char digest[16], struct MD5Context *ctx) {
unsigned count;
unsigned char *p;
/* Compute number of bytes mod 64 */
count = (ctx->bits[0] >> 3) & 0x3F;
/* Set the first char of padding to 0x80. This is safe since there is
always at least one byte free */
p = ctx->in + count;
*p++ = 0x80;
/* Bytes of padding needed to make 64 bytes */
count = 64 - 1 - count;
/* Pad out to 56 mod 64 */
if (count < 8) {
/* Two lots of padding: Pad the first block to 64 bytes */
memset(p, 0, count);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
/* Now fill the next block with 56 bytes */
memset(ctx->in, 0, 56);
} else {
/* Pad block to 56 bytes */
memset(p, 0, count - 8);
} byteReverse(ctx->in, 14);
/* Append length in bits and transform */
//((uint32 *) ctx->in)[14] = ctx->bits[0];
//((uint32 *) ctx->in)[15] = ctx->bits[1];
putu32(ctx->bits[0], ctx->in + 56);
putu32(ctx->bits[1], ctx->in + 60);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
byteReverse((unsigned char *) ctx->buf, 4);
memcpy(digest, ctx->buf, 16);
memset(ctx, 0, sizeof(*ctx)); /* In case it's sensitive */
}
#ifndef ASM_MD5
/* The four core functions - F1 is optimized somewhat */
/* #define F1(x, y, z) (x & y | ~x & z) */
#define F1(x, y, z) (z ^ (x & (y ^ z)))
#define F2(x, y, z) F1(z, x, y)
#define F3(x, y, z) (x ^ y ^ z)
#define F4(x, y, z) (y ^ (x | ~z))
/* This is the central step in the MD5 algorithm. */
#define MD5STEP(f, w, x, y, z, data, s) \
( w += f(x, y, z) + data, w = w<<s | w>>(32-s), w += x )
/*
* The core of the MD5 algorithm, this alters an existing MD5 hash to
* reflect the addition of 16 longwords of new data. MD5Update blocks
* the data and converts bytes into longwords for this routine.
*/
void MD5Transform(uint32 buf[4], uint32 const in[16]) {
register uint32 a, b, c, d;
a = buf[0];
b = buf[1];
c = buf[2];
d = buf[3];
MD5STEP(F1, a, b, c, d, in[0] + 0xd76aa478, 7);
MD5STEP(F1, d, a, b, c, in[1] + 0xe8c7b756, 12);
MD5STEP(F1, c, d, a, b, in[2] + 0x242070db, 17);
MD5STEP(F1, b, c, d, a, in[3] + 0xc1bdceee, 22);
MD5STEP(F1, a, b, c, d, in[4] + 0xf57c0faf, 7);
MD5STEP(F1, d, a, b, c, in[5] + 0x4787c62a, 12);
MD5STEP(F1, c, d, a, b, in[6] + 0xa8304613, 17);
MD5STEP(F1, b, c, d, a, in[7] + 0xfd469501, 22);
MD5STEP(F1, a, b, c, d, in[8] + 0x698098d8, 7);
MD5STEP(F1, d, a, b, c, in[9] + 0x8b44f7af, 12);
MD5STEP(F1, c, d, a, b, in[10] + 0xffff5bb1, 17);
MD5STEP(F1, b, c, d, a, in[11] + 0x895cd7be, 22);
MD5STEP(F1, a, b, c, d, in[12] + 0x6b901122, 7);
MD5STEP(F1, d, a, b, c, in[13] + 0xfd987193, 12);
MD5STEP(F1, c, d, a, b, in[14] + 0xa679438e, 17);
MD5STEP(F1, b, c, d, a, in[15] + 0x49b40821, 22);
MD5STEP(F2, a, b, c, d, in[1] + 0xf61e2562, 5);
MD5STEP(F2, d, a, b, c, in[6] + 0xc040b340, 9);
MD5STEP(F2, c, d, a, b, in[11] + 0x265e5a51, 14);
MD5STEP(F2, b, c, d, a, in[0] + 0xe9b6c7aa, 20);
MD5STEP(F2, a, b, c, d, in[5] + 0xd62f105d, 5);
MD5STEP(F2, d, a, b, c, in[10] + 0x02441453, 9);
MD5STEP(F2, c, d, a, b, in[15] + 0xd8a1e681, 14);
MD5STEP(F2, b, c, d, a, in[4] + 0xe7d3fbc8, 20);
MD5STEP(F2, a, b, c, d, in[9] + 0x21e1cde6, 5);
MD5STEP(F2, d, a, b, c, in[14] + 0xc33707d6, 9);
MD5STEP(F2, c, d, a, b, in[3] + 0xf4d50d87, 14);
MD5STEP(F2, b, c, d, a, in[8] + 0x455a14ed, 20);
MD5STEP(F2, a, b, c, d, in[13] + 0xa9e3e905, 5);
MD5STEP(F2, d, a, b, c, in[2] + 0xfcefa3f8, 9);
MD5STEP(F2, c, d, a, b, in[7] + 0x676f02d9, 14);
MD5STEP(F2, b, c, d, a, in[12] + 0x8d2a4c8a, 20);
MD5STEP(F3, a, b, c, d, in[5] + 0xfffa3942, 4);
MD5STEP(F3, d, a, b, c, in[8] + 0x8771f681, 11);
MD5STEP(F3, c, d, a, b, in[11] + 0x6d9d6122, 16);
MD5STEP(F3, b, c, d, a, in[14] + 0xfde5380c, 23);
MD5STEP(F3, a, b, c, d, in[1] + 0xa4beea44, 4);
MD5STEP(F3, d, a, b, c, in[4] + 0x4bdecfa9, 11);
MD5STEP(F3, c, d, a, b, in[7] + 0xf6bb4b60, 16);
MD5STEP(F3, b, c, d, a, in[10] + 0xbebfbc70, 23);
MD5STEP(F3, a, b, c, d, in[13] + 0x289b7ec6, 4);
MD5STEP(F3, d, a, b, c, in[0] + 0xeaa127fa, 11);
MD5STEP(F3, c, d, a, b, in[3] + 0xd4ef3085, 16);
MD5STEP(F3, b, c, d, a, in[6] + 0x04881d05, 23);
MD5STEP(F3, a, b, c, d, in[9] + 0xd9d4d039, 4);
MD5STEP(F3, d, a, b, c, in[12] + 0xe6db99e5, 11);
MD5STEP(F3, c, d, a, b, in[15] + 0x1fa27cf8, 16);
MD5STEP(F3, b, c, d, a, in[2] + 0xc4ac5665, 23);
MD5STEP(F4, a, b, c, d, in[0] + 0xf4292244, 6);
MD5STEP(F4, d, a, b, c, in[7] + 0x432aff97, 10);
MD5STEP(F4, c, d, a, b, in[14] + 0xab9423a7, 15);
MD5STEP(F4, b, c, d, a, in[5] + 0xfc93a039, 21);
MD5STEP(F4, a, b, c, d, in[12] + 0x655b59c3, 6);
MD5STEP(F4, d, a, b, c, in[3] + 0x8f0ccc92, 10);
MD5STEP(F4, c, d, a, b, in[10] + 0xffeff47d, 15);
MD5STEP(F4, b, c, d, a, in[1] + 0x85845dd1, 21);
MD5STEP(F4, a, b, c, d, in[8] + 0x6fa87e4f, 6);
MD5STEP(F4, d, a, b, c, in[15] + 0xfe2ce6e0, 10);
MD5STEP(F4, c, d, a, b, in[6] + 0xa3014314, 15);
MD5STEP(F4, b, c, d, a, in[13] + 0x4e0811a1, 21);
MD5STEP(F4, a, b, c, d, in[4] + 0xf7537e82, 6);
MD5STEP(F4, d, a, b, c, in[11] + 0xbd3af235, 10);
MD5STEP(F4, c, d, a, b, in[2] + 0x2ad7d2bb, 15);
MD5STEP(F4, b, c, d, a, in[9] + 0xeb86d391, 21);
buf[0] += a;
buf[1] += b;
buf[2] += c;
buf[3] += d;
}
/*
* get MD5 of a byte buffer
*/
int getBytesMD5(const unsigned char* src, unsigned int length, char* md5) {
unsigned char i = 0;
unsigned char md5Bytes[16] = { 0 };
MD5_CTX context;
if (src == NULL || md5 == NULL)
{
return -1;
}
MD5Init(&context);
MD5Update(&context, src, length);
MD5Final(md5Bytes, &context);
for (i = 0; i < 16; i++) {
sprintf(md5, "%02X", md5Bytes[i]);
md5 += 2;
}
*md5 = '\0';
return 0;
}
/*
* get MD5 for a string
*/
int getStringMD5(const char* src, char* md5) {
return getBytesMD5((unsigned char*) src, strlen((char*) src), md5);
}
/**
* get MD5 of a file
*/
int getFileMD5(const char* path, char* md5) {
FILE* fp = NULL;
unsigned char buffer[MD5_FILE_BUFFER_LEN] = { 0 };
int count = 0;
MD5_CTX context;
unsigned char md5Bytes[16] = { 0 };
int i;
if (path == NULL || md5 == NULL) {
return -1;
}
fp = fopen(path, "rb");
if (fp == NULL) {
return -1;
}
MD5Init(&context);
while ((count = fread(buffer, 1, MD5_FILE_BUFFER_LEN, fp)) > 0) {
MD5Update(&context, buffer, count);
}
MD5Final(md5Bytes, &context);
for (i = 0; i < 16; i++) {
sprintf(md5, "%02X", md5Bytes[i]);
md5 += 2;
}
*md5 = '\0';
return 0;
}
#endif
下面是调用函数计算MD5的代码:
main.c
#include <stdio.h>
#include <string.h>
#include "md5.h"
int main(int c, char** v){
char buffer[128];
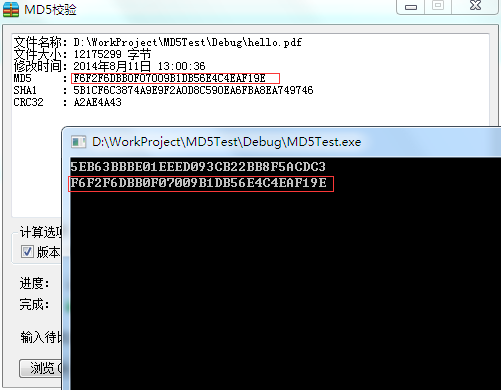
getStringMD5("hello world", buffer);
printf("%s\n", buffer);
getFileMD5("hello.pdf", buffer);
printf("%s\n", buffer);
return 0;
}
计算无误:
相关文章
- 这篇文章主要为大家详细介绍了C语言实现放烟花的程序,有音乐播放,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-23
- 下面小编来给大家演示几个php操作zip文件的实例,我们可以读取zip包中指定文件与删除zip包中指定文件,下面来给大这介绍一下。 从zip压缩文件中提取文件 代...2016-11-25
- 本篇文章主要介绍C语言中char的知识,并附有代码实例,以便大家在学习的时候更好的理解,有需要的可以看一下...2020-04-25
Jupyter Notebook读取csv文件出现的问题及解决
这篇文章主要介绍了JupyterNotebook读取csv文件出现的问题及解决,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2023-01-06- 这篇文章主要介绍了详解如何将c语言文件打包成exe可执行程序,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-25
- 有时我们接受或下载到的PSD文件打开是空白的,那么我们要如何来解决这个 问题了,下面一聚教程小伙伴就为各位介绍Photoshop打开PSD文件空白解决办法。 1、如我们打开...2016-09-14
- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- 这篇文章主要介绍了C#实现HTTP下载文件的方法,包括了HTTP通信的创建、本地文件的写入等,非常具有实用价值,需要的朋友可以参考下...2020-06-25
- 这篇文章主要为大家详细介绍了SpringBoot实现excel文件生成和下载,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-09
- C#使用System.IO中的文件操作方法在Windows系统中处理本地文件相当顺手,这里我们还总结了在Oracle中保存文件的方法,嗯,接下来就来看看整理的C#操作本地文件及保存文件到数据库的基本方法总结...2020-06-25
- 这篇文章主要介绍了Go语言压缩和解压缩tar.gz文件的方法,实例分析了使用Go语言压缩文件与解压文件的技巧,具有一定参考借鉴价值,需要的朋友可以参考下...2020-05-03
php无刷新利用iframe实现页面无刷新上传文件(1/2)
利用form表单的target属性和iframe 一、上传文件的一个php教程方法。 该方法接受一个$file参数,该参数为从客户端获取的$_files变量,返回重新命名后的文件名,如果上传失...2016-11-25- 要替换字符串中的内容我们只要利用php相关函数,如strstr,str_replace,正则表达式了,那么我们要替换目录所有文件的内容就需要先遍历目录再打开文件再利用上面讲的函数替...2016-11-25
- 又码了一个周末的代码,这次在做一些关于文件上传的东西。(PHP UPLOAD)小有收获项目是一个BT种子列表,用户有权限上传自己的种子,然后配合BT TRACK服务器把种子的信息写出来...2016-11-25
- 今天小编在这里就来给photoshop的这一款软件的使用者们来说下AI源文件转photoshop图像变模糊问题的解决教程,各位想知道具体解决方法的使用者们,那么下面就快来跟着小编...2016-09-14
- 步骤:Window -> PHP -> Editor -> Templates,这里可以设置(增、删、改、导入等)管理你的模板。新建文件注释、函数注释、代码块等模板的实例新建模板,分别输入Name、Description、Patterna)文件注释Name: 3cfileDescriptio...2013-10-04
- 这篇文章主要介绍了C++万能库头文件在vs中的安装步骤(图文),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-23
- 本篇文章主要说明的是与php文件上传的相关配置的知识点。PHP文件上传功能配置主要涉及php.ini配置文件中的upload_tmp_dir、upload_max_filesize、post_max_size等选项,下面一一说明。打开php.ini配置文件找到File Upl...2015-10-21
ant design中upload组件上传大文件,显示进度条进度的实例
这篇文章主要介绍了ant design中upload组件上传大文件,显示进度条进度的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-10-29- 这篇文章主要介绍了C#使用StreamWriter写入文件的方法,涉及C#中StreamWriter类操作文件的相关技巧,需要的朋友可以参考下...2020-06-25